
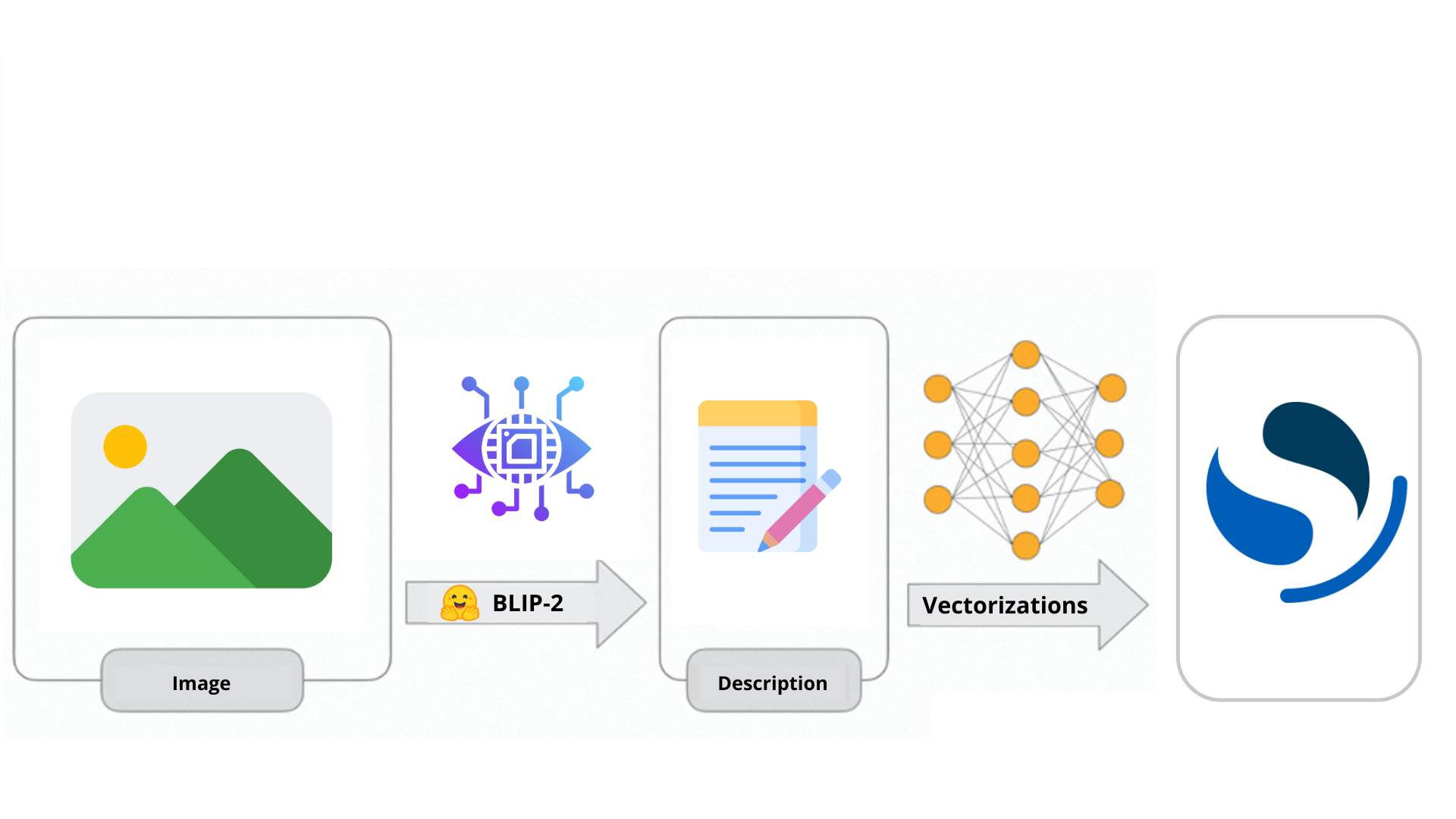
BLIP-2 est un modèle qui combine les forces de la vision par ordinateur et des grands modèles de langage. Ce mélange puissant permet aux utilisateurs d'engager des conversations avec leurs propres images et de générer du contenu descriptif. Dans cet article, nous verrons comment tirer parti de BLIP-2 pour créer des descriptions d'images enrichies, suivies de leur indexation en tant que vecteurs dans Opensearch.
Récemment, OpenAI a dévoilé les capacités remarquables de GPT-4, qui est entré dans le domaine des grands modèles de langage multimodaux. Cela signifie que, alors qu’il y a peu de temps nos interactions avec le chatbot le plus célèbre étaient limitées aux demandes textuelles, nous pouvons maintenant engager des conversations directes en utilisant notre voix ou envoyer des images pour poser des questions à leur sujet.
ChatGPT peut maintenant voir, entendre et parler
Son fonctionnement est similaire à celui de BLIP-2, un modèle open source qui peut être utilisé pour la génération de texte conditionnelle en fonction d’une image et d’une demande de texte facultative.
Dans cet article, nous allons explorer les caractéristiques de BLIP-2 et ses différences par rapport à son prédécesseur. De plus, nous verrons comment utiliser ce modèle pour générer des descriptions enrichies de nos images avant de les indexer dans notre cluster Opensearch.
Blip-2 est un modèle remarquable qui a fait d'énormes progrès dans le domaine de la compréhension de la vision par ordinateur. Il s’appuie sur les fondations posées dans l’article intitulé “BLIP-2 : Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models” de Junnan Li, Dongxu Li, Silvio Savarese et Steven Hoi. Blip-2 exploite la puissance des codeurs d’images pré-entraînés et des grands modèles de langage pour effectuer une danse complexe entre les images et le texte.
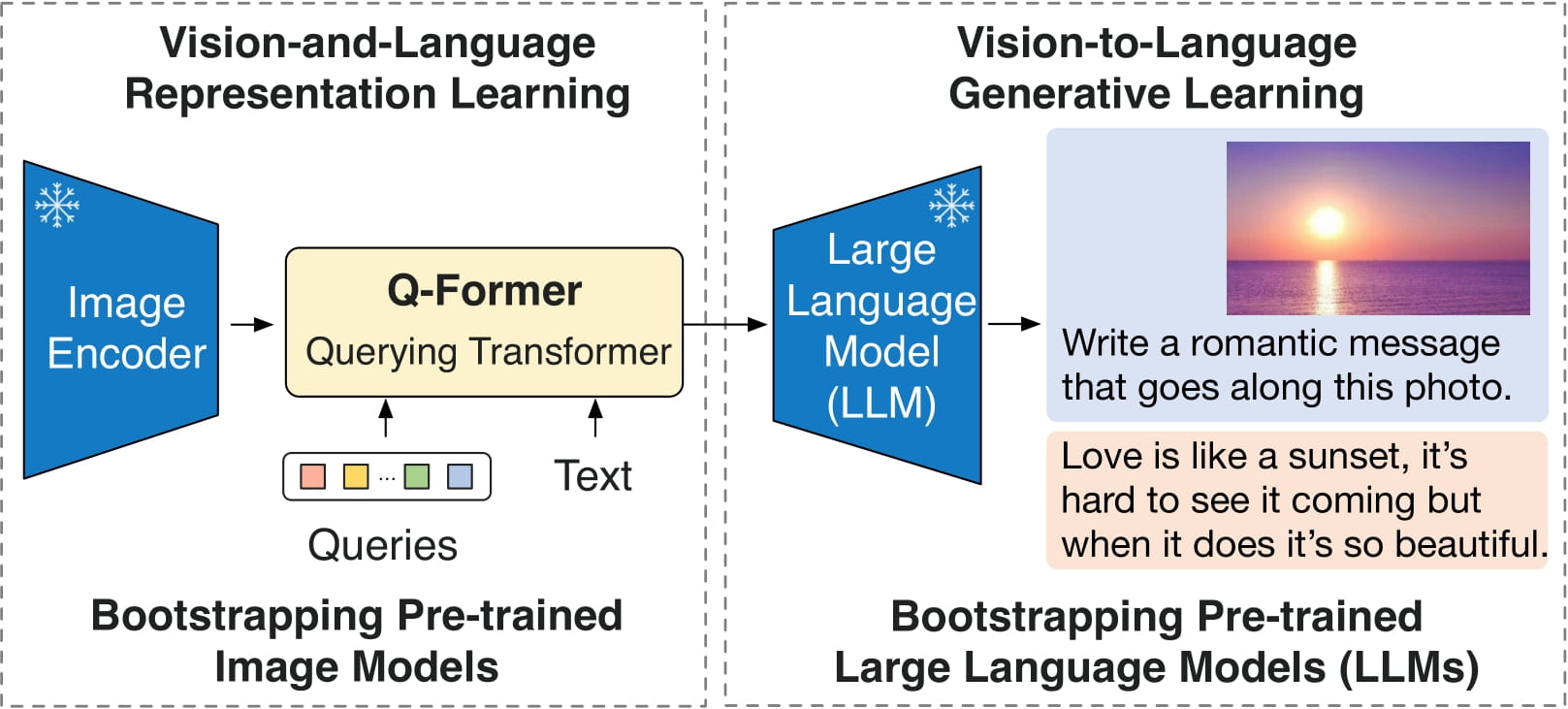
Avant d'être prêt à l’action, Blip-2 subit un processus de formation en deux étapes. Dans la première étape, Blip-2 apprend à reconnaître les objets et les scènes sur les images, et dans la deuxième étape, il apprend à comprendre la relation entre les images et le texte.
Pour comprendre comment cela fonctionne, nous allons travailler à travers des exemples :
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "Que voyez-vous ?"
qtext = f"Question : {question} Réponse :"
inputs = processor(raw_image, qtext, return_tensors="pt")
out = model.generate(**inputs, max_new_tokens=1000)
print(processor.decode(out[0], skip_special_tokens=True).strip())
Dans cet exemple, nous utilisons Blip-2 avec Opt-2 (un grand modèle de langage avec 2,7 milliards de paramètres). Nous fournissons au modèle une photo représentant une femme et son chien jouant sur la plage. Ensuite, nous interrogeons le modèle sur l’image, en demandant spécifiquement : “Que voyez-vous ?” Le modèle répond correctement qu’il y a une femme et son chien sur la plage.
Malgré le fait que les deux modèles aient été formés sur le même ensemble de données, BLIP-2 surpasse BLIP grâce à son architecture et à l’utilisation d’un LLM. Voici quelques comparaisons sur diverses tâches de vision par ordinateur :
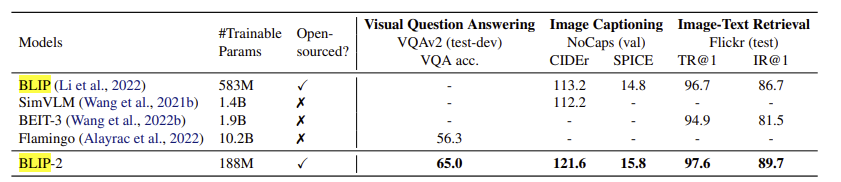
Nous avons effectué des tests pratiques en décrivant différentes images, et les résultats confirment de manière indiscutable l’efficacité des modèles dans la tâche d'étiquetage.
| Image | Description BLIP | Description BLIP-2 avec OPT2.7 comme LLM |
|---|---|---|

|
Un sac de voyage noir avec un motif à pois blancs | Un sac de voyage noir avec une poche à fermeture éclair blanche |

|
Une paire de chaussures posée sur une surface en béton | Une paire de chaussures de course vert fluo posée sur un rebord |

|
Le stylo à bille noir avec des finitions dorées | Un stylo à plume avec des finitions noires et dorées |

|
Une boîte de lait avec une étiquette blanche et verte | Everfresh lait entier 6 litres |
L’une des caractéristiques les plus remarquables de BLIP-2 est son efficacité exceptionnelle pour répondre aux questions visuelles. Avec ce modèle, nous pouvons poser des questions sur divers aspects d’une image, ce qui s’avère inestimable pour extraire des informations. Par exemple, nous pouvons demander la marque des chaussures (le modèle identifie correctement celles de la photo comme des Saucony), demander la couleur des objets dans la scène ou demander d’autres détails spécifiques qui pourraient être utiles pour l’indexation.
Une fois que les descriptions de l’image sont générées, les indexer en tant que vecteur est chose aisée. Pour l’incorporation de vecteurs, nous avons décidé d’utiliser le modèle “all-MiniLM-L12-v2”, qui est suffisamment efficace et relativement peu volumineux.
La première chose que nous devons faire est d’importer le modèle, qui s’exécutera sur notre nœud d’apprentissage automatique dédié.
POST /_plugins/_ml/models/_upload
{
"name": "huggingface/sentence-transformers/all-MiniLM-L12-v2",
"version": "1.0.1",
"model_format": "TORCH_SCRIPT"
}
Ensuite, nous pouvons créer un pipeline qui utilisera le modèle pour générer la sortie appropriée, qui est un vecteur de 384 dimensions. Chaque dimension de ce vecteur déterminera la position du document dans l’espace vectoriel. En d’autres termes, le vecteur définit le document en fonction de certaines caractéristiques.
PUT _ingest/pipeline/nlp-pipeline
{
"description": "Pipeline de recherche neuronale pour vectoriser la description de notre image",
"processors" : [
{
"text_embedding": {
"model_id": "GyNHmYoB6VptOom2kytA",
"field_map": {
"image_description": "image_description_vector"
}
}
}
]
}
Notez que field_map indique l’association entre le champ ‘image_description’ et le champ ‘image_description_vector’. Lorsque nous créons notre index, il est nécessaire de spécifier le deuxième champ, celui utilisé pour stocker le vecteur en tant que “knn_vector”. De plus, il est obligatoire de définir la dimension correcte pour le champ, qui dépend du modèle que nous utilisons : 384 dans notre cas, puisque nous utilisons le modèle all-MiniLM-L12-v2.
{
"settings": {
"index.knn": true,
"default_pipeline": "nlp-pipeline"
},
"mappings": {
"properties": {
"image_description_vector": {
"type": "knn_vector",
"dimension": 384,
"method": {
"name": "hnsw",
"engine": "lucene"
}
},
"image_description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
Une fois cela fait, chaque fois que nous indexerons la description générée à partir de nos images en utilisant Blip-2, elle sera stockée sous forme de texte dans le champ “image_description”, et sous forme de vecteur dans le champ “image_description_vector”, ce qui nous permettra d’effectuer à la fois une recherche sémantique et une recherche vectorielle.
Nous nous trouvons au cœur d’une ère de transformation où les technologies de l’apprentissage automatique et de la recherche avancent à un rythme stupéfiant. L'émergence des grands modèles de langage (LLM) et de la recherche vectorielle façonne l’avenir de la recherche de manière profonde, en conduisant les changements. Dans ce panorama, Blip-2 représente non seulement une étape importante dans le parcours de la compréhension de la vision par ordinateur, mais aussi une avancée significative vers l’avenir de la recherche.