
A summary of the talk Scaling an online search engine to thousands of physical stores by Roudy Khoury and Aline Paponaud at ElasticON 2023

We presented the English version of this talk at Berlin Buzzwords last year. This year, on March 8, we participated in the ElasticON Global 2023 conference, where we presented our search engine solution for managing a large number of online stores. This was an opportunity to generalize and update the presentation, and also to share our experience in French.
Online shopping has been an opportunity for some e-commerce stores during the Covid-19 crisis. But for almost all businesses, it has brought a multitude of new challenges. Today, almost all physical stores want to go online.
The search engine plays a very important role in the success of e-commerce stores. So there are features that are expected of the search engine:
When a store wants to go online, it will need to manage a lot of data. This data can take several forms: in files, in a database, or obtained via streams from different sources.
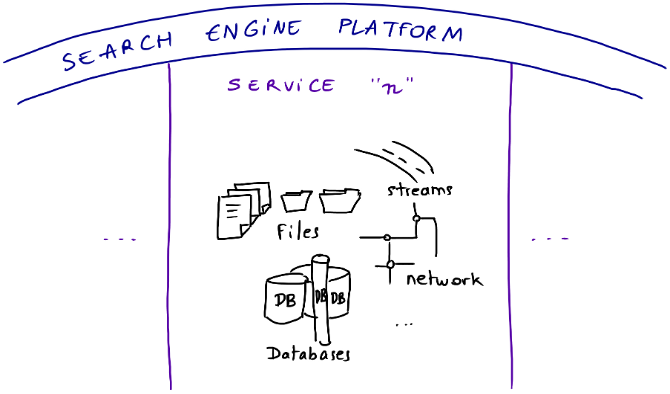
We can have different levels of maturity between store data, the data can vary from one store to another, they are heterogeneous, and they come from many sources. So the search engine platform needs to be built on top of that. It is necessary to manage all the complexities that come with the data, hide them and present them in a clean way.
There are several approaches for managing data in Elasticsearch. As we have specificities for each store’s offers, for example, promotions that exist in one store but not in another, the first idea that comes to mind is to have a large index with all the product and offer data in it, duplicated by store.
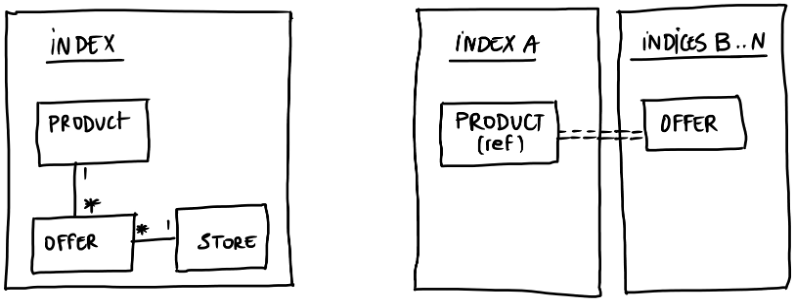
This could be a good solution since this approach is compact, unitary, and in which the cluster state remains small, but there is also another idea.
We can create an index with product references, i.e., product data that does not change between stores, and then all offers will go into indexes separated by stores, one index per store. In this case, we have a model that looks like a relational data model.
However, there are drawbacks:
What we did to solve these points is that we set up an index per store.
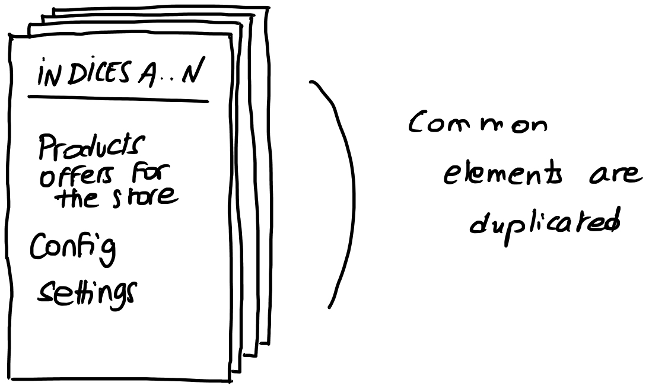
In the store index, we store all products and offers for that store with the configuration. In this case, there will be duplications because there are common elements in the data for several stores. Since we have an index per store, we can really fine-tune each store. In this case:
Everyone who has managed to put their store online will be in direct competition with the big players (Amazon, Rakuten, etc.). The search engine will be able to show products from stores, and if there are none, it can show products from the marketplace. This can be a 3rd party that provides products with delivery options. So the search will include physical stores as well as the marketplace, and the idea is that the search engine hides these complexities.
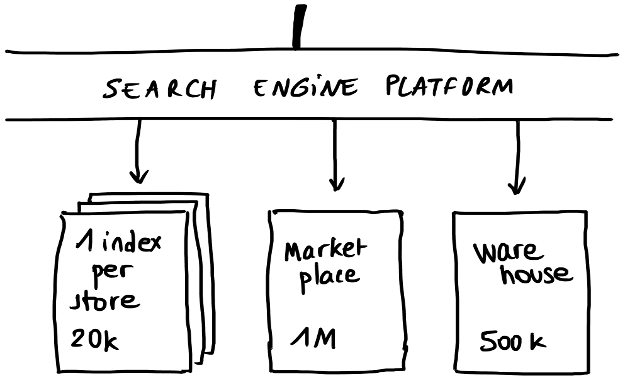
We can have thousands of physical store products and millions of marketplace products. Since marketplace products will not have specific features, they can be grouped into a single index.
There is still one problem to solve: products do not have the same data type or structure. We can have food and non-food products that do not necessarily have the same structure and fields. So we need some kind of intelligence during indexing to pool this. For this, a common schema for product data has been proposed. We will prepare our data in advance before indexing to have a well-defined structure, and in this way the search will be able to work on multiple indexes at the same time, both marketplace and store.
To ensure the scalability of our search engine, there are a few points to guarantee:
A quick view of such a solution:
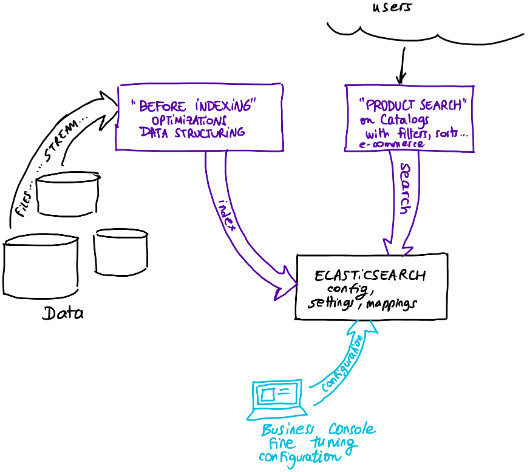
Since we have a lot of indexed data, the cluster state can quickly become large. So we need to make sure we have a multi-cluster setup.
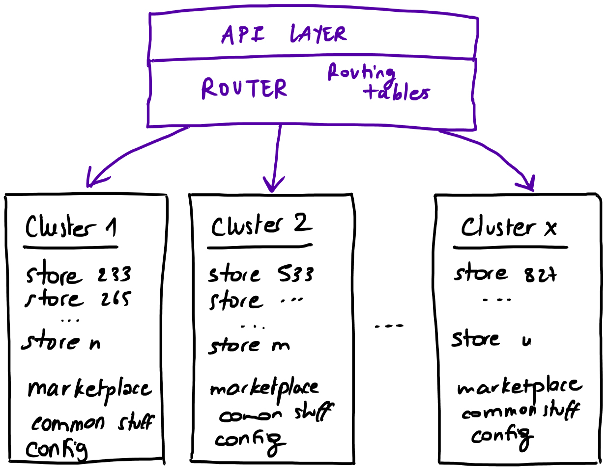
We create multiple clusters on which we distribute the indexes and duplicate the common indexes such as the marketplace index. Therefore, we will need a router that will have a table containing information on which cluster each store is on.
Points to consider for monitoring the search engine:
To conclude, here is a checklist to consider when building an e-commerce search engine: