
all.site est un moteur de recherche collaboratif. Il fonctionne comme Bing ou Google mais il a l’avantage de pouvoir aller plus loin en indexant par exemple les contenus média et en organisant les données de systèmes comme Slack, Confluence ou l’ensemble des informations présentes dans l’intranet d’une entreprise.

all.site est un moteur de recherche collaboratif, il fonctionne comme Google mais il a l’avantage d’aller plus loin et d’organiser les données de Slack, Confluence et l’ensemble des informations présentes dans l’intranet d’une entreprise.
Afin d’améliorer la pertinence de notre recherche, nous avons ajouté à all.site la fonctionnalité de retrouver des médias comme des vidéos ou des podcasts en recherchant des termes qui existent uniquement dans les transcriptions de ces médias.
Le speech-to-text est une technologie qui a énormément évolué notamment à la suite de l’avènement du Machine Learning. Le speech-to-text est par exemple utilisé par les assistants vocaux comme Alexa et Siri.
Dans le cas de all.site, l’extraction des transcriptions de médias se fait à l’aide de l’outil de reconnaissance vocale Vosk API.
Vosk API est une bibliothèque open source qui fonctionne en mode offline. Elle supporte plus de 20 langues et dialectes dont l’anglais, le français, l’espagnol, le chinois… Vosk fournit la reconnaissance vocale pour les chatbots ou les assistants virtuels. La technologie peut également créer des sous-titres pour des films ou des transcriptions pour des conférences.
Vosk est une boîte à outils de reconnaissance vocale qui prend en charge de nombreuses langues. Chaque langue a son propre modèle. Pour plus d’informations voici un exemple cas d’usage de la VOSK que nous utilisons pour notre moteur de recherche collaboratif all.site.
Pour une utilisation courante, les modèles disponibles sur le site Web de VOSK suffisent amplement.
Cependant, dans un cas d’utilisation qui inclut la détection de mots propres ou caractéristiques d’une industrie par exemple (“Ruby on Rails”, “Python”, “Centrale à cycles combiné” etc.), nous devons entraîner le modèle sur ces mots spécifiques. Ce procédé est plus communément appelé « Fine-Tuning the model ». L’objectif final étant de se doter d’un dictionnaire de mots personnalisés permettant d’affiner la transcription audio d’un domaine spécifique.
L’objectif de ce processus de Fine-tuning est la détection des mots propres faisant partie d’un « jargon » lors de la transcription des contenus média. Vous pouvez retrouver notre précédent article décrivant notre retour d’expérience sur “l’indexation des transcriptions de fichiers média” en cliquant sur ce lien.
À titre d’exemple, prenons un tutoriel de programmation web. Cet audio contient des mots propres qui ne se trouvent pas dans le dictionnaire Français, e.g. Java, Python, Php, etc.
Si on a vraiment besoin de transcrire ce tutoriel correctement, il va falloir ajuster le modèle sur les mots en question pour qu’il puisse les associer à leurs phonèmes correspondants, et les détecter éventuellement.
Ci-dessus, vous trouverez la première version du transcript du tutoriel mentionné(avec un modèle par défaut sans ajustement).
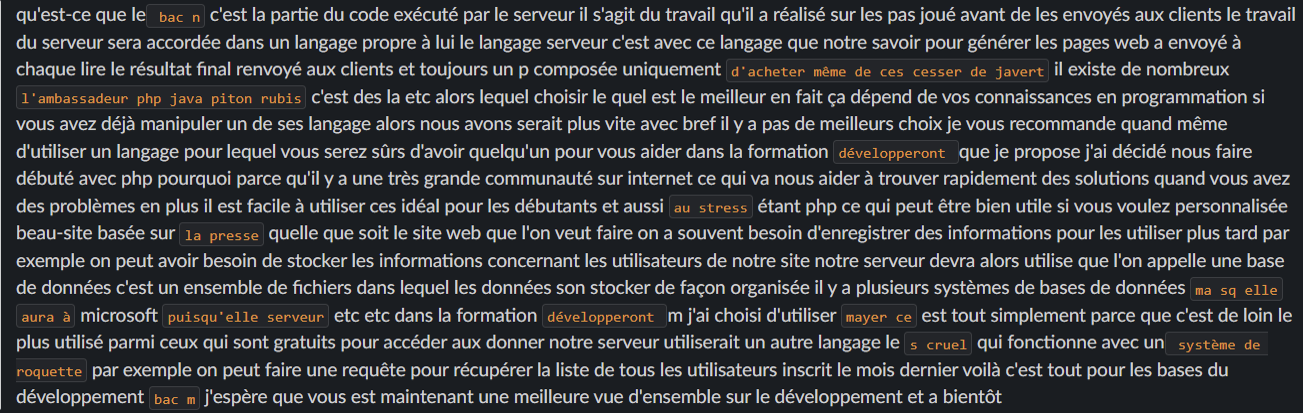
Comme vous pouvez le constater, un nombre important de mots ne sont pas détectés correctement. La solution est d’ajuster le modèle sur cette liste de mots.
Chaque modèle que nous utilisons est sous la forme d’un dossier qui contient des fichiers. Pour ajuster le modèle, il faut télécharger un package d’ajustement du modèle qui est disponible sur le site officiel de VOSK (pour plus d’information se référer à la documentation de ce sujet) Après avoir téléchargé le package de l’ajustement du modèle (appelé également compile package), ajouter dans le répertoire db/extra.txt les nouveaux mots sous condition qu’ils soient dans un contexte de phrase. Un exemple du contenu du fichier extra est comme suit :
Ensuite, comme les modèles VOSK sont supportés par KALDI, il nous faut télécharger et installer KALDI en local pour pouvoir ajuster le modèle en utilisant le « compile package ».
La meilleure façon pour installer KALDI est de suivre leur guide d’installation officiel. Phonetisaurus et SRILM sont deux dépendances requises également. Pour plus d’informations sur l’installation de KALDI et les dépendances, jetez un œil sur la dernière section de cet article.
Lorsque KALDI est bien mis en place, il ne reste plus qu'à lancer le processus d’ajustement du modèle, via l’exécution du script appelé compile-graph.sh qui existe dans notre « compile package ». N’hésitez pas à regarder s’il y a des erreurs dans l’output du processus d’ajustement.
À la fin du processus, plusieurs fichiers sont générés qui doivent être récupérés et copiés vers le dossier du modèle (rappelez-vous qu’on est actuellement dans le « compile package »). Pour les modèles larges, il faut récupérer les fichiers suivants:
Il est possible de ne pas tout copier. Le système Vosk reste fonctionnel en copiant uniquement leurs analogues dans le dossier du modèle. Il faut bien évidemment les écraser bien sûr. Pour les modèles légers, récupérer les fichiers nécessaires qui existent dans le répertoire exp/tdnn/graph et les copier dans le dossier du modèle, et écraser chaque fichier qui y existe avec les nouveaux fichiers récupérés (rappelez-vous que ce répertoire existe dans le « compile package »). Après ces étapes, le modèle est maintenant prêt pour lancer une deuxième transcription.
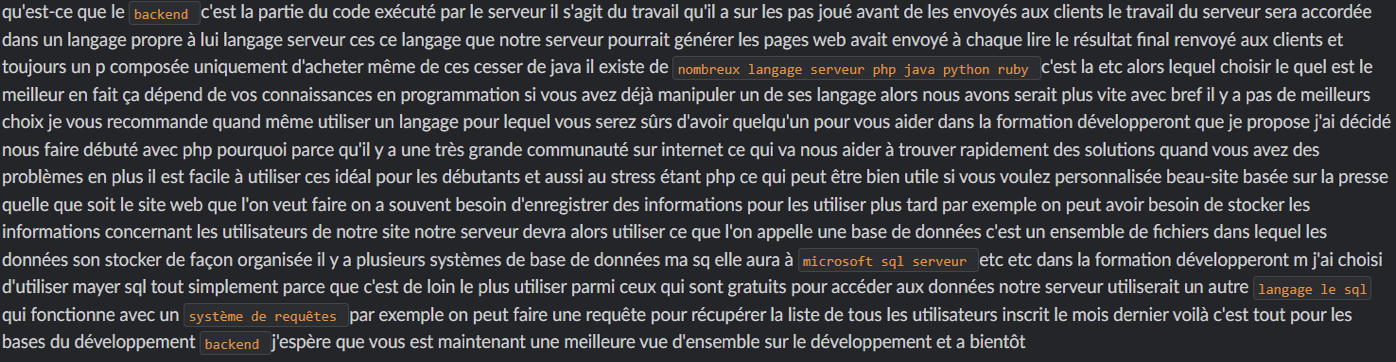
Après l’ajustement d’un modèle Français léger, on a lancé une transcription sur le même audio, vous trouverez ci-dessous le résultat :
KALDI est un prérequis de l’ajustement des modèles Vosk. Le guide d’installation mentionné précédemment dans cet article n’est pas trop détaillé. Si vous rencontrez des problèmes lors de l’installation de KALDI ou bien lors du lancement du script compile-graph.sh qui réajuste le modèle, il faut bien vérifier l’installation de KALDI et ses composants. Vous trouverez un guide d’installation détaillé vers la fin de cet article.
Pour ajuster le modèle lourd du Français (fr-0.6-linto) sur des nouveaux mots, il vous faut une configuration matérielle importante pour pouvoir compléter le processus en 15-20mn : Un serveur Linux avec un minimum de 32Gb RAM et 100 Gb d’espace disque libre. Par contre, selon le feedback du support de la Vosk, on peut faire « prune » au modèle grâce à la ligne de commande ngram. Voici un exemple de la commande complète :
ngram -order 4 -prune 1e-9 -lm db/fr.lm.gz -write-lm fr1.lm.gz
Un nouveau fichier est produit : fr1.lm.gz
Il faut le renommer à fr.lm.gz et l’écraser avec celui qui existe déjà dans db/fr.lm.gz.
Maintenant le processus d’ajustement du modèle ne devrait pas utiliser trop de ressources.
Faire un « clone » au projet KALDI sur GitHub via la commande qui est dans la doc KALDI
Lancer le script suivant : KALDI/tools/extras/check_dependencies.sh
Si vous comptez utiliser Python3
il faut exécuter la commande suivante :
touch /app/kaldi/tools/python/.use_default_python
KALDI/tools/extras/install_mkl.sh
apt-get install gfortran sox
make -j <N>
KALDI est conçu pour faire du parallélisme.
Pour booster le traitement remplacer N avec
le nombre de CPUs que vous désirez allouer pour ce processus.
pip install phonetisaurus
Aller au dossier du « compile package » et ouvrir le fichier
path.sh pour le modifier et ajouter les librairies (si besoin).
make
/KALDI/tools/extras/install_irstlm.sh
Après l’exécution du script, récupérer le contenu du fichier
tools/env.sh et l’ajouter dans le fichier path.sh du « compile package ».
apt-get install gawk
Lancer le script KALDI/tools/extras/install_srilm.sh
./configure –shared puis make -j clean depend.
Modifier la ligne 583 dans KALDI/src/configure et spécifier
à la variable MKLROOT la valeur du chemin root de MKL
installé dans votre système.
La valeur par défaut à spécifier est : /opt/intel/mkl.
Lancer la commande ./configure
make clean -j depend
ln -s /app/kaldi/egs/wsj/s5/steps ./steps
ln -s /app/kaldi/egs/wsj/s5/utils utils
KALDI/src/fstbin
KALDI/src/tree
KALDI/src/bin