
An overview about NLP and a practical guide about how it can be used with the Elastic stack to enhance search capabilities.
Natural Language Processing is a fascinating field that has seen tremendous progress in recent years. During one of our “Search & Data” event, our colleague Vincent Brehin delighted us with a talk about the ways NLP is being used to improve search and analytics.
In this article, we will provide a summary of that presentation, exploring the basics of NLP and its applications in search and data analysis.
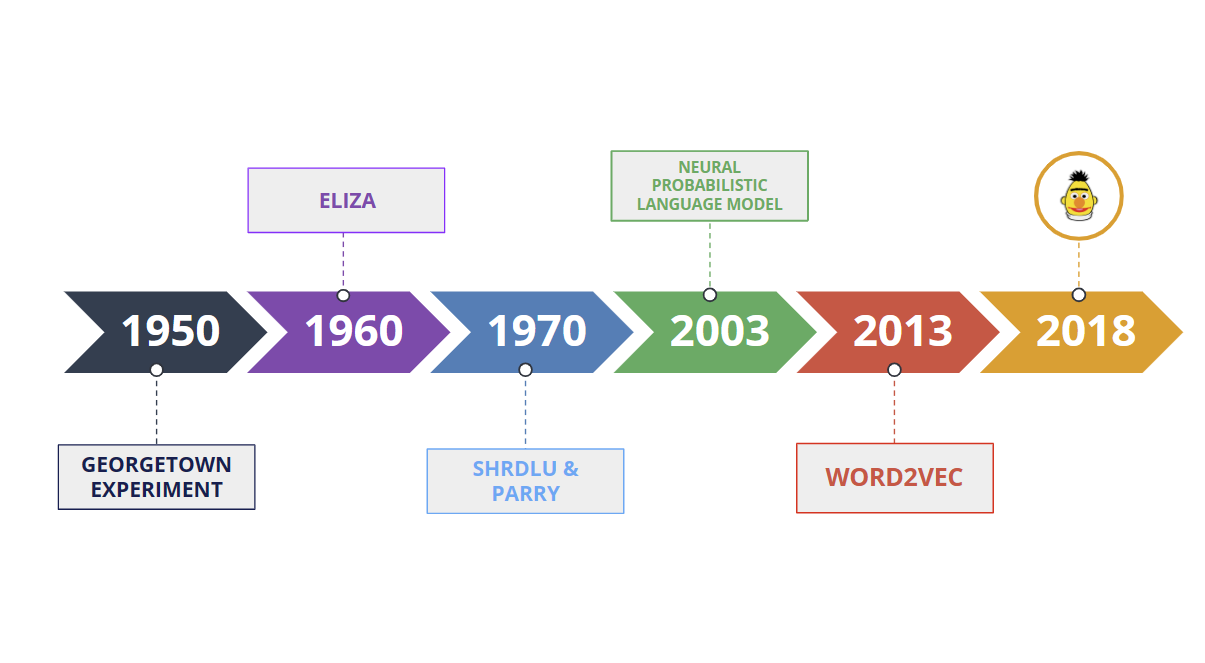
Natural language processing is an interdisciplinary field that combine computer science, linguistic and artificial intelligence. No wonder it has been around for decades, fascinating the academic world. Indeed, NLP has its roots in the early days of computer science when researchers began exploring ways to enable machines to process human language.
One of the earliest attempts to develop an NLP system was the Georgetown experiment in the 1950s. Researchers at Georgetown University created a machine translation system that could translate simple sentences from Russian to English. The system was based on a set of rules that the researchers had manually defined.
In the 1960s, the first chatbot, ELIZA, was created by Joseph Weizenbaum at MIT.It used pattern matching and substitution to simulate a conversation with a human.
Then in the 1970s, systems like SHRDLU and PARRY were developed to understand natural language commands and generate appropriate responses.
In the 2000s, NLP began to shift towards statistical and probabilistic models. The neural probabilistic language model (NPLM), proposed in 2003, used a neural network to model the probability distribution of words in a sentence. This enabled the system to better handle the uncertainty and variability of natural language.
More recently, with the rise of deep learning, models like Word2Vec and BERT have revolutionized the field of NLP. In particular, BERT is a deep learning model based on the transformer architecture that can be fine-tuned for various NLP tasks, such as, vector search, question answering and sentiment analysis.
Natural language processing is a critical component of any modern search technology. Any search query is expressed using natural language, which means that the search engine has to analyze it to interpret our language. Elasticsearch can count on analyzer for text segmentation, word stemming and filtering. This, used in conjunction with the scoring vector and the inverted index, allow the search engine to identify the documents that are more like relevant to our user’s search query.

One of the issue of keyword search rely on the lack of the ability to understand the meaning and the context of words, which can result in irrelevant results even when the query is technically correct. To address these limitations, search technology has evolved towards “semantic search”. This evolution has been driven by advances in artificial intelligence, especially in NLP.
Modern NLP algorithms have made great strides in performing various tasks on text data.Here some of the most important applications:
NER is the process of identifying and classifying named entities in text data, such as names of people, organizations, locations, and other entities. Modern NLP algorithms use Conditional Random Fields (CRF) or Recurrent Neural Networks (RNNs), to analyze the context of the text and predict the named entities. These models are usually trained on large annotated datasets, where the entities are labeled for the model to learn from.

Sentiment Analysis is the process of analyzing the emotions, opinions, or attitudes expressed in text data. Modern NLP algorithms use machine learning models, such as Support Vector Machines (SVMs), Naive Bayes classifiers, or Deep Neural Networks (DNNs), to classify the sentiment of the text as positive, negative, or neutral. These models are usually trained on large annotated datasets, where the sentiment of the text is labeled for the model to learn from.

QA is the task of automatically answering a question posed in natural language. Modern NLP algorithms use machine learning models, such as BERT or GPT, to answer questions. These models are trained on large datasets of questions and answers and are able to generate a response based on the context of the question.
To learn more about question answering, check this article out:
Question answering, a more human approach for our research on all.site

If you want to perform natural language processing tasks in your cluster, you must deploy an appropriate trained model. The simplest method is to use a model that has already been fine-tuned for the type of analysis that you want to perform. That’s where Hugging Face comes into play as the ideal tool.
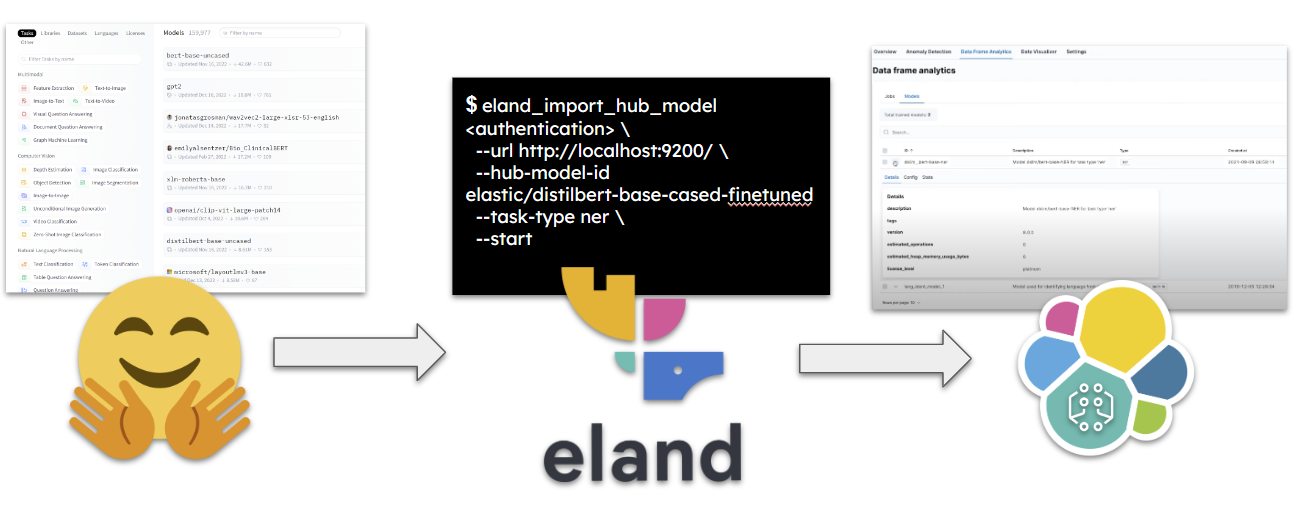
To download and directly send the desired model to our cluster we can use Eland Python client. Below is an example command for this process:
eland_import_hub_model
--cloud-id <cloud-id> \
-u <username> -p <password> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner \
--start
Using the –start option, will deploy the model directly in our cluster. Alternatively it is possible to utilize the model deployment API. Currently only pytorch models are supported for deployment.
Having done so, it is possible to utilize Elasticsearch’s ingest pipeline feature to use the NLP model for inference. Indeed, ingest pipeline allows the user to preprocess, transform and enrich data before indexation: user can incorporate the NLP model into the data processing workflow to extract features from text data and improve search relevance. For example, we can infer messages or tweets valuation using a fine-tuned model for sentiment analysis, or we can also use inference at ingest to embed our data into dense vectors in order to perform vector search.
To do so, it’s necessary to:
To learn more about it check how to deploy a text embedding model and use it for semantic search
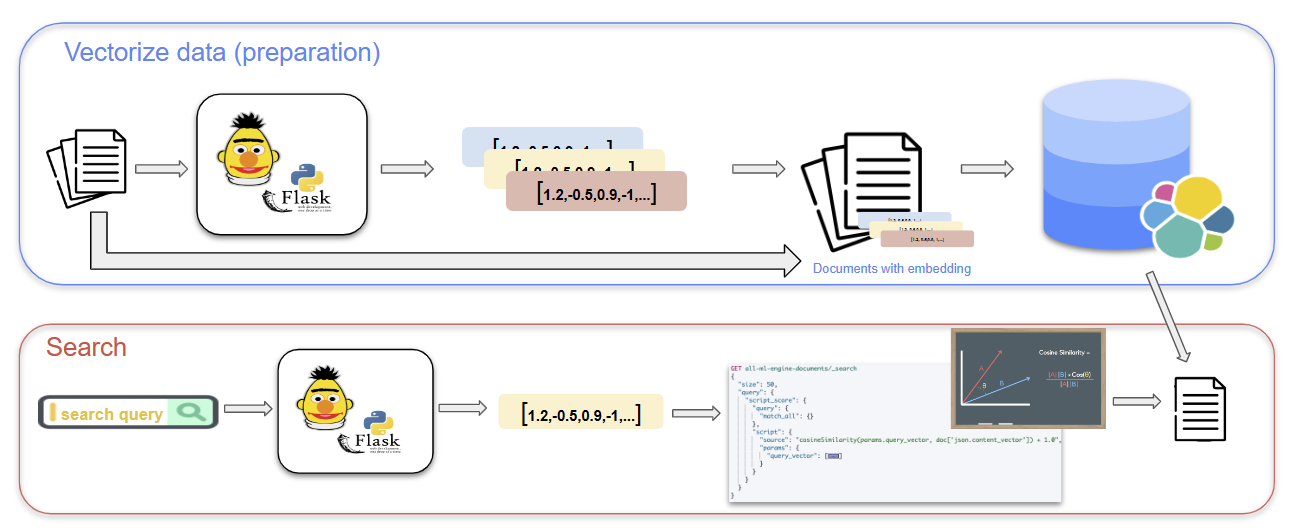
All of this, is only included within the platinum licence of Elasticsearch. But don’t worry, there is a way to do all this for free. One approach is to use a Flask module, such as “Flask-RESTful”, to build a RESTful API that connects to Elasticsearch and implements vector search.
To use this approach, you can start by vectorizing your text data using a pre-trained word embedding model, such as Word2Vec or a proper fine-tuned version of BERT. Next, you can upload the vectors to Elasticsearch using the Elasticsearch Python client, and create an index mapping that includes a vector field for storing the vector values. With the vectors and index in place, you can use the Flask module to create an API endpoint that accepts a search query and performs a vector search against the indexed documents. This involves calculating the vector similarity between the query and each document in the index, and returning the top results based on their similarity scores.
Natural Language Processing (NLP) has become a crucial aspect of search and data analysis. From its early beginnings with the Georgetown experiment and the development of early chatbots like Eliza, Shardlu, and Parry, NLP has evolved significantly over time. Today, advanced NLP techniques such as Word2Vec and BERT are used to enable semantic search and better understand natural language queries. As NLP continues to evolve, we can expect to see even more powerful and innovative applications of this technology in the realm of search and data analysis.