
On the occasion of this year's edition of Voxxed Days CERN, the iconic Science Gateway in Meyrin transformed once again into a gathering place for software developers, architects, and tech enthusiasts. This one-day event, part of the global Voxxed Days series, focused on software craftsmanship, security and, of course, AI.

It wasn’t long ago that a small delegation from Adelean traveled to Switzerland to participate in the 2026 edition of Voxxed Days CERN. The event took place in Meyrin, at the CERN science hub, one of the world’s most important research centers for particle physics.
We had the opportunity to visit part of the research center, and in particular ELENA, the Antiproton Decelerator that allows antiprotons to be captured and made to collide, in order to measure the characteristics of antimatter. But we are computer scientists, not physicists, and the main reason that brought us there was exchanging views and experiences with specialists in our field, listening to what they had to say, with the aim of leaving with new ideas that we couldn’t wait to put into practice.

The day started with a bang, and we were immediately confronted with the very real threats lurking among the hundreds of lines of code we write every day. Soroosh Khodami reminded us that we are often just one command away from being hacked. How, you may ask? We are not so foolish as to run the first suspicious command we find on the Internet. Sure, but what if that command runs indirectly through a dependency we just installed?
Soroosh’s talk, “Are We Ready For The Next Cyber Security Crisis Like Log4Shell?” focused on supply chain attacks and on how easily a tiny vulnerability can be exploited to cause extensive damage to any organization. Let’s take this example: you create a simple Spring Boot project with a gson dependency: that’s a very common library to add to a project. You run mvn install. Somewhere else, a malicious actor receives a connection. But how is that possible? Well, a fake version of the dependency was published with a higher version number, and your build tool happily downloaded it (you wanted to get the latest version, right?).

We just witnessed a case of dependency confusion, one of the many kinds of attack that can affect our software supply chain.
And with AI writing code for us, it can only get worse! Fake repositories full of malicious code are popping up like mushrooms to perform LLM poisoning; hundreds of thousands of models on Hugging Face are showing suspicious behavior; we come into contact with fake packages that appear reliable, with artificially high download numbers; and then there’s prompt injection, and typo squatting (have you ever thought that there is only one letter difference between “colorful” and “colourful”?)… In short, the danger is more real than ever.
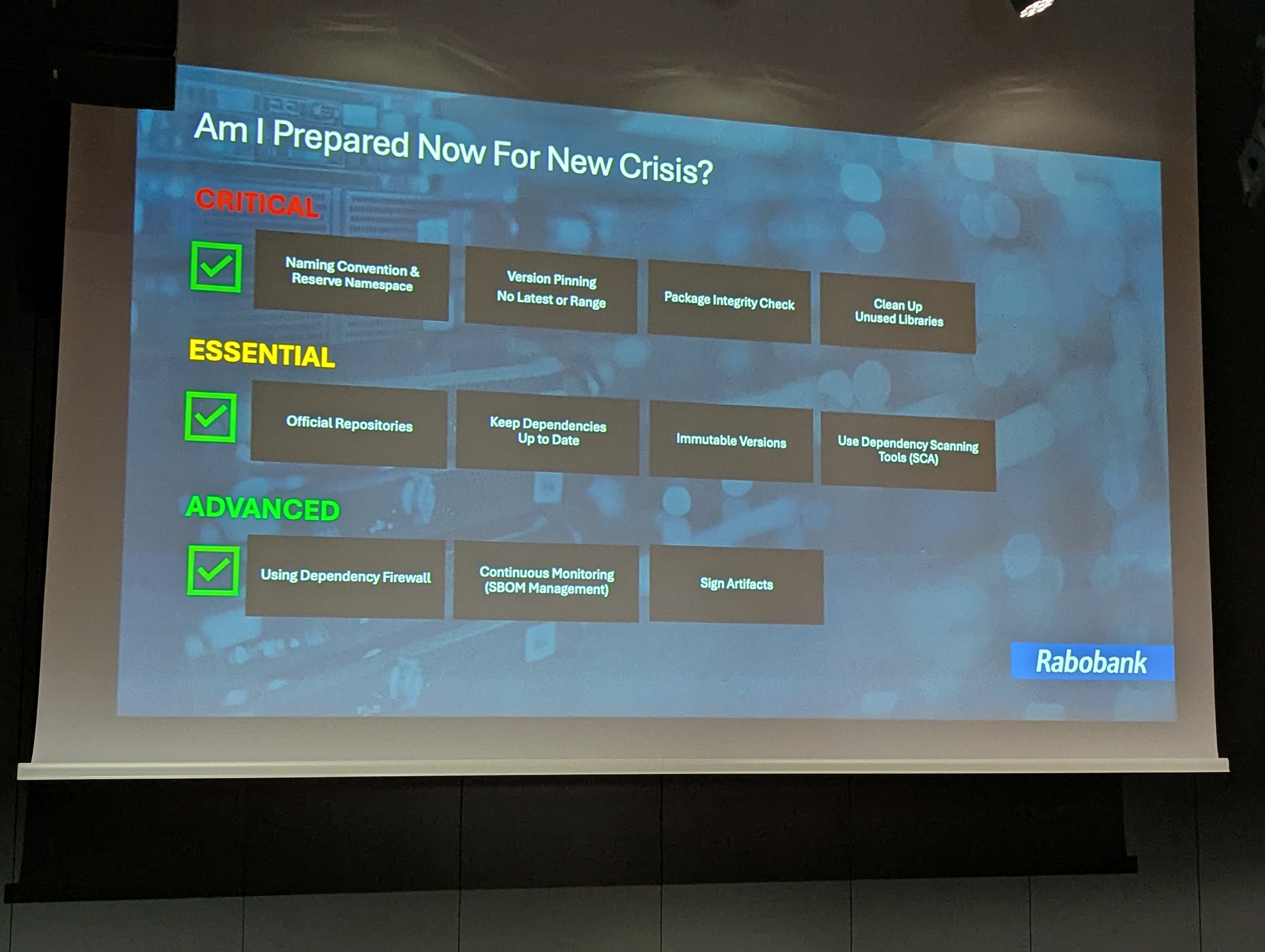
So, what can we do? Soroosh suggests three levels of measures, from the simplest (but urgent and critical) to the most sophisticated and complex to implement.
The critical ones (to be implemented as soon as the talk is over, just to be clear on the level of urgency) include
Then, there are the essential ones, which require a bit more time to implement, like
Last but not least, the advanced long-term precautions imply
In the end, when a crisis hits, most companies tend to panic, scrambling to know which parts of their systems are affected, and who to call to fix it. SBOMs are very useful in these situations: they immediately allow us to know which applications are affected, trace the vulnerable component, identify who introduced it, and decide what to fix first. And that last part is very important: severity is not the same as priority, and critical vulnerability in an isolated internal tool may matter less than a medium-severity flaw in a public-facing service.
So, are we ready the next big supply chain attack? Probably not, but with these best practices we might have a chance of surviving it.
In the early afternoon, the stage belonged to our colleague Pietro Mele, who managed to give two different talks for two different audiences, without changing the core subject: semantic search.
The first session was aimed at newcomers, the kind of audience that has heard the word “vector” often enough to nod along but not always enough to explain it. Pietro walked them through the foundations: how in semantic search everything (from the indexed documents inside the search engine, to the user query) is turned into a vector; how vectors are compared inside a vector space; why semantic search is fundamentally different from lexical search, and what limits of the latter it can overcome.
If you too are new to the subject and want to know more, you can check this article on semantic vectors

Just enough time to grab a quick lunch, and Pietro was back on stage. This time, the subject matter was more advanced: he explored the challenges of bringing a large-scale semantic search system into production, one handling over a billion vectors. More specifically, the presentation was a concentrated overview of the fundamental concepts required to effectively manage semantic search engines at scale, from vectorization to indexing and retrieval.
Among the key points, Pietro explained how the latest CAGRA integration in both OpenSearch and Elasticsearch improves performance for semantic search workloads. Indeed, with GPU handling the heavy lifting of vectorization and vector processing, the CPU is freed from performing most of the vector computation work, allowing it to focus on other tasks. At the same time, GPU‑based processes run much faster and more efficiently than CPU for vectorization.
Another feature highlighted, which also demonstrates the importance of improvements for Elasticsearch and OpenSearch, is the entirely new option to not store the _source field by default when working with vectors. This applies to Elasticsearch 9+ and OpenSearch 3+ and offers the advantage of not storing vectors more times than necessary, freeing up precious resources. Of course, in case of reindexing, recovery, or explicit _source requests, vectors are rehydrated from their internal format.
The biggest news on both the OpenSearch and Elasticsearch fronts comes from search optimization. We have already know about various quantization techniques: scalar, product, and binary, all supported by both search engines, which significantly reduce computational costs. Now, things go even further: quantization is being implemented with on-disk vectors, enabling fast and cost-efficient semantic search directly from disk.
A prime example is the newest disk_bbq format, recently presented by Elastic and generally available from Elasticsearch 9.2 (with an enterprise license). It leverages IVF and better binary quantization, using a two-stage retrieval process with reranking on a more precise vector format to boost recall. On the OpenSearch side, similar techniques are available, such as Disk Memory Search and Memory Optimized Search.
We’ll be discussing these features and much more at the upcoming OpenSearchCon EU conference in Prague, next April, so make sure you don’t miss it!
As we continued our afternoon, we encountered an interesting return of experience, in which technical challenges merged with extremely stringent constraints. Mihaela Gheorghe-Roman’s talk aimed to explain how she and her team succeeded in building a collaborative text editor designed for use in the field of military defense.
The unique area of application implies several major challenges: within a military operation, and especially in the planning phase, many units need to work together on the same document. Each user operates under a specific security clearance: even within a single document, different sections may carry different classification levels. On top of that, the application is stored on multiple servers with no Internet access and that may not even run identical versions of the software.

Many off-the-shelf editors were evaluated, but ultimately rejected: licensing models required disclosing infrastructure details, some implied mandatory code sharing, others didn’t align with the existing frontend stack or long-term maintenance expectations. So, the team chose the harder path: build it themselves.
At its core, a text editor is deceptively simple: an ordered list of characters, each with a value and a position. Insertions and deletions manipulate that list. But real documents aren’t just characters: they contain formatting, tables, images, structured objects, and in this case, security metadata attached not just to documents, but to sections within them.
Each user works on a local copy and changes must propagate instantly to everyone else. Git-style conflict resolution was dismissed early: no one in the middle of an operation should be resolving merge markers. Instead, the system should be able to resolve conflicts automatically, when possible. It’s a guessing game, with lots of maths involved: the goal is not to be perfect, but to ensure consistency and responsiveness.
If two users edit the same position at the same time, the outcome must remain deterministic. To achieve that, the application relies on Operational Transformation: the mathematical principles of commutativity and idempotency we all learned in school turn out to be extremely useful here. “Last man wins” serves as a baseline rule, but the real work happens in the transformation logic, adjusting operations based on position, context, and surrounding structure before applying them.
From there, many other challenges arose: cursor synchronization, so users can see where others are typing. Undo and redo across distributed edits. Persistence mechanisms robust enough to handle abrupt shutdowns, as in the case of devices suddenly destroyed in the field. And of course the overlay of document and section-level security constraints, with the selective redacting of individual documents or even single paragraphs within the same document.
This session proved that understanding the context remains essential for choosing the right solution, shutting down that gut feeling that you’re “reinventing the wheel” and focusing on what’s really needed in a specific scenario. And, of course, it demonstrated that maths and good strategic analysis are truly valuable allies in these complex situations.
The last talk we want to focus on was held by Jesse Kershaw, senior developer at CERN, who aimed to convince his audience that Test-Driven Development can truly help them become better developers.

The talk opened with a simple question: what is good code? The answer highlighted various characteristics: good code is correct, easy to understand, easy to change, easy to test, and efficient in its use of resources. The next question, therefore, came naturally: does TDD actually help us achieve all of that?
In the CERN auditorium, where scientific research takes center stage, Jesse framed it like a hypothesis. If we apply Test-Driven Development, will these five characteristics emerge? The live demo became the experiment.
Starting with a failing test, he built a small feature step by step, letting the red-green-refactor cycle guide each move. The speaker pointed out to us how TDD itself mirrors the scientific method almost perfectly: the failing test is the hypothesis, the implementation is the experiment, and the passing assertion is the conclusion.
Correctness was enforced immediately, because no behavior existed without a test to validate it, and testability was clearly built in by design.
But what about the last three features? Well, the tests themselves, written clearly, acted as executable documentation, reinforcing understandability. Then, because only the minimum code necessary was written at each step, the structure stayed small and adaptable, supporting change rather than resisting it. And with a safety net in place, refactoring and even performance improvements could be done confidently, encouraging the pursuit of efficiency.
The talk closed with some practical advice on how to write good tests: use built-in assertions instead of clever custom ones, write helpful failure messages, favor parameterized and data-driven tests, and don’t over-abstract your test code too early (copy and paste is your friend!)
In summary, we learned that writing good code is hard, and writing good tests is harder still. TDD doesn’t remove that difficulty, but it creates conditions where good practices are repeatedly exercised, so that even when we’re not following it we can instinctively recognize what good code looks like.
The 2026 edition of Voxxed Days CERN was a reminder of the richness and diversity that define today’s software landscape. From the urgent realities of cybersecurity and the technical depths of semantic search, to the challenges of building software for high-stakes environments and the scientific rigor of TDD, the event offered a panorama of perspectives and expertise.
The event brought together an international community of experts eager to learn, challenge, and inspire. It reminded us that the best ideas often emerge at the intersection of disciplines, and that progress is driven as much by dialogue and experimentation as by technology itself.
We left Meyrin with new knowledge and fresh motivation, and cannot wait for next year’s edition!