
all.site is a collaborative search engine. It works like Bing or Google but it has the advantage of being able to go further by indexing for example media content and organizing data from systems like Slack, Confluence or all the information present in a company's intranet.

all.site all.site is a collaborative search engine. It works like Bing or Google but it has the advantage of being able to go further by indexing for example media content and organizing data from systems like Slack, Confluence or all the information present in a company’s intranet.
In order to improve the relevance of our research, we have added to all.site the ability to find media such as videos or podcasts by searching for terms that exist only in the transcripts of those media.
The speech-to-text is a technology that has evolved enormously, especially following the advent of Machine Learning. Speech-to-text is for example used by voice assistants like Alexa and Siri.
In the case of all.site, media transcripts are extracted using the speech recognition toolVosk API.
Vosk API is an open source library that works in offline mode. It supports over 20 languages and dialects including English, French, Spanish, Chinese… Vosk provides speech recognition for chatbots or virtual assistants. The technology can also create subtitles for movies or transcripts for conferences.
Vosk is a speech recognition toolkit that supports many languages. Each language has its own model. For more information here is an example of a VOSK use case that we use for our collaborative search engine all.site.
For routine use, the templates available on the VOSK website are more than sufficient.
However, in a use case that includes the detection of industry specific words for example (“Ruby on Rails”, “Python”, “Combined Cycle Power Plant” etc.), we need to train the model on these specific words. This process is more commonly called “Fine-Tuning the model”. The final goal is to have a dictionary of custom words to refine the audio transcription of a specific domain.
The objective of this Fine-tuning process is to detect the proper words that are part of a “jargon” when transcribing media content. You can find our previous article describing our feedback on “indexing media file transcriptions” by clicking on this link.
As an example, let’s take a web programming tutorial. This audio contains proper words that are not found in the French dictionary, e.g. Java, Python, Php, etc.
If we really need to transcribe this tutorial correctly, we will have to adjust the model on the words in question so that it can associate them with their corresponding phonemes, and eventually detect them.
Above you will find the first version of the transcript of the mentioned tutorial (with a default template without adjustment).
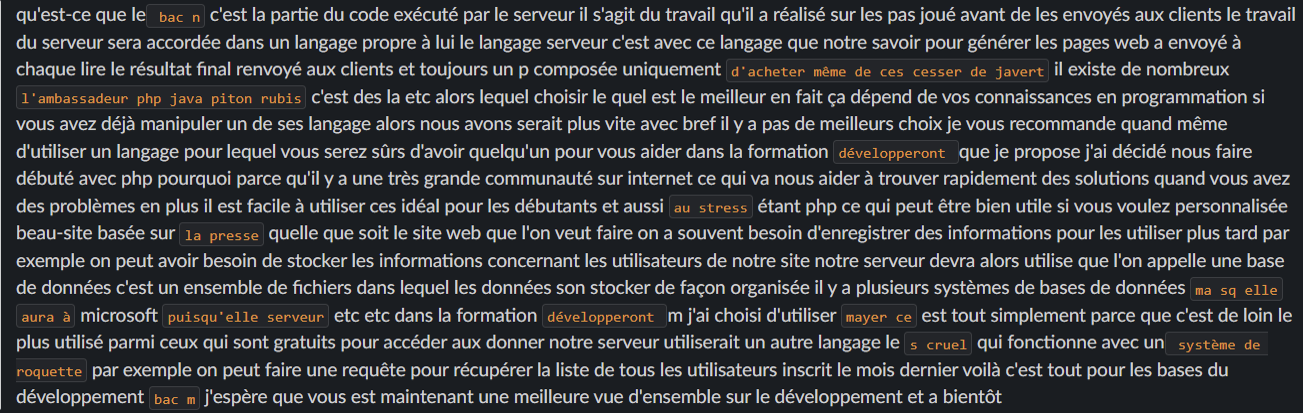
As you can see, a large number of words are not detected correctly. The solution is to adjust the model on this list of words.
Each template we use is in the form of a folder that contains files. To adjust the model, you need to download a model adjustment package which is available on the official VOSK website (for more information refer to the documentation of this topic) After downloading the model fitting package (also called compile package), add in the directory db/extra.txt new words as long as they are in a sentence context. An example of the contents of the file extra is as follows:
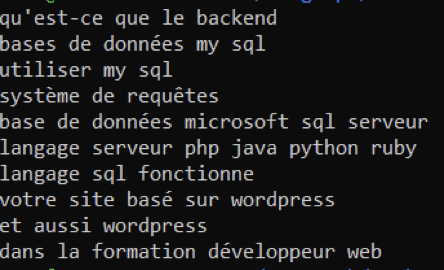
Then, as the VOSK models are supported by KALDI, we need to download and install KALDI locally to be able to adjust the model using the compile package.
The best way to install KALDI is to follow their official installation guide. Phonetisaurus and SRILM are two required dependencies as well. For more information on installing KALDI and the dependencies, take a look at the last section of this article.
When KALDI is well set up, all that remains is to launch the model fitting process, via the execution of the script called compile-graph.sh that exists in our compile package. Do not hesitate to look for errors in the output of the adjustment process.
At the end of the process, several files are generated that must be retrieved and copied to the model folder (remember that we are currently in the “compile package”). For large models, the following files must be recovered:
It is possible not to copy everything. The Vosk system remains functional by copying only their analogues into the model folder. Of course you have to overwrite them. For lightweight models, get the necessary files that exist in the exp/tdnn/graph and copy them to the model folder, and overwrite each file that exists there with the new recovered files (remember that this directory exists in the compile package). After these steps, the template is now ready to run a second transcription.
After the adjustment of a light French model, we launched a transcription on the same audio, you will find below the result:
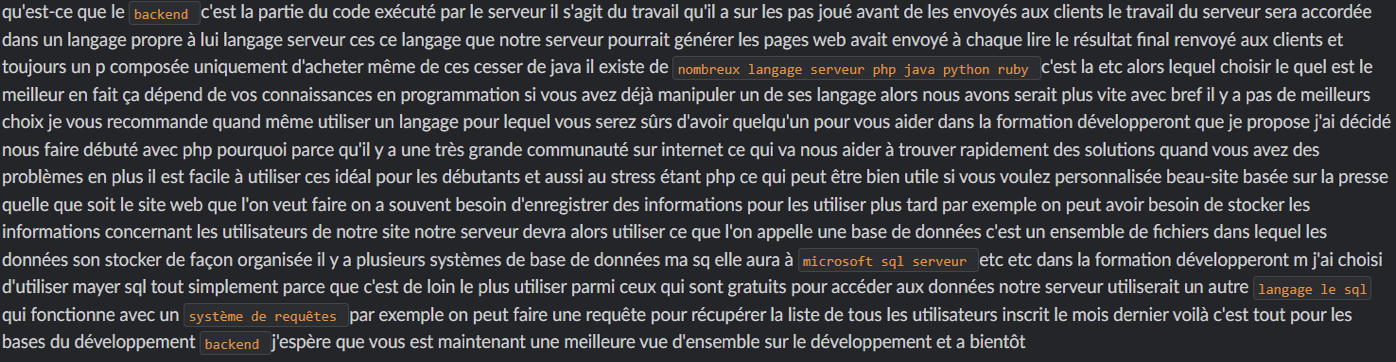
KALDI is a prerequisite for fitting Vosk models. The installation guide mentioned earlier in this article is not too detailed. If you encounter any problems while installing KALDI or running the script compile-graph.sh which readjusts the model, it is necessary to check the installation of KALDI and its components. You will find a detailed installation guide towards the end of this article.
To adjust the French heavy model (fr-0.6-linto) on new words, you need a significant hardware configuration to be able to complete the process in 15-20mn: A Linux server with a minimum of 32Gb RAM and 100 Gb of free disk space. On the other hand, according to the feedback from Vosk support, you can “prune” the model with the command line ngram. Here is an example of the complete order:
ngram -order 4 -prune 1e-9 -lm db/fr.lm.gz -write-lm fr1.lm.gz
A new file is created: fr1.lm.gz
It should be renamed to fr.lm.gz and overwrite it with the one that already exists in db/fr.lm.gz.
Now the model fitting process should not use too many resources.
Make a “clone” of the KALDI project on GitHub via the command that is in theKALDI doc
Run the following script: KALDI/tools/extras/check_dependencies.sh
If you plan to use Python3
you must execute the following command:
touch /app/kaldi/tools/python/.use_default_python
KALDI/tools/extras/install_mkl.sh
apt-get install gfortran sox
make -j <N>
KALDI is designed for parallelism.
To boost processing replace N with
the number of CPUs you want to allocate for this process.
pip install phonetisaurus
Chnge directory to « compile package » and open path.sh to modify it and add the libraries (if needed).
make
/KALDI/tools/extras/install_irstlm.sh
After the execution of the script, get the content of the file
tools/env.sh file and add it to the path.sh file of the compile package.
apt-get install gawk
Run the script KALDI/tools/extras/install_srilm.sh
./configure –shared puis make -j clean depend.
modify l.583 in KALDI/src/configure and attribute the value of the absolute path of MKL to MKLROOT variable
Bydefault, the value is: /opt/intel/mkl.
Run ./configure
make clean -j depend
ln -s /app/kaldi/egs/wsj/s5/steps ./steps
ln -s /app/kaldi/egs/wsj/s5/utils utils
KALDI/src/fstbin
KALDI/src/tree
KALDI/src/bin