
Everything about Question-Answering and how to implement it using a flask and elasticsearch.

Without any doubt, question answering is one of the main approaches to make research more similar to a conversation with an old wise friend who knows everything about everything, rather than with a machine. To do so, Question answering mingles information retrieval techniques with Natural Language Processing (NLP).
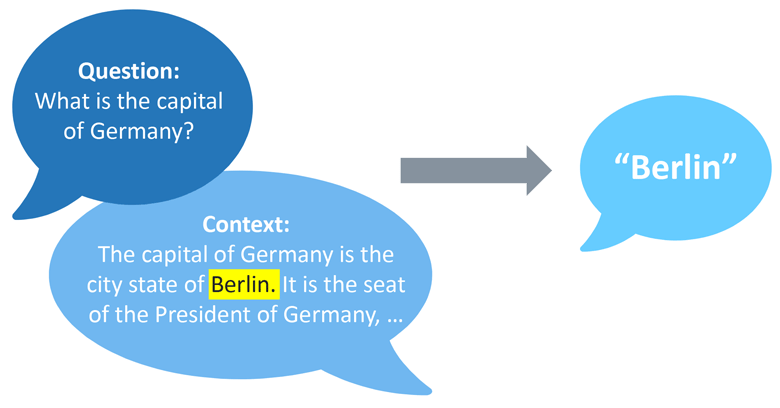
In this context of question answering, a trained model can be used to retrieve the answer to a question from a given text, which represents the search context. This process known as “Extractive QA” differs from the Open Generative QA and the closed generative QA, as in the first case there is no question and in the second there is no context. In extractive QA we must have a Question and a Context, but, often, this is not enough to infer an answer (or at least the correct one). Indeed every answer will have a score which represents the level of certainty that the given answer is the correct one.
For Adelean, as a leader in the innovation in the domain of search engines, question answering represents a challenge not only to make research more relevant, but also more user-friendly. Moreover, given the collaborative nature of all.site, we believe Question Answering can match the user‘s needs.
Let’s move forward to the crux of the matter, how question answering has been implemented in our collaborative search engine.
First of all, it is important to specify that since elasticsearch does not offer a proper open-source solution, we decided to develop our own solution in the form of a REST API, combining the flexibility of Python with the potential of the microframework flask.
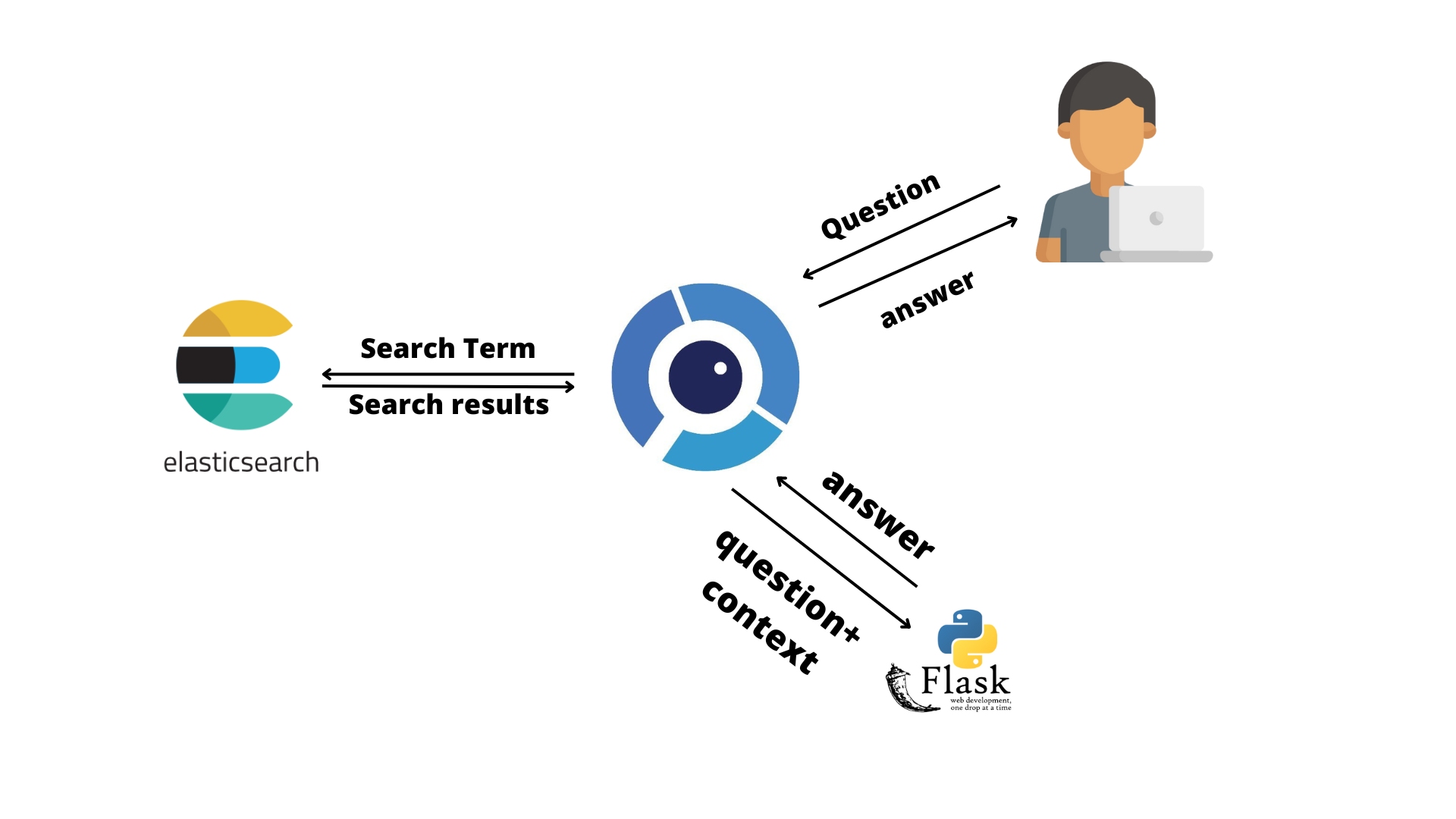
So how does all of this work:
from the user’s question, the most relevant terms are extracted to perform the research. This filtering, which is done using a stop words list, allows the creation of a better search query which will result in a better selection of the documents which are going to be used as context in the question answering task. Each document is sent to the flask api with the question. Here some ulterior cleaning and selection of the most relevant fragment is done, so to have a clean context.
Once this is done, the question and context are ready: what it’s missing is the model.
It is possible to create and train its own model, or use pre-trained ones, downloading them from:
Hugging Face - Question Answering
For our purposes we decided to pick the tinyroberta model: it is a distilled version of the roberta-base model which provides comparable predictions more quickly. Here are some examples of how to import the pre-trained model.
model_name = "deepset/tinyroberta-squad2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = ORTModelForQuestionAnswering.from_pretrained(model_name, from_transformers=True)
nlp = pipeline("question-answering", model=model, tokenizer=tokenizer)
In this case we decided to use an ORT model as is more appropriate for use in size-constrained environments.
The pipeline() function makes it simple to use the model for inference: in machine learning, model inference is the process of using a trained model to make predictions on new data. In other words, after you’ve taught a machine learning model to recognize certain patterns, model inference allows the model to automatically apply that knowledge to new data points and make predictions about them.
The prediction returns a result for each given fragment’s document: this result is made by two parts, an answer and its relative score. Only if the score is bigger than a given threshold the answer will be considered as correct and it will be sent back to the user.
for hit in resp['hits']['hits']:
for fragment in hit['highlight']['attachment.content']:
context = cleanAndTrim(fragment)
QA_input = {'question': question,
'context' : context}
answer = nlp(QA_input)
if (answer.get('score') > 0.50):
return answer.get('answer')
Setting the most correct threshold value can be extremely challenging: indeed if a too low threshold increases the recall and decreases the response time, while a too high threshold increases the precision, but can decrease the response time. It’s also very important that the context used in the inference process is clean, clear and relevant.
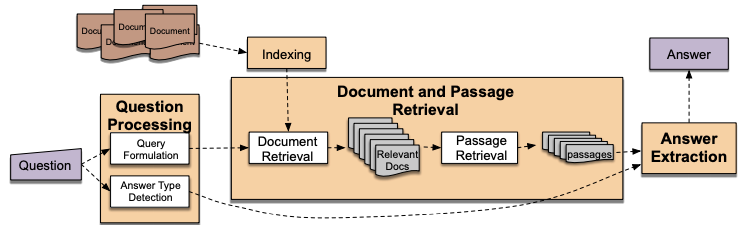
That’s why the differents steps of optimization are necessary
Machine learning sets everyday new challenges for the future. As leaders in innovation we must be always on the ball and updated as regards the new solutions and the new technologies: question answering is only a first step for the revolution that is going to make search-engines more powerful.
Vector search and pre-generative transformers are coming next.