
Dans cet article, nous présentons une méthode simple pour réécrire les requêtes utilisateurs afin qu'un moteur de recherche basé sur des mots clés puisse mieux les comprendre. Cette méthode est très utile dans le contexte d'une recherche vocale ou une conversation avec un chatbot, contexte dans lequel les requêtes utilisateur sont généralement plus verbeuses.

Il arrive que les requêtes qu’un moteur de recherche reçoit soient très verbeuses. Dans le contexte d’une recherche vocale ou d’une conversation avec un chatbot les requêtes reçues par le système ne sont plus de mots clés, comme habituellement dans la barre de recherche, mais des questions posées en langage parlé.
Dans ce contexte, une requête aussi simple que chocolat peut être posée de la manière, beaucoup plus verbeuses, suivante : Je recherche du chocolat s'il vous plaît. Pouvez-vous m'aider avec cela ?. Si nous utilisons un moteur de recherche classique, fonctionnant avec des mots clés, nous avons a faire à beaucoup de mots de liaison ou de “bruit” dans la requête. Il faut donc idéalement réécrire la requête afin d’obtenir des résultats pertinents et non pas du “bruit” en tant que réponse de la part du moteur.
Je recherche du chocolat s’il vous plaît. Pouvez-vous m’aider avec cela ?
=
text: chocolat
Il existe plusieurs manières pour traiter ces cas. Nous pouvons, bien entendu, utiliser des algorithmes et technologies très avancées dans le domaine de l’apprentissage automatique (machine learning) ou du traitement automatique du langage naturel (NLP). Mais nous pouvons également faire plus simple et parfois tout aussi efficace avec quelques astuces, bases de données et technologies Open Source.
Nous avons mis en place et retenu chez Adelean deux méthodes basées sur la technologie Elasticsearch. Une première à l’aide de la base de connaissances Wikidata et du Percolator que nous présenté au Meetup Search & Data, à la conférence Haystack et à la conférence Elastic Community Conference et allons détailler dans un article séparé.
La deuxième, encore plus simple, est détaillée ici et est basée sur Elasticsearch et les analyseurs de texte disponibles dans Elasticsearch et Apache Lucene. Nous avons utilisé cette méthode pour interfacer un moteur de recherche avec un assistant vocal et l’avons présentée à la conférence Berlin Buzzwords et à Elastic Community Conference
Voici les prérequis pour faire fonctionner cette méthode :
Dans notre exemple (voir la photo) nous avons mis en évidence les tokens (mots ou expressions) dans les situations suivantes :
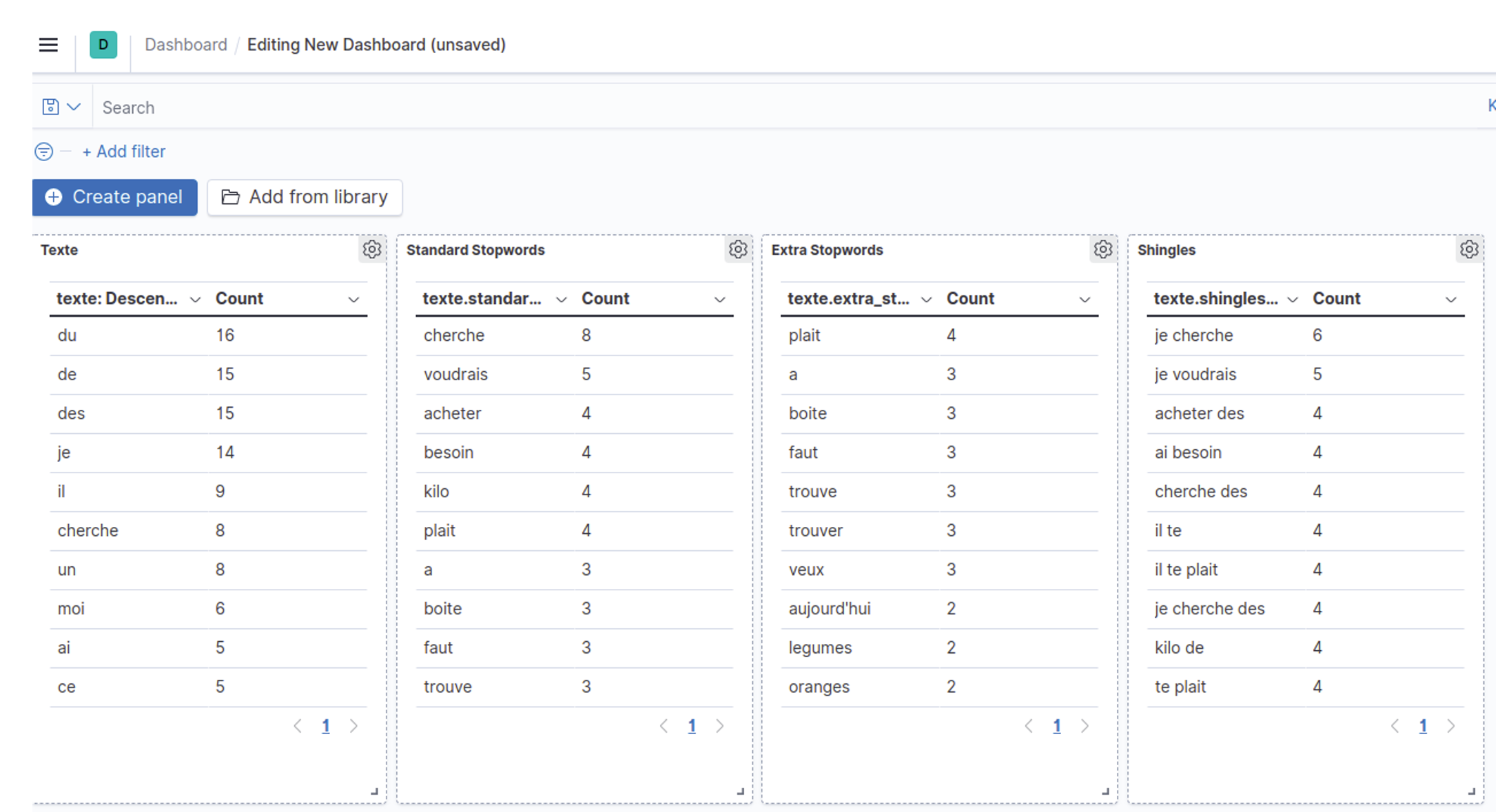
du, de, des remontent en premier et sont donc candidats à la liste des mots à exclure.cherche, voudrais, acheter, besoin ressortent.je cherche, je voudrais, j'ai besoin.Voici maintenant quelques détails techniques sur l’implémentation de ce système.
La requête Elasticsearch derrière le dashboard de l’image est similaire à celle-ci :
POST test_query_rewriting/_search
{
"size": 0,
"aggs": {
"top_terms_texte": {
"terms": {
"field": "texte",
"size": 10
}
},
"top_terms_texte_standard_stopwords": {
"terms": {
"field": "texte.standard_stopwords",
"size": 10
}
},
"top_terms_texte_extra_stopwords": {
"terms": {
"field": "texte.extra_stopwords",
"size": 10
}
},
"shingles": {
"terms": {
"field": "texte.shingles",
"size": 10
}
}
}
}
Pour qu’une requête de ce type puisse fonctionner, il faut indiquer "fielddata": true dans les différents mapping, comme nous allons le voir par la suite. Nous sommes en sécurité pour le faire car il s’agit d’un index relativement petit, contenant les requêtes utilisateur. Si nous avons beaucoup d’utilisateurs, nous pouvons mettre en place des stratégies de segmentation ou d'échantillonnage.
Nos quelques champs indexés sont définis de la manière suivante :
{
...
"mappings": {
"_doc": {
"properties": {
"texte": {
"type": "text",
"analyzer": "rebuilt_french",
"fielddata": true,
"fields": {
"standard_stopwords": {
"type": "text",
"analyzer": "rebuilt_french_stop",
"fielddata": true
},
"extra_stopwords": {
"type": "text",
"analyzer": "rebuilt_french_stop_extra",
"fielddata": true
},
"shingles": {
"type": "text",
"analyzer": "shingles",
"fielddata": true
}
}
}
}
}
}
...
}
Vous remarquerez la précision "fielddata": true, dont vous trouverez plus d’explications dans la documentation de référence Elasticsearch.
Et voici pour finir la définition des différents analyseurs :
{
...
"analysis": {
"filter": {
"french_elision": {
"type": "elision",
"articles_case": true,
"articles": [
"l", "m", "t", "qu", "n", "s", "j", "d", "c",
"jusqu", "quoiqu", "lorsqu", "puisqu"
]
},
"french_stop": {
"type": "stop",
"stopwords": "_french_"
},
"extra_stop": {
"type": "stop",
"stopwords": [
"cherche",
"acheter",
"besoin",
"voudrais",
"kilo"
]
},
"shingle": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 2,
"output_unigrams": false
}
},
"analyzer": {
"rebuilt_french": {
"tokenizer": "standard",
"filter": [
"french_elision",
"lowercase",
"asciifolding"
]
},
"rebuilt_french_stop": {
"tokenizer": "standard",
"filter": [
"french_elision",
"lowercase",
"asciifolding",
"french_stop"
]
},
"rebuilt_french_stop_extra": {
"tokenizer": "standard",
"filter": [
"french_elision",
"lowercase",
"asciifolding",
"french_stop",
"extra_stop"
]
},
"shingles": {
"tokenizer": "standard",
"filter": [
"french_elision",
"lowercase",
"asciifolding",
"shingle"
]
}
}
}
...
}
Nous retrouvons notamment notre définition de mots de liaison “métier” dans le token filter extra_stop ainsi que notre configuration du token filter shingle
Nous avons décrit dans cet article une méthode simple pour identifier les mots de liaison (“stop words” ou “bruit”) dans les requêtes provenant d’un assistant vocal ou d’un chatbot et à destination d’un moteur de recherche classique basé sur les mots clés.
Nous vous avons partagé tous les détails et références pour l’implémentation d’un prototype dans votre environnement, mais si vous souhaitez avoir notre accompagnement n’hésitez pas à nous solliciter via l’onglet Contact. Les consultants et développeurs Adelean peuvent vous accompagner pour tous vos projets moteur de recherche dans le cadre d’un assistant vocal, d’un chatbot ou dans un contexte général.