
Un aperçu sur le NLP et un guide pratique sur la façon dont il peut être utilisé avec la Suite Elastic pour améliorer les capacités de recherche.
Le traitement automatique du langage naturel est un domaine fascinant qui a connu des progrès considérables ces dernières années. Lors d’un de nos événements “Search & Data”, notre collègue Vincent Brehin nous a présenté une conférence sur la facon dont le NLP est utilisé pour améliorer la recherche et l’analyse.
Dans cet article, nous allons fournir un résumé de cette présentation, explorer les bases du NLP et ses applications dans la recherche et l’analyse de données.
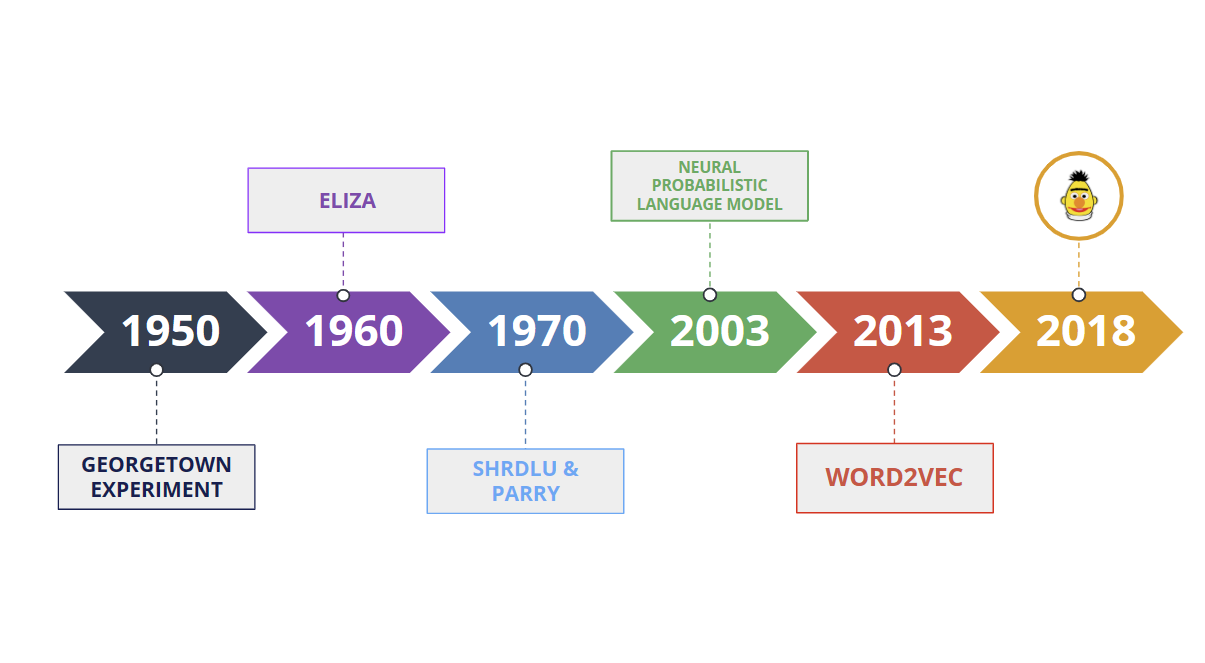
Le traitement automatique de la langue naturelle est un domaine interdisciplinaire qui combine l’informatique, la linguistique et l’intelligence artificielle. Pas étonnant qu’il existe depuis des décennies, fascinant le monde académique. En effet, le NLP a ses racines dans les premiers jours de l’informatique lorsque les chercheurs ont commencé à explorer les moyens de permettre aux machines de traiter le langage humain.
L’une des premières tentatives de développement d’un système NLP a été fait a Georgetown dans les années 1950. Des chercheurs de l’Université de Georgetown ont créé un système de traduction automatique capable de traduire des phrases simples à partir du russe vers l’anglais. Le système reposait sur un ensemble de règles que les chercheurs avaient définies manuellement.
Dans les années 1960, le premier chatbot, ELIZA, a été créé par Joseph Weizenbaum au MIT. Il a utilisé la correspondance de modèles et la substitution pour simuler une conversation avec un humain.
Puis dans les années 1970, des systèmes comme SHRDLU et PARRY ont été développés pour comprendre des commandes en langage naturel et générer des réponses appropriées.
Dans les années 2000, le NLP a commencé à évoluer vers des modèles statistiques et probabilistes. Le modèle de langage probabiliste neuronal (NPLM), proposé en 2003, utilise un réseau de neurones pour modéliser la distribution de probabilité des mots dans une phrase. Cela a permis au système de mieux gérer l’incertitude et la variabilité du langage naturel.
Plus récemment, avec l’essor du deep learning, des modèles comme Word2Vec et BERT ont révolutionné le domaine du NLP. En particulier, BERT, un modèle de deep learning, basé sur l’architecture de transformer, qui peut être affinée pour diverses tâches NLP, telles que la recherche de vecteurs, la réponse aux questions et l’analyse des sentiments.
Le traitement du langage naturel est un élément essentiel de toutes les technologie modernes de recherche. Chaque requête de recherche est exprimée en langage naturel, ce qui signifie que le moteur de recherche doit l’analyser pour interpréter notre langue. Elasticsearch peut compter sur un analyseur pour la segmentation de texte, la recherche de mots et filtrage. Ceci, utilisé en conjonction avec le “scoring vector” et l’index inversé, permettent au moteur de recherche d’identifier les documents les plus pertinents à partir de la requête de recherche de nos utilisateurs.

L’un des problèmes de la recherche par mot-clef repose sur le manque de capacité à comprendre le sens et le contexte des mots, ce qui peut entraîner des résultats non pertinents même lorsque la requête est techniquement correcte. Pour pallier ces limites, la technologie de recherche a évolué vers la “recherche sémantique”. Cette évolution a été stimulée par les progrès de l’intelligence artificielle, en particulier dans le NLP.
Les algorithmes modernes de NLP ont fait de grands progrès dans l’exécution de diverses tâches sur les données textuelles. En voici quelques applications :
NER est le processus d’identification et de classification des entités nommées dans les données textuelles, telles que les noms de personnes, d’organisations, de lieux, et d’autres entités. Les algorithmes NLP modernes utilisent Champ aléatoire conditionnel (CRF) ou Réseaux de neurones récurrents (RNN), pour analyser le contexte du texte et prédire les entités nommées. Ces modèles sont généralement entraînés sur de grands ensembles de données annotés, où les entités sont étiquetées pour que le modèle apprenne.

L’analyse des sentiments est le processus d’analyse des émotions, des opinions ou des attitudes exprimées dans les données textuelles. Les algorithmes NLP modernes utilisent des modèles d’apprentissage automatique, tels que les machines à vecteurs de support (SVM), les classificateurs Naive Bayes, ou Deep Neural Networks (DNNs), pour classer le sentiment du texte comme positif, négatif ou neutre. Ces modèles sont généralement entraînés sur de grands ensembles de données annotés, où le sentiment du texte est marqué pour le modèle puisse apprendre.

QA est la technique qui permet à une machine de répondre automatiquement à une question posée en langage naturel. Les algorithmes NLP modernes utilisent des modèles d’apprentissage automatique, tels que BERT ou GPT, pour répondre aux questions. Ces modèles sont formés sur de grands ensembles de données de questions et de réponses et sont capables de générer une réponse basée sur le contexte de la question.
Pour en savoir plus sur Question Answering, consultez cet article :
Question answering, a more human approach for our research on all.site

Si vous souhaitez effectuer des tâches de traitement du langage naturel dans votre cluster, vous devez déployer un modèle pre-entraîné approprié. La méthode la plus simple consiste à utiliser un modèle qui a déjà été affiné pour le type de tâche que vous souhaitez effectuer. C’est là que Hugging Face entre en jeu et se positionne en outil idéal.
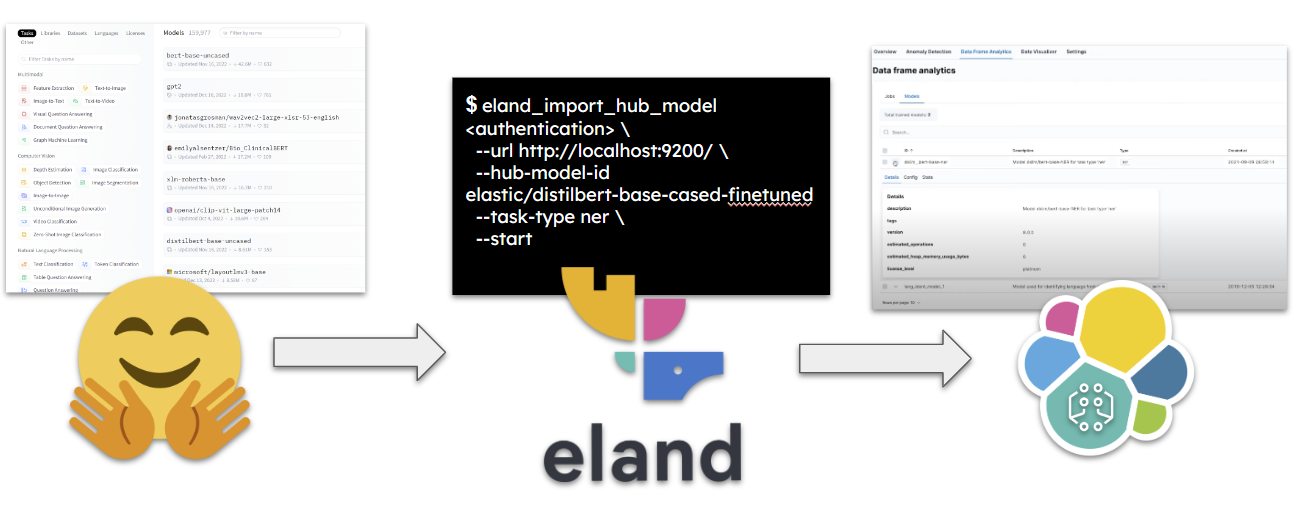
Pour télécharger et envoyer directement le modèle souhaité à notre cluster, nous pouvons utiliser le client Eland Python. Vous trouverez ci-dessous un exemple de commande pour ce processus :
eland_import_hub_model
--cloud-id <cloud-id> \
-u <username> -p <password> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner \
--start
L’utilisation de l’option –start permet de déployer le modèle directement dans notre cluster. Il est également possible d’utiliser l’API Elastic pour le déploiement de modèle. Actuellement, seuls les modèles pytorch sont pris en charge pour le déploiement.
Une fois que c’est fait, il est possible d’utiliser la fonctionnalité de “ingestion pipeline” d’Elasticsearch afin d’utiliser le modèle NLP pour l’inférence. En effet, le pipeline d’ingestion permet à l’utilisateur de prétraiter, transformer et enrichir les données avant l’indexation : l’utilisateur peut incorporer le modèle NLP dans le flux de traitement des données pour extraire des “features” à partir des données textuelles et améliorer la pertinence de la recherche. Par exemple, nous pouvons déduire l'évaluation des messages ou des tweets à l’aide d’un modèle affiné pour l’analyse des sentiments, ou nous pouvons également utiliser l’inférence à l’ingestion pour intégrer nos données dans des vecteurs denses afin d’effectuer une recherche vectorielle.
Pour ce faire, il faut :
Pour en savoir plus, vous pouvez lire comment déployer un modèle d’incorporation de texte et l’utiliser pour la recherche sémantique
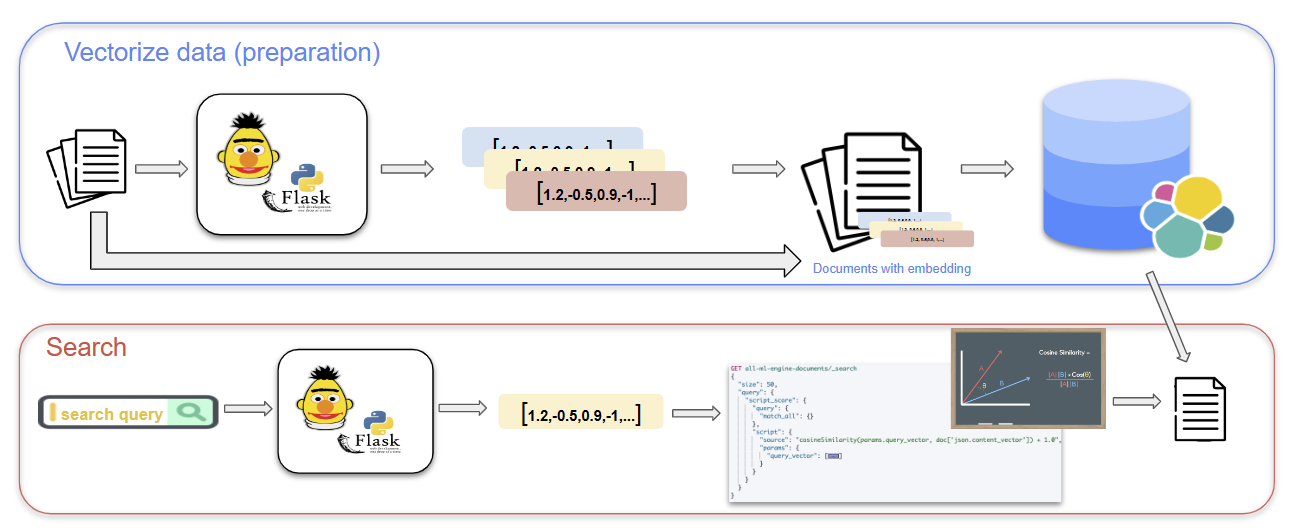
Tout cela n’est inclus que dans la licence Platinum d’Elasticsearch. Mais ne vous inquiétez pas, il est possible de faire tout ça gratuitement. Une approche consiste à utiliser un module Flask, comme “Flask-RESTful”, pour créer une API RESTful qui se connecte à Elasticsearch et implémente la recherche vectorielle.
Pour ce faire, vous pouvez commencer par vectoriser vos données textuelles utilisant un modèle d’intégration de mots pré-entrainée, tel que Word2Vec ou une version appropriée de BERT. Ensuite, vous pouvez charger les vecteurs dans Elasticsearch à l’aide du client Python Elasticsearch et créer un mapping qui inclut un champ vectoriel pour stocker les valeurs vectorielles. Une fois les vecteurs et l’index en place, vous pouvez utiliser le module Flask pour créer un endpoint qui accepte une requête et effectue une recherche vectorielle sur les documents indexés. Il s’agit de calculer la similarité vectorielle entre la requête et chaque document dans l’index et renvoyant les meilleurs résultats en fonction de leurs scores de similarité.
Le traitement du langage naturel (NLP) est devenu un aspect crucial de la recherche et de l’analyse des données. Depuis ses débuts avec l’expérience de Georgetown et le développement des premiers chatbots comme Eliza, Shardlu et Parry, le NLP a considérablement évolué au fil du temps. Aujourd’hui, des techniques NLP avancées telles que Word2Vec et BERT sont utilisées pour permettre la recherche sémantique et mieux comprendre les requêtes en langage naturel. Alors que le NLP continue d'évoluer, nous pouvons nous attendre à voir des applications encore plus puissantes et innovantes de cette technologie dans le domaine de la recherche et de l’analyse des données.