
Berlin Buzzwords 2025 unites leading voices in AI, Big Data, Search, and Scalable Data Infrastructure, all anchored around open-source innovation. From GPUs for LLMs to data sovereignty, from search platforms to real‑time pipelines, this is where ideas meet engineering and where tomorrow’s data landscape takes shape.

Once again this year, we had the opportunity to attend Berlin Buzzwords, a conference that stands as a benchmark for excellence in the search community. Like every edition, it was a chance to discover new technologies, connect with peers, learn from real-world use cases, and leave truly inspired.
Moreover, it was also an opportunity to share our own knowledge and contribute to the celebration of the amazing search community we’re proud to be part of. Indeed, Adelean was there with two talks.
On the first day, Lucian Precup and Giovanna Monti took the stage to explore the topic of fake news and how AI can help detect and combat misinformation in a world where information travels fast (sometimes too fast).
On the second day, Pietro Mele and Radu Pop presented a session on hybrid search, highlighting the challenges of implementing effective semantic search at scale.
Both talks, and many others, are now online on the Plain Schwarz YouTube channel.
One of the main threads of this edition was semantic search. This technology seems to be increasingly permeating search engines, steadily gaining in maturity. Many of the talks at the conference reflected this trend, showcasing real-world applications, lessons learned, and innovative approaches to implementing semantic capabilities, from retrieval-augmented generation to vector search and hybrid architectures.
In the talk “Performance Tuning Apache Solr for Dense Vectors,” Kevin Liang shared an insightful use case from Bloomberg, illustrating how their search engine supports investors in making informed decisions.
With the introduction of semantic search, Liang and his team encountered several challenges in scaling this technology. These ranged from increased latency and CPU saturation, to broader technical hurdles that required both vertical and horizontal scaling strategies. However, scaling alone wasn’t enough. To significantly improve performance, the team implemented several key optimizations:
Another critical focus was reducing memory footprint, which they achieved by quantizing vectors and avoiding storage of the original vector data.
In his talk, Dhrubo Saha demonstrated the real machine learning capabilities of OpenSearch, while also offering a glimpse into its future roadmap.
The highlight of his presentation was multi-modal search, an approach that leverages multiple types of input vectors, such as those derived from both text and images, to perform semantic and hybrid search. This capability is particularly valuable in scenarios where traditional metadata is insufficient or unavailable, enabling richer and more accurate search results.
Saha also discussed essential components that support this functionality, including model management, agent orchestration, and real-time inference. These foundational elements ensure that multi-modal search can be deployed efficiently and at scale, paving the way for more intelligent and flexible search experiences.
A key focus of Saha’s talk was the inference processor in OpenSearch, which stands out for its flexibility. It can be applied at multiple stages of the search pipeline, during indexing, at query time, and even post-search. This versatility enables a wide range of powerful applications.
For example, Named Entity Recognition (NER) models can be applied at index time to enrich documents with structured metadata. At search time, hybrid search can be enhanced with re-ranking models that refine the relevance of results. Finally, after search execution, the inference processor can be used to implement RAG, potentially in combination with connectors and large language models, to synthesize more informative and context-aware answers.
This flexible design makes OpenSearch a strong foundation for building advanced, AI-driven search experiences.
Another interesting subject was the challenge of evolving RAG into something more dynamic. In her talk, Bilge Yücel showed how combining RAG with agentic behavior allows us to create AI systems that don’t just retrieve and respond, but also plan, reason, and act.
While standard RAG pipelines are great for fact-based queries, they struggle with complex requests, requiring query decomposition, iterative search strategies, and dynamic retrieval from multiple sources to improve accuracy.
That’s when agents come into play: an AI agent is a system that autonomously pursues a goal by interacting with its environment, using tools, and adapting actions based on feedback to reach the final goal.
Agentic behavior in AI involves giving a model the ability to choose its next action by incorporating components like planning, decision-making and reasoning.
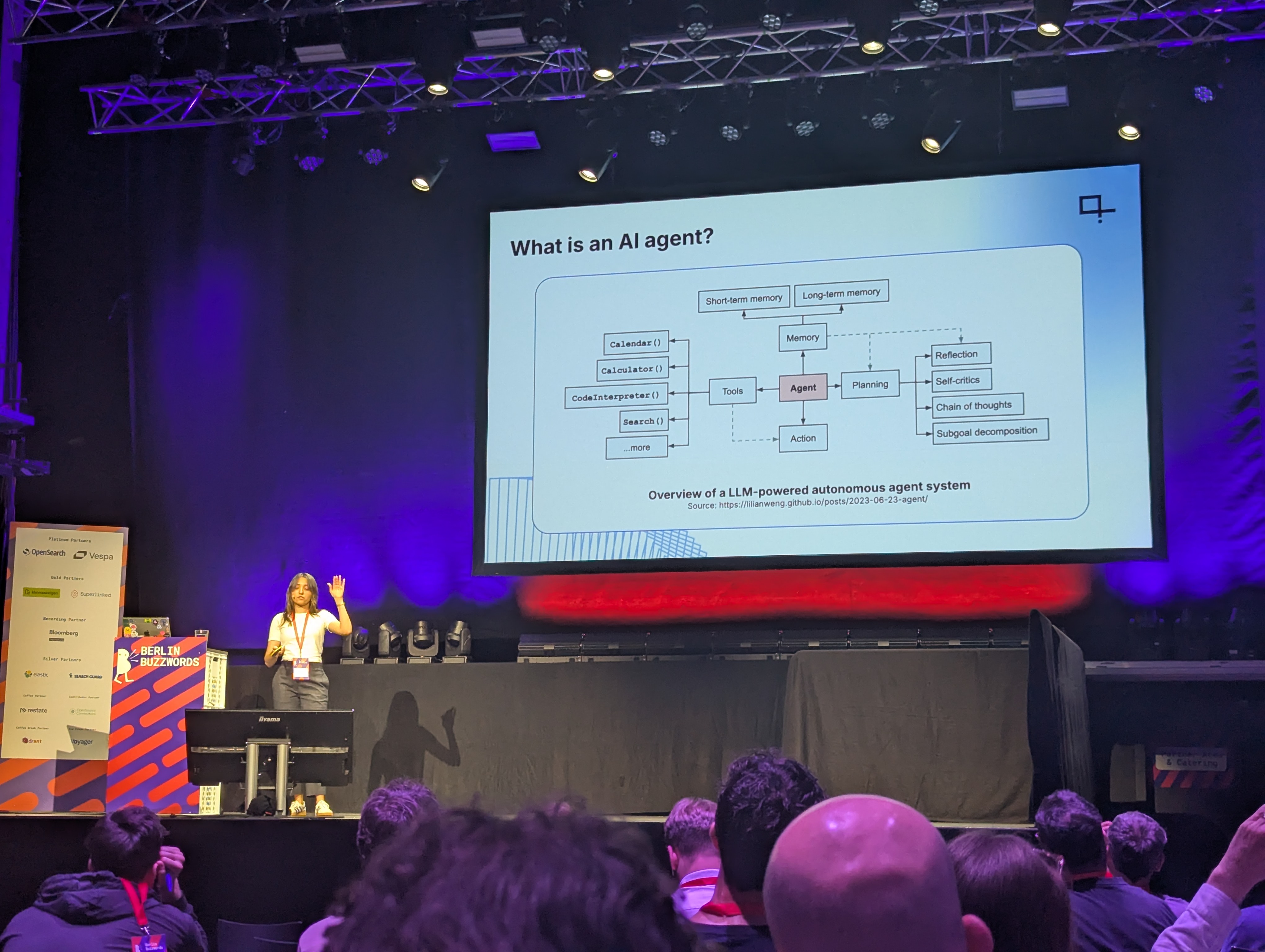
The speaker demonstrated this concept using the Haystack framework, an orchestration system for building modular agent pipelines. Her demo featured an agent built with OpenAI’s GPT-4 mini, equipped with tools like web search, document parsing and weather APIs. The agent received a query, dynamically decided which tools to call, and looped through reasoning steps to produce a structured answer.
In summary, she proved that using prompting strategies like “Let’s think step by step” and ReAct (Reason + Act), language models can be taught to refine their answers over multiple steps. The result: more intelligent, adaptable systems that are ideal for real-world enterprise applications.
As experts in the domain of E-commerce search, we couldn’t miss the talk “What You See Is What You Mean: Intent-Based E-Commerce Search” by Dennis Berger, Marco Petris, and Volker Carlguth. Their talk addressed a recurring challenge in e-commerce: how to make search results both precise and diverse, especially when users enter broad or ambiguous queries.
Their solution? A novel intent-based clustering approach, powered by large language models. Instead of relying solely on traditional hybrid search systems, which often struggle with inspirational or vague queries, their method brings in-depth query understanding to the very beginning of the search pipeline. By using LLMs to interpret the user’s intent upfront, the system can more effectively guide retrieval, clustering, validation, and presentation steps.
This technique isn’t just academic, it’s been tested at scale. The team shared how LLMs help uncover hidden meanings in queries, boosting recall while still maintaining high precision. Ambiguity is resolved early, and the results are visually organized by disambiguated meanings, reducing the cognitive overload of the “paradox of choice” and giving users clearer paths through large product catalogs.
Of course, relying entirely on LLMs would be expensive. That’s why the team also fine-tuned a BERT-based model to handle binary classification of product relevance. Their model was trained on over a million intent-product pairs for the German e-commerce market and achieved an F-score of 0.779. A modular design allows for easy model comparison, whether between fine-tuned transformers or commercial LLMs like GPT or Gemini.
Performance wasn’t the only focus. The team also looked at search optimization strategies: caching works well for popular exploratory queries like “washing machines”, while dynamic processing remains key for seasonal or less frequent ones like “Christmas decorations”.
Another finding: reducing user queries from dozens to just a few shorter, intent-driven ones makes the experience faster and more semantically aligned, albeit with slightly less diversity in results.
The presentation closed with insights from UX testing, showing that users benefited from intent-based clustering as a visual and cognitive aid. It’s a promising direction for making e-commerce search more intuitive, more intelligent, and more aligned with what users truly mean when they type.
This year’s Berlin Buzzwords wasn’t just about innovative approaches to search or agentic AI models, but it also spotlighted the human dynamics that make technical teams successful. Talks by Fatima Taj and the duo Marion Nehring & Jessie de Groot reminded us of the importance of building resilient company cultures and navigating career paths with intention.
Nehring and de Groot delivered a powerful message: great products and thriving open-source communities are not just built on tech. They’re built on people, culture, and values.
They emphasized that “people buy from people": we’re more likely to try a product recommended by a trusted peer than one advertised by a company. A premium product like Nike Airs isn’t just about materials and design; it’s about the emotional story and trust built around it. That same principle applies in open source: value is created not just in features, but in the relationships and experiences surrounding a project.
That’s why strong company values like openness, kindness, and transparency aren’t just important to internal teams; they must extend outward, shaping how users and contributors interact with your community. Some standout practices include:

Nehring and de Groot also stress that leadership must model the values they want to see. In large companies, values can easily become hollow slogans unless leaders actively live them through small, everyday actions. Whether it’s giving kind, actionable feedback or making time to truly listen to a colleague, these moments matter.
In her talk, Fatima Taj shared some advice on how she avoided being boxed into the role of the “glue”: the person who keeps the team running with supportive, but often invisible, non-technical work, like writing documentation or managing cross-team communications.
Fatima’s journey began when she became the default owner of a critical rollout process at Yelp. As the most familiar person with the project, she was naturally leaned on for updates, communication, and coordination. The visibility felt good, until it didn’t. Her time and energy were spent in spreadsheets and stakeholder calls rather than working on technical tasks. Despite being at the center of the project, her engineering role became secondary.
Reading Tanya Reilly’s article “Being Glue” sparked a wake-up call. She realized that without intervention, she risked stalling her growth by becoming the team’s unofficial project manager, rather than being recognized as a competent software engineer.
So she began a strategic shift: first, she started saying no with intention. Then she trained teammates to take on ownership of recurring tasks and documented her processes, enabling a healthier distribution of responsibilities. She also built a “brag document”, a living record of accomplishments, updated every few weeks: this helped her advocate for herself during performance reviews and kept her focused on having enough technical contributions.

Her key takeaway is that doing good work isn’t enough; you have to make the right people aware of it. Fatima’s message for managers: clarify how different contributions are valued, ensure technical and non-technical work are both recognized, and distribute team responsibilities intentionally. Her message for peers: learn to delegate, let go of control, and be unafraid to valorise your work.
Berlin Buzzwords 2025 reaffirmed why it remains a flagship event for the search and data community. This year’s edition showcased not only the growing maturity of semantic and hybrid search technologies, but also the exciting frontiers being explored, from multi-modal pipelines and agentic AI to intent-driven e-commerce and performance-optimized infrastructure.
Yet beyond the code and models, what resonated deeply was the human side of tech: how we build teams, support careers, and create inclusive, value-driven cultures that power innovation.
We left Berlin inspired, not only by the tools and trends shaping the future of search, but by the vibrant community of thinkers, builders, and leaders driving it forward. Until next year!