
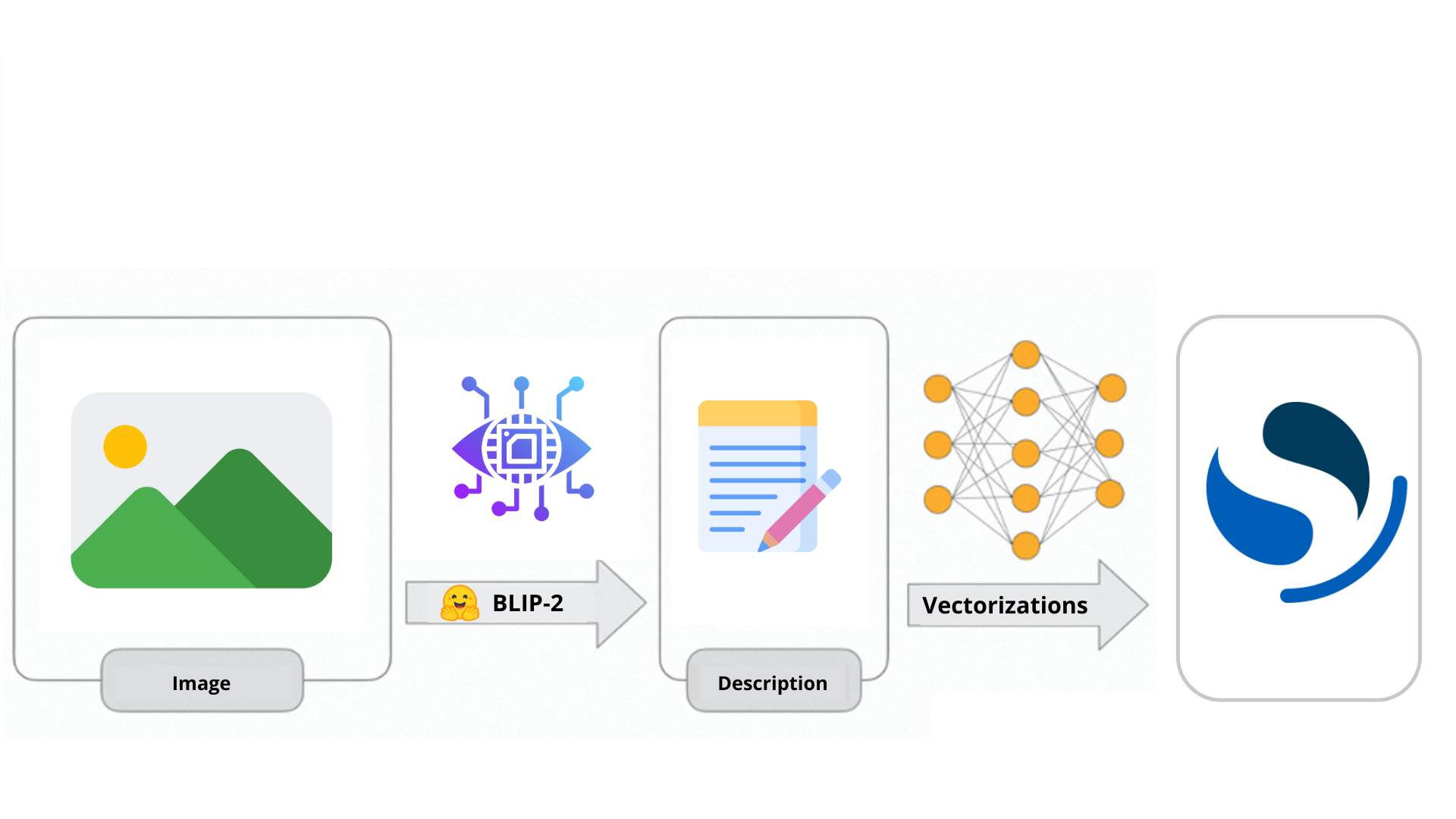
BLIP-2 is a model that combines the strengths of computer vision and large language models. This powerful blend enables users to engage in conversations with their own images and generate descriptive content. In this article, we will explore how to leverage BLIP-2 for creating enriched image descriptions, followed by indexing them as vectors in Opensearch.
Recently, OpenAI unveiled the remarkable capabilities of GPT-4, which entered into the domain of multi-modal large language models. This means that, while in the recent past our interactions with the most renowned chatbot were limited to text-based requests, now we can engage in direct conversations using our voice or send images to ask questions about them.
ChatGPT can now see, hear, and speak
The way this works is similar to the functioning of BLIP-2, an open-source model that can be used for conditional text generation given an image and an optional text prompt.
In this article we are going to explore the characteristics of BLIP-2 and its differences from its predecessor. Furthermore we will see how to use this model to generate enriched descriptions of our images before indexing them to our Opensearch cluster.
Blip-2 is a remarkable model that has made significant strides in the realm of vision-language understanding. It builds upon the foundations laid in the paper titled “BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models” by Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2 leverages the power of pre-trained image encoders and large language models to perform an intricate dance between images and text.
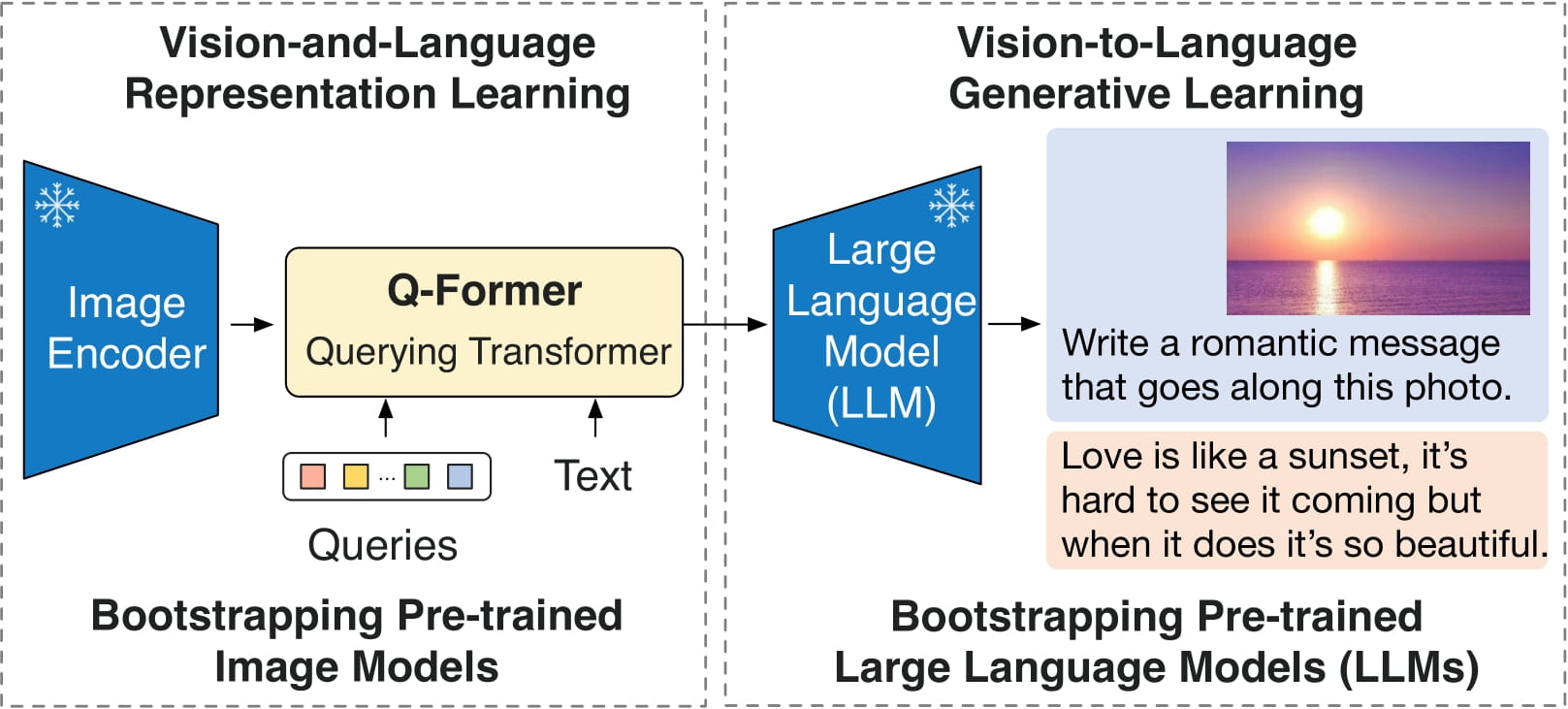
Before it’s ready for action, Blip-2 undergoes a two-steps training process. In the first step, Blip-2 learns recognizing objects and scenes in pictures and in the second stage, it learns to understand the relationship between images and text.
To understand how it works, we will work through examples:
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "What do you see?"
qtext = f"Question: {question} Answer:"
inputs = processor(raw_image, qtext, return_tensors="pt")
out = model.generate(**inputs, max_new_tokens=1000)
print(processor.decode(out[0], skip_special_tokens=True).strip())
In this example, we are running Blip-2 with Opt-2 (a Large Language Model with 2.7 billion parameters). We provide the model with a photo depicting a woman and her dog playing on the shore. Next, we inquire with the model about the image, specifically asking, “What do you see?” The model correctly responds that there a woman and her dog on the beach.
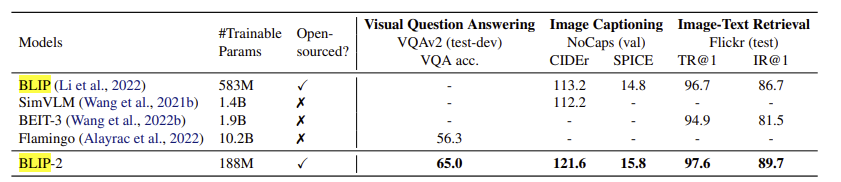
Despite the two models have been trained on the same dataset, BLIP-2 outperforms BLIP thanks to its architecture and the use of a LLM. Here we have some comparison on various zero-shot vision-language tasks:
We conducted practical tests by describing various pictures, and the results unequivocally confirm the models’ proficiency in the labeling task.
| Image | Description BLIP | Description BLIP-2 with OPT2.7 as LLM |
|---|---|---|

|
A black duff bag with a white dot pattern | A black duffel bag with a zipper pocket |

|
A pair of shoes sitting on a concrete surface | A pair of neon green running shoes sitting on a ledge |

|
The black ballpoint pen with gold trim | A fountain pen with a black and gold trim |

|
A box of milk with a white and green label | Everfresh full cream milk 6l |
One of the most remarkable features of BLIP-2 is its exceptional efficiency in answering visual questions. With this model, we can inquire about various aspects of an image, which proves invaluable for extracting information. For instance, we can ask about the brand of the shoes (the model correctly identifies the one in the photo as Saucony), inquire about the color of objects within the scene, or request any other specific details that could be useful to index.
Once the descriptions of the image are generated, indexing them as vectors is as easy as drinking a glass of water. For vector embedding, we decided to use “all-MiniLM-L12-v2” model, which is adequately efficient and relatively small.
First thing we need to do is import the model, which will run into our dedicated machine learning node.
POST /_plugins/_ml/models/_upload
{
"name": "huggingface/sentence-transformers/all-MiniLM-L12-v2",
"version": "1.0.1",
"model_format": "TORCH_SCRIPT"
}
Secondly, we can create a pipeline that will use the model to generate the appropriate output, which is a 384-dimensional vector. Each dimension of this vector will determine the position of the document in the vector space. In other words, the vector defines the document based on certain characteristics.
PUT _ingest/pipeline/nlp-pipeline
{
"description": "Neural search pipeline to vectorize our image's description",
"processors" : [
{
"text_embedding": {
"model_id": "GyNHmYoB6VptOom2kytA",
"field_map": {
"image_description": "image_description_vector"
}
}
}
]
}
Note that the field_map indicates the association between the ‘image_description’ field and the ‘image_description_vector’ field. When we create our index, it’s necessary to specify the secondo field, the one used to store the vector as “knn_vector”. Also, it’s mandatory to define the correct dimension for the field, which depends on the model we are using: 384 in our case, since we are using all-MiniLM-L12-v2 model.
PUT vector_images_index
{
"settings": {
"index.knn": true,
"default_pipeline": "nlp-pipeline"
},
"mappings": {
"properties": {
"image_description_vector": {
"type": "knn_vector",
"dimension": 384,
"method": {
"name": "hnsw",
"engine": "lucene"
}
},
"image_description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
Once this is done, every time we will index the description generated from our images using blip-2, this will be stored as text in the “image_description” field, and as vector in the “image_description_field”, allowing us to perform both semantic and vector search.
We find ourselves in the midst of a transformative era where machine learning and search technologies are advancing at an astonishing pace. The emergence of Large Language Models (LLMs) and vector search are shaping the future of search in profound ways, leading the changes. In this panorama, Blip-2 represents not only a significant milestone in the journey of vision-language understanding but also a significant step towards the future of search