
Un guide pratique sur l'importation et l'utilisation de modèles NLP dans OpenSearch pour l'analyse et l'inférence de texte dans vos flux de recherche et d'analyse.
Dans notre article précédent, nous avons exploré la mise en œuvre du traitement du langage naturel (NLP) dans Elasticsearch. Maintenant, plongeons-nous dans le monde du NLP dans OpenSearch.
En tant que fork d’Elasticsearch, OpenSearch propose toute une gamme de fonctionnalités améliorées de NLP, en s’appuyant sur les fondations héritées de Lucene. Il est essentiel de comprendre les différences entre ces deux plateformes et les fonctionnalités supplémentaires offertes par OpenSearch.
Dans cet article, nous examinerons de plus près le processus de téléchargement et d’importation de modèles NLP dans OpenSearch. Ainsi, vous débloquerez le potentiel d’utilisation de modèles pour une analyse avancée de texte et des inférences.
Pour utiliser des modèles de NLP dans OpenSearch, nous devons les télécharger et les importer dans le système. OpenSearch prend en charge les modèles aux formats TorchScript et ONNX. Nous avons deux scénarios à prendre en compte : télécharger un modèle depuis Hugging Face ou télécharger un modèle personnalisé.
Téléchargement d’un modèle depuis Hugging Face : Si le modèle NLP souhaité est disponible dans la bibliothèque Hugging Face et qu’il est compatible avec OpenSearch, nous pouvons le télécharger directement en utilisant la requête API suivante :
POST /_plugins/_ml/models/_upload
{
"name": "huggingface/sentence-transformers/all-MiniLM-L12-v2",
"version": "1.0.1",
"model_format": "TORCH_SCRIPT"
}
Malheureusement, seul un sous-ensemble des modèles disponibles dans Hugging Face sont compatibles avec cette méthode. Vous pouvez trouver une liste des modèles compatibles ici : supported pretrained models
Téléchargement d’un modèle personnalisé : Si vous disposez d’un modèle NLP personnalisé qui n’est pas disponible dans la bibliothèque Hugging Face, vous pouvez préparer le modèle en dehors du cluster OpenSearch et suivre ces étapes pour le télécharger et l’importer :
POST /_plugins/_ml/models/_upload
{
"name": "all-MiniLM-L6-v2",
"version": "1.0.0",
"description": "test model",
"model_format": "TORCH_SCRIPT",
"model_config": {
"model_type": "bert",
"embedding_dimension": 384,
"framework_type": "sentence_transformers"
},
"url": "https://github.com/opensearch-project/ml-commons/raw/2.x/ml-algorithms/src/test/resources/org/opensearch/ml/engine/algorithms/text_embedding/all-MiniLM-L6-v2_torchscript_sentence-transformer.zip?raw=true"
}
Une fois le modèle NLP téléchargé, l'étape suivante consiste à le charger en mémoire pour le déployer sur les nœuds ML. Pour ce faire, vous devez obtenir l’identifiant du modèle (model_id), qui peut être récupéré à l’aide de l’endpoint _ml/tasks.
Pour charger le modèle, vous pouvez utiliser l’appel API suivant :
POST /_plugins/_ml/models/<model_id>/_load
Par défaut, les modèles se chargent initialement sur les nœuds ML. Cependant, si vous souhaitez vous assurer que les modèles se chargent uniquement sur les nœuds ML, vous pouvez définir la configuration plugins.ml_commons.only_run_on_ml_node sur true.
Avec le modèle NLP téléchargé et importé dans OpenSearch, vous pouvez l’utiliser pour effectuer des inférences sur des données textuelles. Le plugin ML Commons fournit le “predict” API qui vous permet de faire des prédictions à l’aide des modèles NLP importés.
Une fois que vous avez obtenu l’ID du modèle choisi, vous pouvez effectuer une requête POST vers l’endpoint _plugins/_ml/_predict/<nom_de_l’algorithme>/<id_du_modèle>, en fournissant les données d’entrée nécessaires pour l’inférence. Le format exact du payload et des données d’entrée dépend du modèle NLP spécifique et de la tâche sur laquelle vous travaillez. Référez-vous à la documentation ou aux exemples du modèle pour obtenir des indications sur le format des données d’entrée.
Par exemple :
POST /_plugins/_ml/_predict/text_embedding/WWQI44MBbzI2oUKAvNUt
{
"text_docs":[ "A2lean uses opensearch"],
"return_number": true,
"target_response": ["sentence_embedding"]
}
Si le modèle fonctionne comme prévu, il peut être intégré de manière transparente dans le flux de travail de recherche en utilisant le plugin Neural Search.
Cela peut être réalisé en suivant ces étapes :
Créez une pipeline Neural Search en utilisant l’endpoint PUT _ingest/pipeline/<pipeline_name>. Spécifiez le nom de la pipeline et fournissez les champs de requête nécessaires, tels que la description et l’ID du modèle, qui doivent être indexés dans OpenSearch avant d'être utilisés dans Neural Search. Un exemple de requête est le suivant :
PUT _ingest/pipeline/nlp-pipeline
{
"description": "An example neural search pipeline",
"processors" : [
{
"text_embedding": {
"model_id": "bxoDJ7IHGM14UqatWc_2j",
"field_map": {
"passage_text": "passage_embedding"
}
}
}
]
}
Créez un index pour l’ingestion où le mapping est aligné avec la pipeline spécifiée et définissez l’option d’index “index.knn” sur true pour activer les champs de vecteurs k-NN. Un exemple de requête pour créer un index est le suivant :
PUT /my-nlp-index-1
{
"settings": {
"index.knn": true,
"default_pipeline": "<pipeline_name>"
},
"mappings": {
"properties": {
"passage_embedding": {
"type": "knn_vector",
"dimension": int,
"method": {
"name": "string",
"space_type": "string",
"engine": "string",
"parameters": json_object
}
},
"passage_text": {
"type": "text"
}
}
}
}
Ingestez des documents dans Neural Search en envoyant une simple requête POST vers l’index correspondant. Par exemple:
POST /my-index/_doc
{
"passage_text": "Hello Adelean"
}
Une fois la partie d’indexation terminée, il est possible de rechercher les documents en
utilisant le modèle pour convertir la requête textuelle en un
vecteur. Il est également possible de combiner la recherche vectorielle avec la recherche par mots-clés.
Voici un exemple de la façon dont cela est réalisé dans OpenSearch :
GET my_index/_search
{
"query": {
"bool" : {
"filter": {
"range": {
"distance": { "lte" : 20 }
}
},
"should" : [
{
"script_score": {
"query": {
"neural": {
"passage_vector": {
"query_text": "Hello Adelean",
"model_id": "xzy76xswsd",
"k": 100
}
}
},
"script": {
"source": "_score * 1.5"
}
}
}
,
{
"script_score": {
"query": {
"match": { "passage_text": "Hello Adelean" }
},
"script": {
"source": "_score * 1.7"
}
}
}
]
}
}
}
Le Dashboard de OpenSearch et son homologue Elasticsearch, Kibana, partagent de nombreuses similitudes en ce qui concerne la gestion des modèles NLP.
Donc, si vous y êtes habitué, vous n’aurez aucun problème.
Gardez à l’esprit que la fonctionnalité de gestion des modèles est désactivée par défaut dans OpenSearch (du moins jusqu'à la version 2.6). Par conséquent, il est nécessaire de modifier le fichier opensearch_dashboard.yml et de définir ml_commons_dashboards.enabled: true pour l’activer.
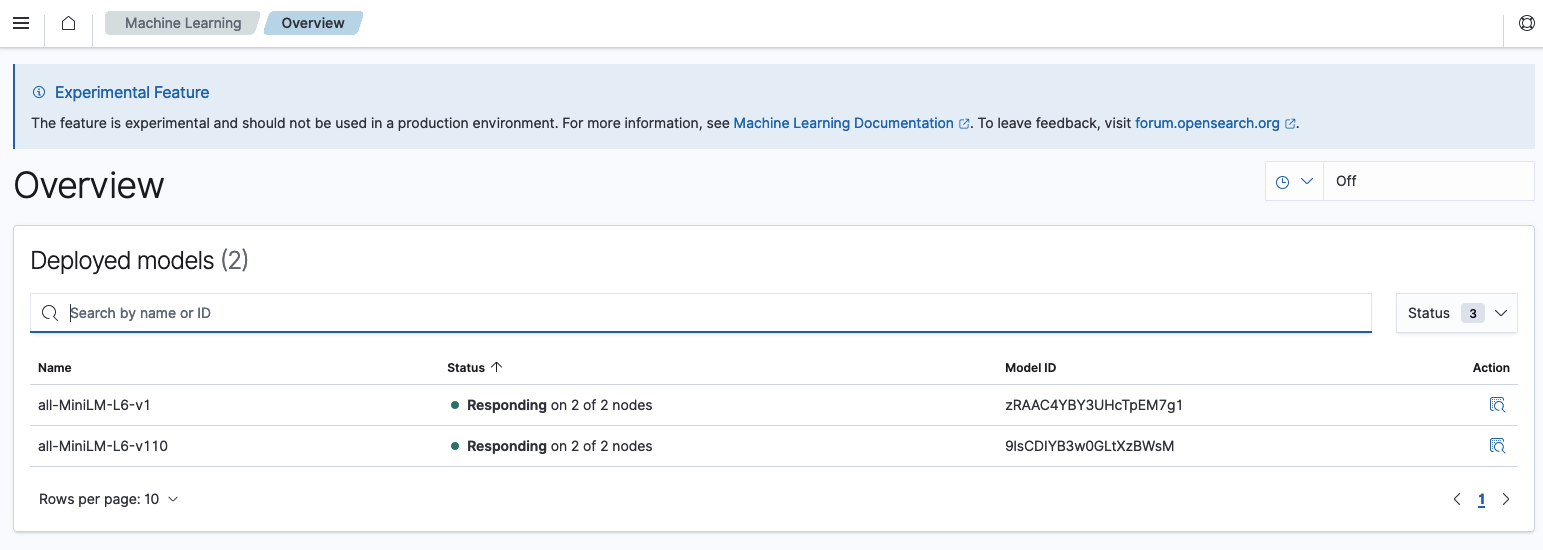
À partir du dashboard, nous pouvons également obtenir l’ID du modèle pour chaque modèle que nous avons importé.
Dans cet article, nous avons offert des informations approfondies sur les différents aspects de l’importation et du téléchargement de modèles, la création de pipelines de recherche neuronale et l’utilisation de la recherche vectorielle avec OpenSearch.
Au fur et à mesure de notre exploration de ces sujets, il est devenu évident qu’OpenSearch présente des différences notables par rapport à Elasticsearch. Chaque plateforme a ses points forts, Elasticsearch excellant dans certains domaines tandis qu’OpenSearch introduit des fonctionnalités convaincantes telles que la possibilité d’importer des modèles directement depuis le tableau de bord.
Chez Adelean, nous attendons avec impatience les nouvelles mises à jour et fonctionnalités qui seront introduites à l’avenir.