
Haystack is the conference for improving search relevance.

Keyword search relies on matching of search terms to text in an inverted index. Vector search is based on a neural networks model which represents objects and returns a vector. It allows you to find items with similar meaning. The process of vector search can be described using 2 fundamental notions: the vector search space and the vector search pyramid. On one hand the vector search space gives the substance and on the other hand the pyramid gives a reading grid. It uses 6 steps to build a representation of the vector search process.
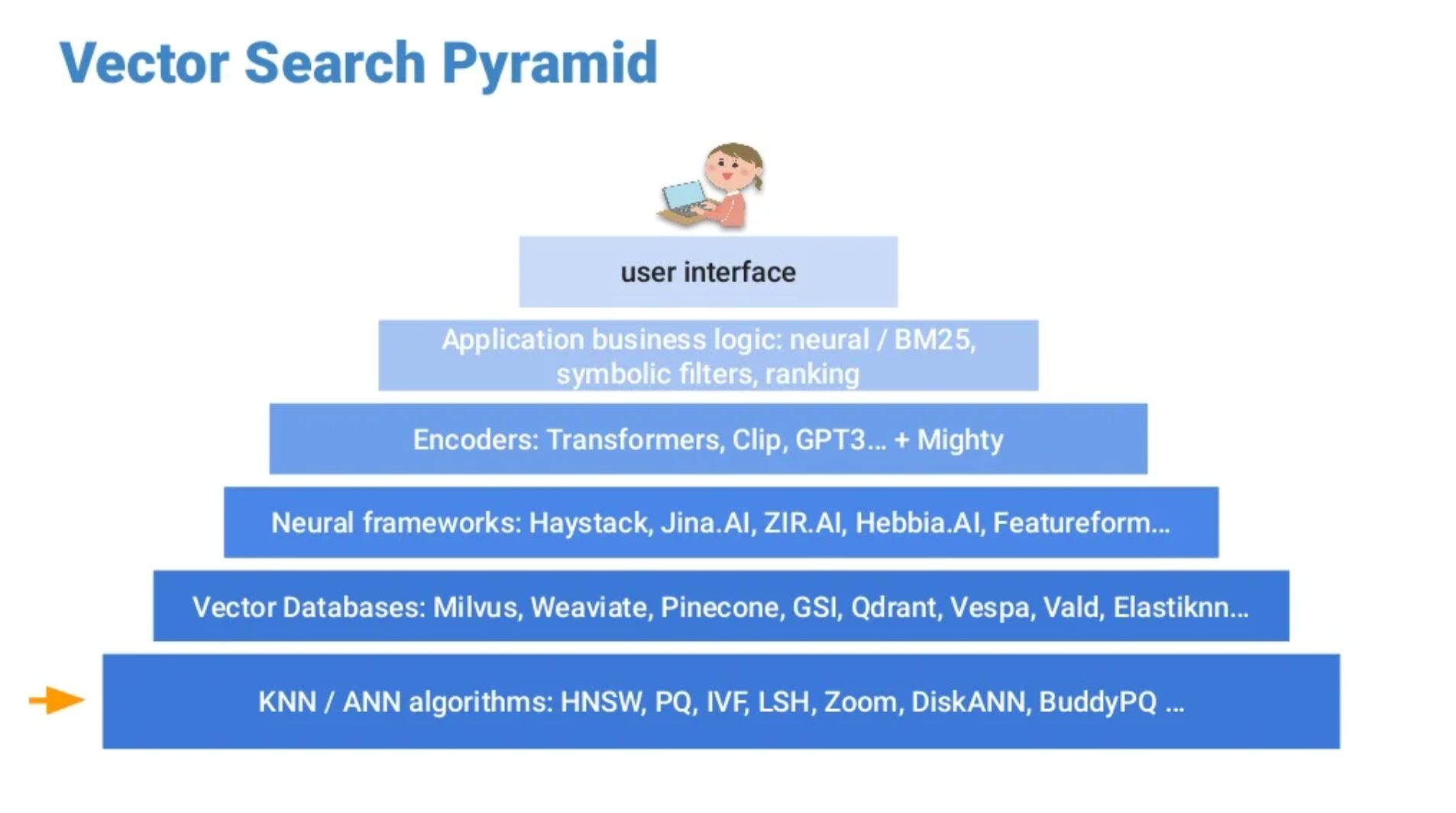
From the bottom to the top : algorithm, vector databases, neural framework, encoders, application business logic, UI.
It is useful to remember that in vector search, matching will depend on 2 main parameters : similarity and proximity of the query vector with our already stored vector. ANN algorithms (artificial neural network) also called NNs (neural nets) are used to compute systems. Product Quantization (PQ), a process of approximation, is used to reduce the memory usage of a vector. The PQ can be improved with several assignment strategies(combination, assignment tree,…), pre-rotation or generalization. The search system with inverted indexing can also be improved, the distance estimation for example.
Keyword search is based on a lexical paradigm. On another hand, vector search introduces a new paradigm : a context search paradigm. It can overcome the lexical gap (US vs USA vs United States). It respects the word order. It knows about related terms. It offers a suitable environment for multi-modal search, multilingual search, or even hybrid methods. Search will very likely turn more into data science in the future, but it still needs exploration, trying, and to get your hands dirty.
Vector search will certainly not replace everything existing. As we can see, it begins to be implemented in existing solutions. Most of the time, it will probably complete them and from time to time, it will surely occupy the foreground of specific sectors.
The talk began with an image: “the Temple of Semantic Search” and its 2 pillars. 2 main components: vector database & embedding model. Actually, pretrained models dominate the field of ML. Big models like BERT need to be adapted to fit a project needs. A solution is fine-tuning for classification. We can add a simple linear layer onto the end of a big model and fine tune that layer.
To modify a pretrained model: First, you need to collect data to adapt the model to a new domain.
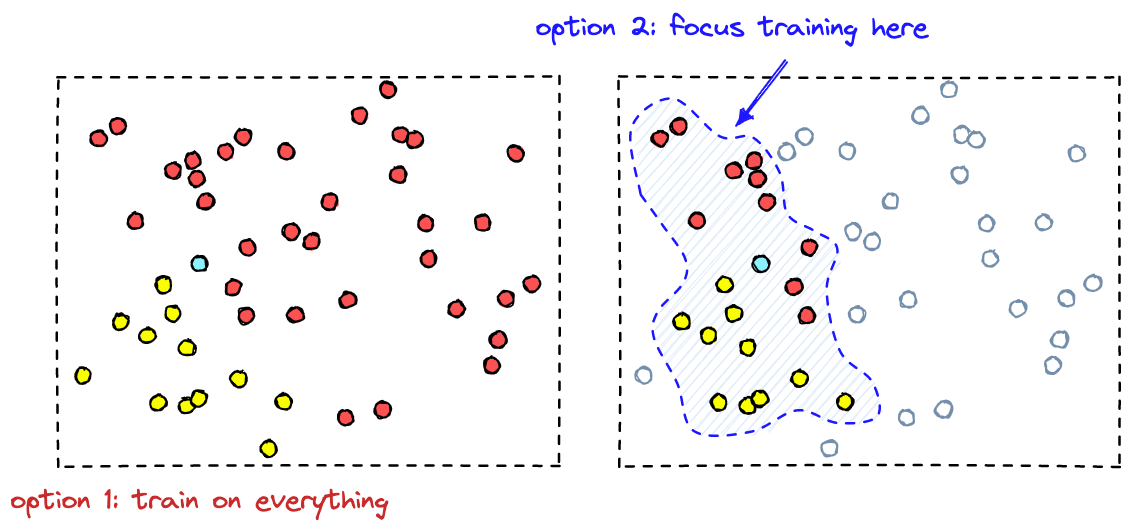
Most of the time, there is a huge amount of data. By identifying the vectors with the highest proximity we are able to focus on samples that make the best impact on the classifier performance.
Then, slog through the likely dataset and label everything. Finally, you have to fine-tune the classifier.
Fine-tuning involves a linear classifier with vectors. The classifier has to learn to align itself with vectors that we labeled as positives and move away from vectors we labeled as negatives.
The different techniques are treated according to the following pattern: context - available techniques - exceptions - treatment.
Available techniques :
Optimization techniques :
There is a subjective dimension in search which seems to be the key or cornerstone. “Ranking is not (only) search but…” MachineLearning involves a long project, no experience, resources, high risks,… VectorSearch encounters more or less the same problem in the absence of an appropriate tool.
Everything needed is a traffic history.
Then, based on the data Metarank can map it to ML features and train the ML model. And so Metarank provides an open-source personalization service. It gives a solution for personalization or dynamic ranking.
It uses metadata (like item price, tags,…), impression and interaction (user event) Metarank uses a simple API and YAML configuration The mechanism works in 4 steps as follows: compile, replay the all history, define implicit judgments, create a new ranker
The challenge is to produce a relevant ranking but not a “black box”. The customer needs its relevance to be measurable and comparable using a score.
A judgment list defines a document’s relevance for a query. It is composed of two kinds of judgments : explicit (like a research) and implicit (like an event). Then it becomes possible to evaluate the relevance of a list of results using different metrics: average precision, discounted cumulative gain, normalized discounted cumulative gain, mean reciprocal rank, expected reciprocal rank.
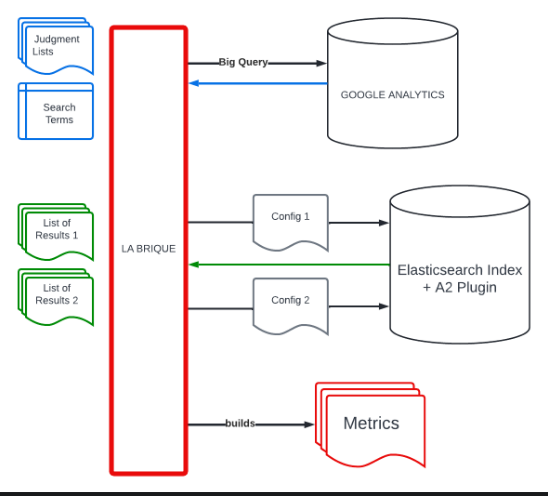
A team of non-technical users is configuring the search engine through a Business Console. Users need a tool to test and guarantee the non regression on their changes. The data change constantly and there is a very specific need for signal interpretation (for example, in an alimentary perspective, the consultation of the details linked to a product is not a positive marker oppositely to a non-alimentary perspective)
(Demo)

Neural embedding allows us to work with vectors following two major ways:
similarity & proximity.
Generally speaking, similarity learning is used when text search is not enough.
It allows for example to find similar images.
More specifically, similarity is very useful in an ML context.
Focusing on the network structure, there are pitfalls.
On one hand, pretrained models rarely provide great embeddings. On the other hand, an original model is most of the time very specialized. Pretrained models have to be modified to adapt them to a new context. And so, a fine-tuning strategy is required. Classification and regression are both basic processes used to adapt a pretrained model. Classification or regression both required similarity.
Machine Learning training involves a huge amount of data. Then an anchor, positive examples, negative examples, margin,… in brief, basic tools. It’s everything one needs to go, but from time to time, one encounters a vector collapsing problem. There are 2 major strategies to fix it: one can use similarity or proximity. And so, one can evaluate groups or pairs. Above all, it’s important to avoid catastrophic forgetting. In other words, to start from a random number (i.e. to start from the very beginning).
Semantic Text Search:
Extreme classification - E-commerce Product Categorization:
Women Of Search is a group founded on slack to offer a safe & non-judgmental place, a place to share. Behind this creation, there is an observation which reveals a problem regarding the women representation in Search.
The lack of diversification is a well known issue in software engineering. One elegant way to fix this issue is to put into place more inclusion.
To improve our behaviors, it is important to be informed and to stay aware of social usual patterns or biases like sexism, imposter’s syndrome or Glass Cliff

In practice, we have to avoid retention, inequitable advancement or salary,… And then it is important to survey results.
What a company can do:
Kramp group : B2B industry -> Kramp Hub : Kramp e-commerce Slogan: “We always do our best to make things as easy as possible for you” One of their most important challenges is linked to product findability.
When they began, the database starting point was not good. Their first approach was to deal with it manually. They finally had a kind of epiphany : “the customer is always right”.

They had a great advantage to exploit. Their customers are special: loyal, frequent, with a strong intent to buy, and they certainly master the technical aspects of the products.
Less obvious, another highlight has been the absence of legacy code. No legacy means an effort to get a well understanding of the business requirements. They have elaborated a strategy as follows : First, observe customers’ behavior. Then extract knowledge from those observations. Finally incorporate this new knowledge in search.
Then they defined a model based on Collecting events gathered in short sessions, and they applied metrics as Normalized Discounted Cumulative Gain to modify a score. They obtained session patterns, in other words behaviors’ models. To treat those information, they used tuples to associate search with events and be able to add an interaction score.
The process has been filled out to obtain a data collection setup as follows: events(from front simple event & back complex query) -> sessionizer(pipeline) -> evaluator/metrics -> data platform.
Finally, the data is ready for aggregation, frequency measure or mapping.
OTTO is a huge marketplace. Its engineers are testing neural ranking, in other words, they’re using networks.
They have elaborated a method based on semantic matching. They are applying an encoder on a query or a document to get similarities. This encoder is essentially a combination of four features and gives them a design in 4 steps: a tokenizer, an embedding model, a pooling workflow and a deep network. Unfortunately, semantic matching and relevant matching are mainly different. To overcome this issue, a common solution implements a complex ranking function, called Learning To Rank (LTR).
Machine learning techniques are used to learn from user feedback which search results are good and which are not. Here they are using a ranking model in 4 steps. They generate a context, train NN, manually label data and collect implicit feedback. At this point begins the tricky part; when carefully observed, those implicit feedbacks appear to be biased. The most notable bias is called “position bias”. Higher positioned items are more likely to be seen and thus clicked regardless of their actual relevance.
The issue increases a bit more when a training on click is implemented. A higher ranked item will implicitly get more attention and consequently receive more clicks. There are different ways to deal with a position bias. But in this case, they need to minimize the impact on users’ search experience. So they finally opt for an Unbiased Learning-To-Rank from click data. Unbiased LTR could be obtained from different ways, here they chose Inverse Propensity Weighting (IPW).
Now, on one hand, they still have to calculate the relevance, and on another hand, they have to produce a performance metric that measures the rank of the relevant documents. It means that to be effective and to correct the bias, this method involves a separated training. Finally, they will have to combine the results of both training and obtain this unbiased Neural Ranking Model they were looking for.
Position Bias Estimation for Unbiased Learning to Rank in Personal Search