
all.site is a collaborative search engine. It works like Bing or Google but it has the advantage of being able to go further by indexing for example media content and organizing data from systems like Slack, Confluence or all the information present in a company's intranet.

all.site is a collaborative search engine. It works like Bing or Google but it has the advantage of being able to go further by indexing for example media content and organizing data from systems like Slack, Confluence or all the information present in a company’s intranet.
In order to improve the relevance of our research, we have added to all.site the ability to find media such as videos or podcasts by searching for terms that exist only in the transcripts of those media.
The speech-to-text is a technology that has evolved enormously, especially following the advent of Machine Learning. Speech-to-text is for example used by voice assistants like Alexa and Siri.
In the case of all.site, media transcripts are extracted using the speech recognition toolVosk API.
Vosk API is an open source library that works in offline mode. It supports over 20 languages and dialects including English, French, Spanish, Chinese… Vosk provides speech recognition for chatbots or virtual assistants. The technology can also create subtitles for movies or transcripts for conferences.
The goal of this project is to transcribe media content and then index it in Elasticsearch, to allow our users to extend their search to content currently in audio format. In this way, the search engine all.site gains search relevance and significantly improves the user experience.
Vosk API supports several programming languages (Java, PHP, Node, etc.) and runs on lightweight systems (Raspberry Pi, smartphone, etc.) without the need for a huge computing capacity. Moreover, the technology is easy to install, with light or heavy models depending on the needs. Vosk API, combined with ffmpeg, can analyze several media file formats including mp3, mp4, wav, etc. It is also possible to perform vocabulary customization and model adaptation for better speech recognition performance, a topic we will cover in a future post.
In this example, we add a web source with the URL of the site to crawl:
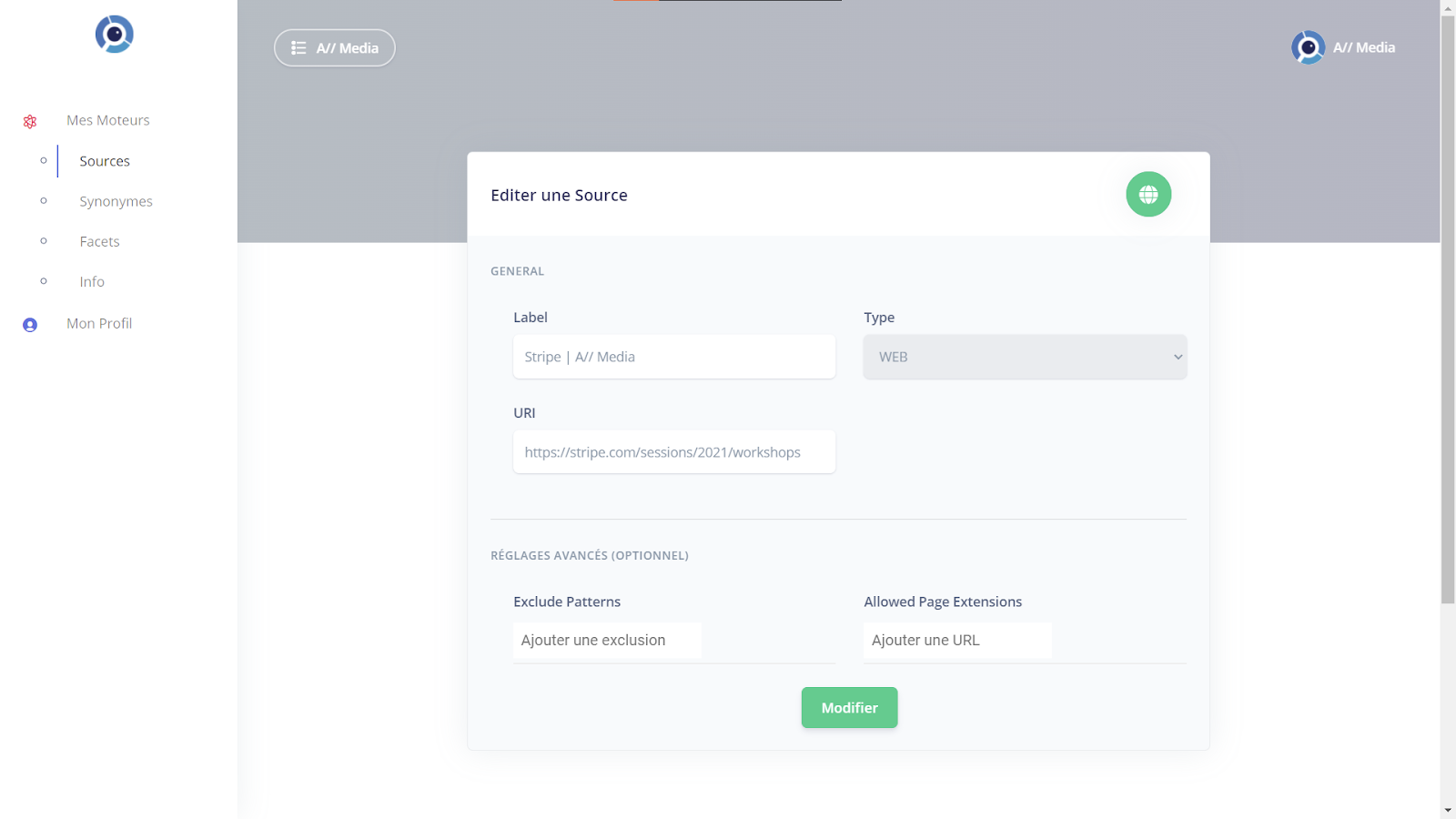
Once the source is added, the web crawler will index the site data, and retrieve the media files it finds through HTML tags such as <audio>, <video>… then send them to the Vosk API. This API will extract the transcripts from these files, then index them in Elasticsearch which is the core of all.site.
The user of the platform all.site can now search for terms found in the media file transcripts of the specified site:
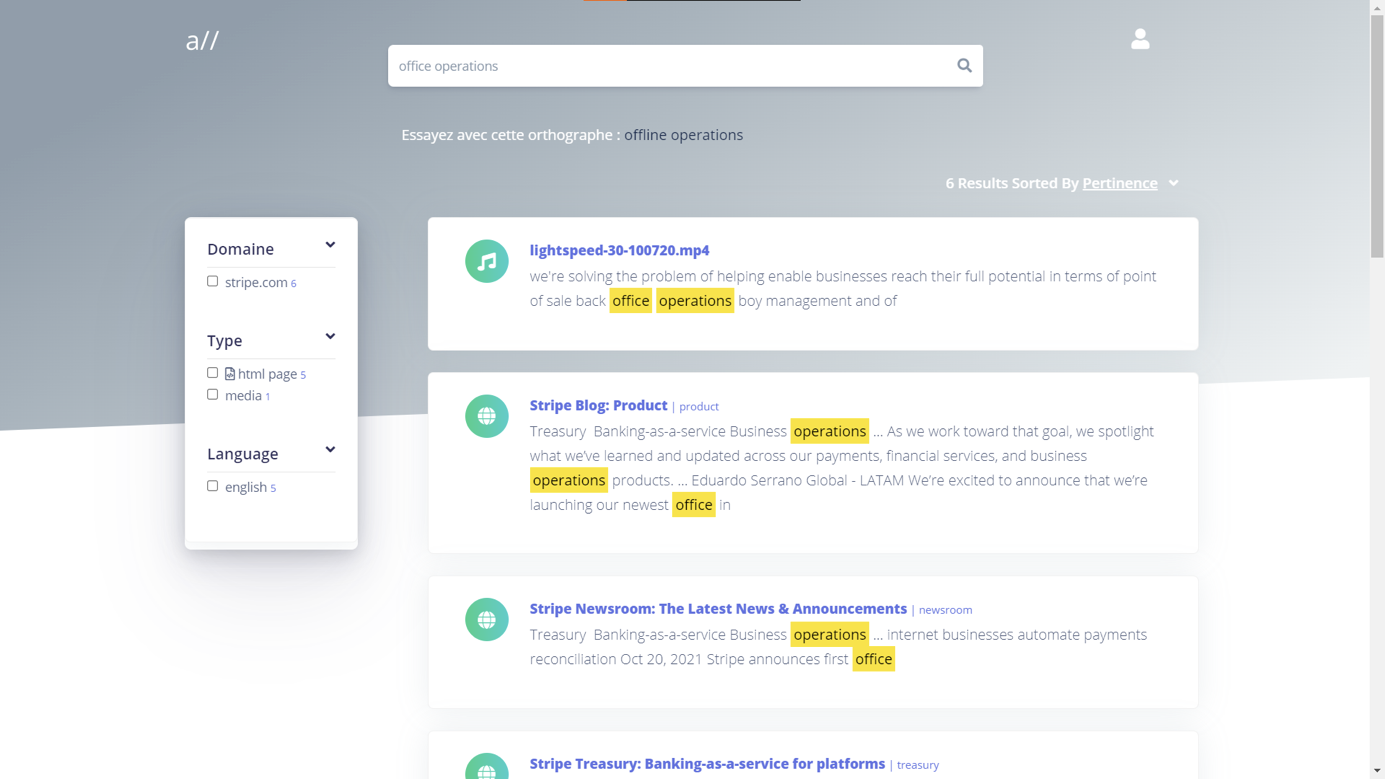
all.site in this case returns a portion of the media content transcript with the search term highlighted.
Vosk only accept “.wav” file formats. To handle this constraint, we had to use ffmpeg for conversion.
In order to recognize the dialogue, Vosk API operates on a sampling rate specified in the code. And since we don’t know in advance the sampling rate of the media files to be processed, we had to add to Vosk’s configuration these two lines:
--allow-downsample=true
--allow-upsample=true
so that Vosk can adapt the sampling rate of the received media.
A memory problem appears when the crawler finds large media files to be processed by Vosk. This problem was solved by using WebSockets to stream the media instead of sending them all at once with http post. We also configured Vosk API to clear the memory buffer using the mode Print Partial Result which allowed us to return the transcript as we went along.
The last issue encountered during the implementation was the addition of proper names in the Vosk API in order to recognize them. To add new terms to the Vosk dictionary, you have to train the Kaldi model used by Vosk or use Phonetisaurus which is a set of scripts for training speech recognition models using the OpenFst framework. The constraint of this training is that it requires a powerful machine (32 GB of RAM and 100 GB of disk space minimum).
To learn more about open source technologies around voice and for an additional demonstration of this integration in all.site, we recommend this presentation by Aline Paponaud and Lucian Precup at the conference OpenSource Experience: De la voix au texte, la puissance de l'écosystème open source. For an enhanced experience, we advise you to access it via the website SIDO-OSXP.
And finally, if you need help with your Search or Elasticsearch project, especially to add such advanced features to your search engine, feel free to contact us. Our consultants will be delighted to bring you their expertise.