
At Haystack US, the search and relevance community came together to explore how AI and LLMs are reshaping the way we search. Let's discover this year's hot topics!

Every year since 2018, Haystack US brings together researchers, engineers, and product minds working at the edge of what search technology can do.
Organised by OpenSource Connections and held in the charming town of Charlottesville, Virginia, this two-day conference offered a unique space for the search and relevance community to connect. From search relevance evaluation using synthetic raters, to the rise of ever faster, effective and cheaper LLMs, to the importance of understanding user behaviour, the topics of conversation felt current, grounded, and most importantly shaped by people doing the actual work.
This year, the Adelean team participated with a talk by Amine Gani and Roudy Khoury titled Behind the hype: managing billion-scale embeddings in Elasticsearch and OpenSearch. Their session revolved around semantic search and how to handle it effectively in a real-world scenario with billions of embeddings. The focus was on tools and techniques to optimise costs without compromising on performance and accuracy.

In case you missed it, you will be able to watch this and all other conference talks on the OpenSource Connections YouTube channel in a few weeks! In the meantime, let’s get an in-depth idea of what this year’s edition has been about.
One of the most recurring conversations at Haystack this year was around a deceptively simple question: who gets to decide what a “good” search result is? With systems becoming more complex and data growing by the terabyte, traditional evaluation methods, heavily reliant on domain experts, are hitting their limits in terms of cost and speed. This is where synthetic raters come into play.
Two talks approached this challenge from complementary angles. Gurion Marks’ Judge Moody’s talk proposed using large language models as relevance judges. Give one of these LLM judges a specific role (like a finance expert reviewing a junior intern’s work), clear criteria, and some examples, and it can evaluate semantic relevance with impressive speed, at a fraction of the cost of human reviewers. One promising direction is combining multiple judges, each optimized for a different evaluation angle, though this practice poses the challenge of increased cost and complexity.
Doug Rosenoff’s talk helped widen the lens, reflecting on the application of synthetic raters in the editorial field. It presented a testing framework designed to perform repeatable and tunable judging. The system supports pre and post-human evaluation, makes it easy to compare configurations, and calculates detailed metrics like inter-rater reliability, precision, and correlation coefficients between bots and humans.
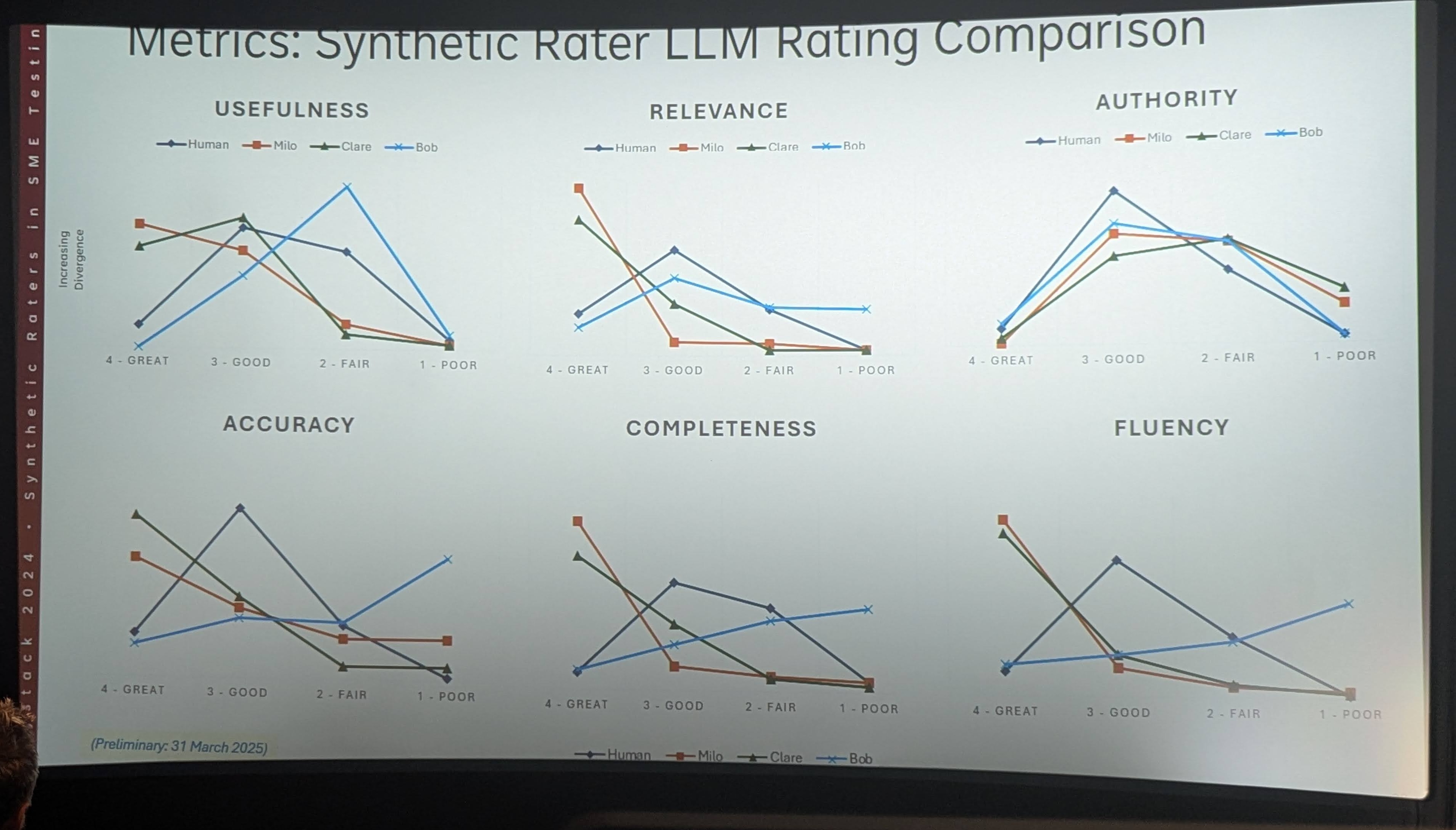
The numbers speak volumes: one experiment compared 175 hours of human rating with just 40 minutes of synthetic review. The performance was solid out of the box, especially on straightforward tasks. On the other hand, it also became clear that synthetic raters required more well curated training data compared to human raters, and that their performance could decrease significantly when requesting more complex analysis.
In summary, both talks underlined that to be trustworthy, synthetic raters need careful tuning: they must avoid hallucination, be instructed not to guess, and provide reasoning for each decision. Real experts are still needed to verify the model’s scoring logic, but only periodically, to validate the judge’s work rather than perform all the heavy lifting.
Another hot topic throughout the conference was the role of LLMs in changing how people find and interact with information.
I was especially struck by Vespa’s talk, held by Kristian Aune, who explored how large language models can enable users to express search preferences naturally, without needing to rely on filters or rigid interfaces.
A live demo showed how a chatbot interface could be used to search for cars on a popular e-commerce website, with queries such as “I want a cheap car but I like to feel safe on the road”. This suggests a new buying experience based on conversation, where results are directly refined based on natural-language queries.
Under the hood, the system works by translating user queries into JSON-formatted mapped tensors, which Vespa then uses to rank documents via a customizable scoring function. These tensors represent key-value pairs linked to ranking signals, allowing for structured evaluation of relevance.

While technically promising, this approach is rarely used in production, not because of infrastructure limitations, but rather because users aren’t yet familiar with this way of searching. The main challenge, then, isn’t the model: it’s the mental model! Good UX design and user education will be crucial for the success of this approach.
A few sessions hinted at where things might be going next. Companies like Aryn are reimagining unstructured search as something closer to analytics.
Recognizing that approximately 90% of enterprise data is unstructured, comprising documents like long reports and interviews, Aryn’s platform aims to extract insights from this vast information reservoir.
Traditional RAG systems are limited by the LLM’s context window, and they do not give their best when it comes to counting and filtering. You can ask a RAG fairly simple questions, but sometimes experts need to do research tasks, with a common semantic schema.
Aryn’s answer to this problem is a system that performs “deep analytics”, made of three key components:

The bottom line from Mehul Shah’s presentation is that this type of tool empowers humans, it does not replace them. AIs are great guessing machines, which can process and analyze vast amounts of unstructured data, but the real challenge is to independently verify their output, so human supervision remains fundamental.
Among the most grounded and widely applicable insights from the conference was a reminder that effective search systems are not only built in code, but they’re also shaped by understanding user needs. The search product management talk presented by Women of Search, and Aruna Govindaraju’s talk on User Behavior Insights explored this theme from different but complementary perspectives.
In the talk How Great Product Managers Build for Impact, by Audrey Lorberfeld and Samdisha Kapoor, the central message was that search needs its own product management playbook. Unlike more deterministic features, search success is inherently probabilistic: it is related to user perception, which is subjective, so product managers working in this space better get comfortable dealing with uncertainty. That means starting with clear definitions of what success looks like, converting fuzzy goals into metrics, and focusing not just on what’s shipped, but on how it changes user behavior.

The best teams, according to the speakers, look at patterns in search logs rather than reacting to one-off complaints. They run experiments based on hypotheses, document their decision-making, and involve cross-functional partners in ongoing conversations. One practical piece of advice: bring engineers into user calls, so the system’s behavior is placed in the context of actual user frustration or amusement.
Frameworks like RICE can help prioritize improvements, but they must be adapted to the context and always done with purpose, based on practical factors like the type of business or the team size. It’s also important to evaluate opportunity sizes: how big of an impact could a change have, in terms of revenue?
The second talk, Supercharging Search in OpenSearch, drove home the operational side of this philosophy. The speaker showed how easily organizations fall into the trap of building without understanding. Too often, search logs are collected but not analyzed. Metrics are available but not connected to strategy. The result? Creative chaos.
UBI changes that by giving teams a toolkit to analyze search usage at scale. One example showed how users consistently searched by brand, but never clicked the brand filter, because it was placed too low on the page. Without behavioral analysis, the release of the feature would have been considered a success, but with it the issue becomes obvious. Collected UBI data can also be consumed to produce a relevance quality evaluation, and then to improve boosting and ranking of all kinds of search results, essentially creating a feedback loop that goes from collection, to measurement, to tuning, and back again.
What both talks made clear is that understanding user behavior is not optional if you want to build impactful search. Whether you’re designing a new feature or trying to improve relevance, the first step is always the same: figure out what people are actually trying to do. The good news? We have more and more tools to do that work.
Among the many tools, ideas and use-cases presented at Haystack this year, it was the opening keynote by Rick Hamilton that offered perhaps the most lasting takeaway. It set the tone for the entire conference, reminding everyone that while AI can enhance our capabilities, it’s our curiosity, critical thinking, and creativity that still steer the wheel.

AI can become a powerful ally in creative work: by taking over repetitive or low-value tasks, it allows our imagination to focus on higher-level matters. With AI we can achieve rapid data analysis and pattern recognition, simulate real-world scenarios with fewer prototypes and iterations, explore ideas, and even get customized learning plans.
But alongside that potential comes a warning. As AI becomes better at delivering answers, the ease of auto-completion and instant suggestions can dull critical thinking and lead to skills atrophy. The flood of recommendations and endless content can distract us from focused work. The constant confirmation bias coming from AI’s tendency to create echo chambers can cause a homogenization of perspectives.
The takeaway wasn’t to resist AI, but to use it deliberately, to remain creators rather than just curators. Innovation, the speaker reminded us, is a process of re-elaboration, of making connections between domains, of challenging what already exists. Therefore, to achieve it we need to build a wide foundation of knowledge for ourselves, looking critically at existing solutions, refusing to settle with “good enough.”
If there’s one thread that tied all of Haystack 2025 together it’s this: tools and technologies matter, but mindset matters more. AI can elevate our work, but only if we remain intentional about what we’re building, who we’re building it for, and why it matters. And that, more than any single architecture or technique, is what will shape the future of search.