
In this post, we explore how reranking methods like RRF, min-max normalization, L2, and atan boost the performance of hybrid search systems by combining semantic and lexical approaches.

In an age of information overload, the relevance of search results has never been more important. Users don’t just want answers—they want the right answers, fast. As hybrid search systems become more common, combining both keyword and semantic models, reranking is key to delivering the most relevant results.
This article dives into reranking techniques such as Reciprocal Rank Fusion (RRF) and score normalization methods like min-max, L2, and atan—tools that refine and optimize search result quality across multiple systems.
You’ll also gain practical insights on how to implement custom reranking methods within Elasticsearch.
Hybrid search blends traditional lexical search (keyword-based) with semantic search (context and intent-driven). Each method brings unique strengths:
-Lexical Search: Precise keyword matching, fast indexing, but limited understanding of context.
-Semantic Search: Uses machine learning models to understand meaning and user intent, making results smarter and more intuitive.
Hybrid systems run both types of searches and then merge their outputs. That’s where reranking comes in—to organize the combined results into a cohesive and relevant list.
When hybrid search systems return results from different sources, these outputs often differ in scoring methods, ranking logic, and precision. Simply merging them won’t do.
Reranking addresses this by:
This technique is especially effective in Retrieval-Augmented Generation (RAG), where the accuracy of the language model’s response depends heavily on the relevance of the retrieved documents. By ensuring better alignment between the query and the supporting content, reranking leads to more precise and contextually appropriate answers.
One of the most efficient reranking methods is Reciprocal Rank Fusion (RRF). It’s score-agnostic and instead focuses on rank positions.

R: Set of ranked result lists (e.g., lexical and semantic).r(d): Position of document d in ranking r.k: A smoothing constant (usually 60).One of the key strengths of Reciprocal Rank Fusion (RRF) lies in its simplicity and robustness. Unlike more complex score-combination techniques, RRF operates purely on the position of a document in each result list, making it both easy to implement and remarkably effective in practice.
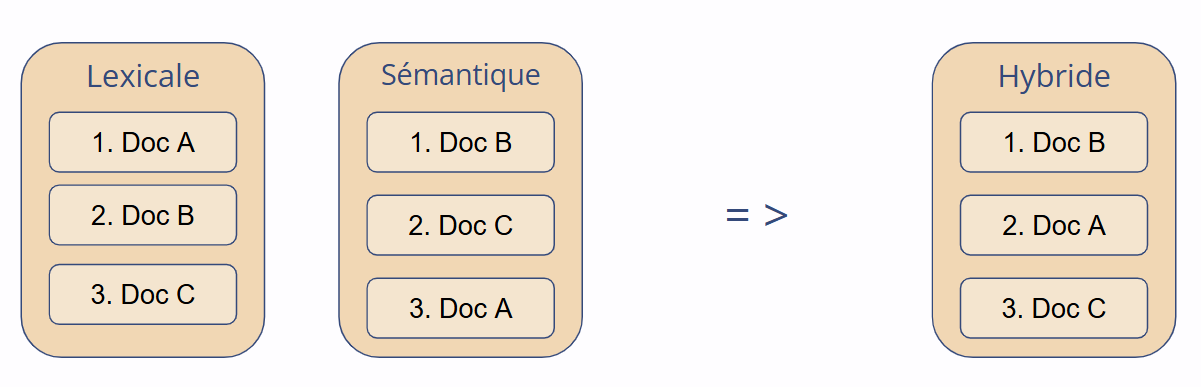
Because RRF doesn’t rely on raw scores, it sidesteps the challenge of score normalization entirely. This makes it especially attractive in hybrid search setups, where lexical and semantic engines produce scores on very different scales. There’s no need to calibrate or align these scores—RRF focuses solely on ranks.
Perhaps most importantly, RRF rewards consistency. Documents that appear in multiple result sets—even if they’re not at the very top—are boosted higher in the final ranking. This reflects a kind of “consensus relevance”: if different retrieval methods independently find the same document valuable, it’s likely to be truly relevant to the user’s query. In this way, RRF elegantly combines diversity with agreement, producing ranked lists that are both comprehensive and coherent.
If you want to combine raw scores instead of ranks, you’ll face a challenge: different systems use different scoring scales.
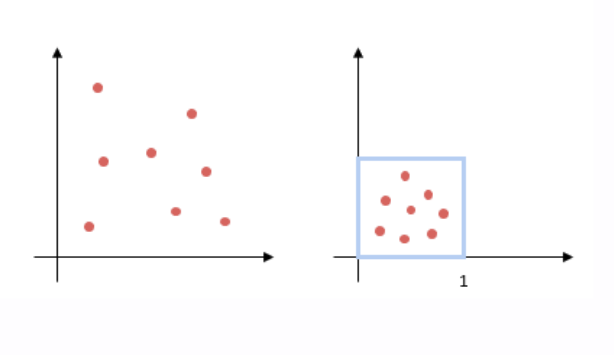
Here’s how normalization helps: score normalization offers a way to bring these diverse scales into alignment, allowing for fair comparison and effective reranking. Several techniques are commonly used, each with its strengths and caveats.
The Min-Max normalization method is perhaps the most straightforward. It linearly scales scores so they fall within a common [0,1] interval. This makes comparison easier and preserves the relative distribution of values.
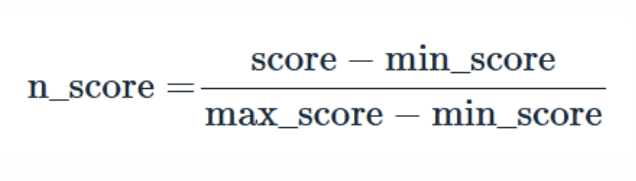
Another practical advantage of min-max normalization is that it’s easy to implement within Elasticsearch. While it’s not natively supported, a simple script-based workaround can achieve the desired effect. This is typically done through a two-step approach:
Here an exemple of a scripted query using min-max (step 2):
{
"from": 0,
"size": 10,
"knn": {
"k": 1000,
"num_candidates": 1500.0,
"field": "vector",
"boost": 0.5,
"query_vector":[0.3, 0.6, 0.1]
},
"query": {
"script_score": {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "The sound of space",
"fields": "text.lang"
}
}
]
}
},
"script": {
"source": "((_score) / (params.max )) * params.boost;",
"params": {
"max": 10, // to retrieve
"boost": 0.5
}
}
}
}
}
Here we assume the min-score is equal to zero and the max-score equal to 10.
This method allows for effective score alignment, making it much easier to combine lexical and semantic results in a meaningful way.
L2 normalization offers an alternative approach to min-max when it comes to scaling scores.

Implementing this method is a bit more complex and, like min-max, requires two steps:
This method can be computationally expensive, as you have to gather all the scores and perform a sum of their squares. For this reason, we won’t further discuss about its implementation.
Atan normalization takes a more nonlinear approach to scaling scores, using the arctangent function to smooth out extreme values. The formula for this transformation looks like this:
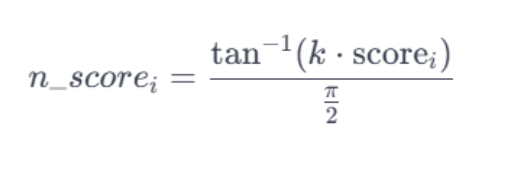
Atan is absolutely the easiest to implement, since doesn’t require multiple steps. Here a scripted query that implement this method:
{
"from": 0,
"size": 10,
"knn": {
"k": 1000,
"num_candidates": 1500.0,
"field": "vector",
"boost": 0.5,
"query_vector":[0.3, 0.6, 0.1]
},
"query": {
"script_score": {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "A tennis player winning his match",
"fields": "text.lang"
}
}
]
}
},
"script": {
"source": "(Math.atan(_score) / ( Math.PI/2)) * params.boost;",
"params": {
"boost": 1
}
}
}
}
}
However, like any normalization method, Atan comes with its trade-offs. Since the distribution of scores is altered, the normalized values may not fully reflect their original importance when combined.
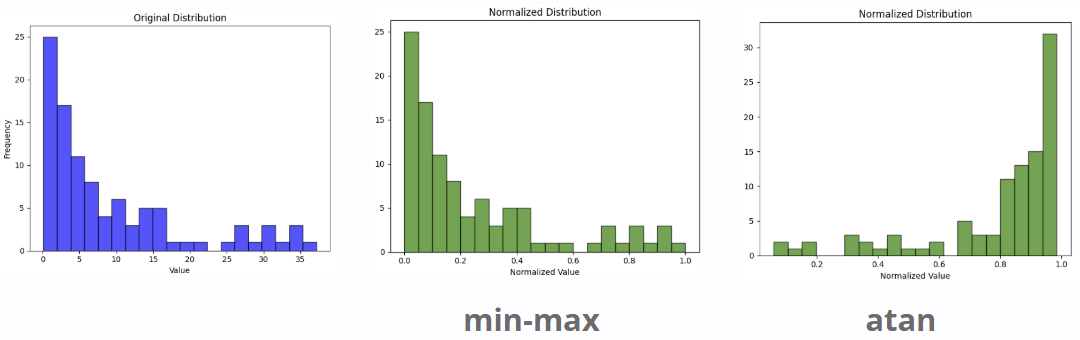
Specifically, as you can see in the image, lower scores are often normalized to higher values, which can lead to a bias toward the lexical part, potentially overemphasizing it in the final ranking.
As hybrid search cements itself as the new standard, reranking plays a critical role in refining, unifying, and elevating search results. Whether through RRF to merge rankings or through score normalization to blend outputs meaningfully, reranking ensures that the most relevant results rise to the top—delivering a smarter, more intuitive search experience and ultimately leading to more satisfied users.
Choosing the right approach must be tailored to specific user needs and validated through rigorous relevance evaluation. As experts in the field, Adelean is here to guide you toward the most effective solution.