
La recherche évolue plus vite que jamais, et des technologies comme OpenSearch ouvrent la voie. Dans ce blog, nous explorerons les dernières fonctionnalités d’OpenSearch, telles que les agents et le Model Context Protocol, qui débloquent de nouveaux superpouvoirs pour construire la prochaine génération d’applications RAG.
Au cours de la dernière décennie, le monde des moteurs de recherche a été secoué par un véritable séisme technologique. Nous sommes passés de moteurs basés uniquement sur des mots-clés à de véritables assistants virtuels, capables de répondre à presque toutes les questions, d’aller chercher de l’information directement sur le web (voir Perplexity) ou dans une base de connaissances personnelle (comme all.site).
OpenSearch a accompagné toute cette évolution. Aujourd’hui, sa dernière version, la 3.2, propose des dizaines de nouvelles fonctionnalités permettant de construire des moteurs de recherche plus puissants et plus intelligents.
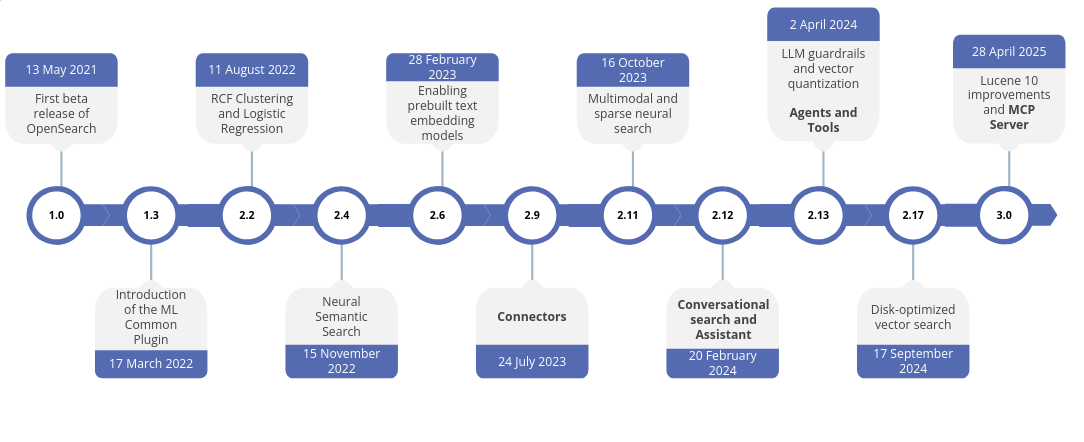
Parmi les dernières innovations, OpenSearch intègre désormais un serveur MCP. Avant de plonger dans une approche pratique et orientée implémentation, voyons plus en détail de quoi il s’agit.
Lorsque les grands modèles de langage sont apparus, beaucoup ont hâtivement prédit la fin des moteurs de recherche, en supposant qu’ils pourraient être remplacés purement et simplement. Pourtant, des limites sont vite apparues : hallucinations, absence de sources vérifiables, et besoin d’informations continuellement mises à jour, tout cela a clairement montré que la recherche conserve un rôle crucial.
C’est précisément dans ce contexte qu’est né le RAG (Retrieval-Augmented Generation).
Les systèmes RAG combinent efficacement le meilleur des deux mondes : d’un côté, ils exploitent les remarquables capacités génératives de modèles entraînés à produire du texte ; de l’autre, ils s’appuient sur la puissance des moteurs de recherche pour récupérer l’information pertinente, permettant d’ancrer les réponses dans une base de connaissances précise et fiable.
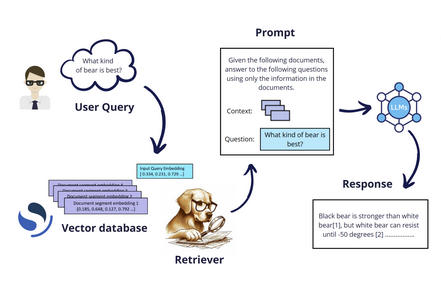
Cependant, avec le temps, des besoins sont apparus au-delà des capacités d’un RAG standard, révélant ses limites inhérentes. Par exemple, effectuer des recoupements entre plusieurs bases de connaissances pour permettre des comparaisons. Avec un RAG traditionnel, ce type de recherche est impossible, car il est contraint à une seule phase de retrieval.
Pour ce type de requête, il faut un système capable de prendre des décisions, de les affiner de manière itérative et d’effectuer des comparaisons. Il nous faut un agent, ou mieux, une fusion entre un agent et un RAG : un Agentic RAG.
Pour agir comme un agent, le LLM doit :
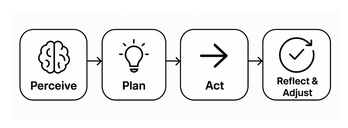
Pour développer un Agentic RAG, l’une des approches les plus populaires est le tool calling. L’idée est de fournir au LLM un ensemble d’outils qu’il peut invoquer au besoin pour répondre à la requête d’un utilisateur. Chaque outil est généralement défini par un nom, une description et un ensemble de paramètres. Cette technique est proche du framework ReAct, mais peut être vue comme une version plus structurée et aboutie.
Cette approche a permis aux fournisseurs de LLM de développer toute une gamme de connecteurs spécifiques reliant leurs modèles à divers services, par exemple un connecteur pour Gmail, un pour Slack, un autre pour Notion, etc.
Cependant, un problème est rapidement apparu : comme chaque fournisseur devait construire un connecteur dédié pour chaque service, le nombre de connecteurs (ou APIs) s’est multiplié de façon exponentielle, 10, 100, voire 1 000 connecteurs pour chaque LLM, alors même que les LLM parlaient, au fond, le même langage.
Fin 2024, Anthropic a proposé une solution : un protocole pour implémenter des APIs, une manière standardisée de décrire, de construire et d’utiliser chaque outil. MCP est né.
Pensez au MCP comme à un port USB-C pour les applications d’IA. De la même manière que l’USB-C fournit une façon standardisée de connecter vos appareils à divers périphériques et accessoires, le MCP fournit une façon standardisée de connecter les modèles d’IA à différentes sources de données et outils.
MCP suit une architecture client–serveur, où un LLM (ou toute application IA utilisant un LLM) établit des connexions à un ou plusieurs serveurs MCP via l’instanciation de multiples clients MCP. Côté serveur, les fonctionnalités sont exposées et leur implémentation suit le protocole standardisé. Voici un exemple :
{
"name": "searchFlights",
"description": "Search for available flights",
"inputSchema": {
"type": "object",
"properties": {
"origin": { "type": "string", "description": "Departure city" },
"destination": { "type": "string", "description": "Arrival city" },
"date": { "type": "string", "format": "date", "description": "Travel date" }
},
"required": ["origin", "destination", "date"]
}
}
Par exemple, dans une application de planification de voyages, un large language model peut utiliser cet outil pour rechercher des vols et aider l’utilisateur à réserver ses vacances au meilleur prix disponible. Cette fonctionnalité est accessible à toute application IA implémentant un client MCP, indépendamment du LLM sous-jacent.
Depuis son introduction, MCP a été adopté par de nombreuses organisations dans des domaines variés, dont WhatsApp, Notion, GitLab, Spotify, Amazon, et bien d’autres.
Vous pouvez retrouver la liste complète ici : MCP Servers on GitHub.
Bien entendu, OpenSearch en fait partie.
OpenSearch a introduit les agents et les tools avec la version 2.13 du 2 avril 2024, quelques mois avant l’arrivée de MCP.
Pour utiliser les tools standard d’OpenSearch, il suffit de définir un agent. De nombreux tools génériques sont déjà implémentés et prêts à l’emploi. Parmi eux : des outils de recherche (lexicale ou sémantique), des outils pour interagir avec le cluster (comme le List Index Tool, qui exécute un _cat/indices), et même des outils pour effectuer des recherches sur Internet.
Nous pouvons utiliser ces tools à l’intérieur d’un flow ou d’un conversational flow agent, dans les cas où nous voulons que les tools s’exécutent dans un ordre spécifique. Dans cette courte démo, j’utiliserai un plan–execute–reflect agent, un autre type d’agent qui permet au LLM de prendre des décisions et de choisir quel tool appeler.
On peut le voir comme un orchestrator intelligent.
Pour commencer avec les tools, la première chose que nous devons faire est d’enregistrer notre grand modèle de langage.
Pour cela, nous devons :
POST /_plugins/_ml/model_groups/_register
{
"name": "remote_model_group",
"description": "A model group for external models"
}
POST /_plugins/_ml/connectors/_create
{
"name": "My openai connector: gpt-4",
"description": "This allow us to connect an external llm to the cluster",
"version": 1,
"protocol": "http",
"parameters": {
"model": "gpt-4o"
},
"credential": {
"openAI_key": "sk-proj-****"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://api.openai.com/v1/chat/completions",
"headers": {
"Authorization": "Bearer ${credential.openAI_key}"
},
"request_body": "{ \"model\": \"${parameters.model}\", \"messages\": [{\"role\":\"developer\",\"content\":\"${parameters.system_prompt}\"},${parameters._chat_history:-}{\"role\":\"user\",\"content\":\"${parameters.prompt}\"}${parameters._interactions:-}]${parameters.tool_configs:-} }"
}
]
}
{
"name": "gpt-4o",
"function_name": "remote",
"model_group_id": "FrX4w5gB0MsRGuywoXJN",
"description": "Remote models for demo",
"connector_id": "IbX6w5gB0MsRGuyw3XKD"
}
Une fois cela fait, vous pouvez utiliser votre modèle via son model_id. Vous pouvez le récupérer immédiatement après l’enregistrement ou via l’interface dédiée de Kibana, qui donne une vue d’ensemble des modèles déployés ou connectés.
Enfin, nous pouvons définir l’agent :
POST /_plugins/_ml/agents/_register
{
"name": "My Plan Execute Reflect Agent",
"type": "plan_execute_and_reflect",
"description": "Agent for dynamic task planning and reasoning",
"llm": {
"model_id": "LbX7w5gB0MsRGuywtHKV",
"parameters": {
"prompt": "${parameters.question}"
}
},
"memory": {
"type": "conversation_index"
},
"parameters": {
"_llm_interface": "openai/v1/chat/completions"
},
"tools": [
{ "type": "ListIndexTool" },
{ "type": "SearchIndexTool" },
{ "type": "IndexMappingTool" }
],
"app_type": "os_chat"
}
Cet agent permet au LLM de décider s’il doit récupérer des informations à partir des tools disponibles pour répondre à la requête de l’utilisateur. Il est important de fournir un ensemble limité de tools pour s’assurer que le LLM n’exécute que les actions prévues ; trop d’outils peuvent entraîner des comportements incorrects.
Dans cet exemple, les tools disponibles sont :
Notez que nous utilisons une mémoire de type conversation_index, ce qui signifie que chaque itération sera stockée dans un index dédié.
Pour tester notre Agentic RAG, il suffit d’exécuter la commande suivante :
POST _plugins/_ml/agents/ZbUExJgB0MsRGuywRXLY/_execute?async=true
{
"parameters": {
"question": "How many indices in my cluster and what do they contain?"
}
}
Je préfère l’exécuter en mode asynchrone, car nous ne savons pas combien de temps le LLM prendra pour itérer à travers les tools et fournir une réponse.
Voici la version traduite en français, toujours en gardant les termes techniques (MCP, tools, connectors, etc.) :
À partir de la version **3.0**, MCP est disponible en deux variantes :
- **MCP Internal Server** – directement intégré au cluster et compatible à partir de la version 3.0
- **MCP External Server** – compatible à partir de la version 2.9 (car nous avons besoin de connectors pour communiquer avec le serveur)
### MCP Internal Server
À propos du MCP internal server, comme il est intégré dans OpenSearch, il faut l’activer avant de pouvoir l’utiliser :
```json
PUT /_cluster/settings/
{
"persistent": {
"plugins.ml_commons.mcp_server_enabled": "true"
}
}
Attention : cette commande est légèrement différente en version 3.0.
Une fois le MCP Internal Server activé, il sera nécessaire d’enregistrer les tools, ce qui peut se faire directement via l’endpoint :
POST /_plugins/_ml/mcp/tools/_register
En effet, au démarrage du serveur, aucun tool n’est enregistré. Vous pouvez le vérifier via l’endpoint _list :
GET /_plugins/_ml/mcp/tools/_list
Ce n’est pas le cas du MCP External Server, qui embarque déjà des tools directement utilisables, comme ListIndexTool, IndexMappingTool et SearchIndexTool. La liste des tools disponibles peut être consultée directement dans les logs du MCP server :
INFO - GET https://opensearch-node01:9200/ [status:200 request:0.018s]
Connected OpenSearch version: 3.0.1
Applied tool filter from environment variables
Available tools after filtering: ['ListIndexTool', 'IndexMappingTool', 'SearchIndexTool', 'GetShardsTool', 'ClusterHealthTool', 'CountTool', 'MsearchTool', 'ExplainTool']
Nous garderons ce sujet pour le prochain article de blog, où je montrerai comment implémenter une fonction personnalisée dans le MCP server d’OpenSearch et comment utiliser les connectors pour relier le cluster OpenSearch avec le MCP server.
L’évolution de la recherche traditionnelle vers le RAG, puis vers l’Agentic RAG, montre le chemin parcouru dans la combinaison des large language models avec une récupération d’information fiable et structurée. En intégrant OpenSearch avec MCP, nous obtenons une manière standardisée, évolutive et flexible de connecter les LLMs à de multiples tools et sources de données, permettant ainsi un comportement plus intelligent et autonome.
L’Agentic RAG donne aux LLMs la capacité de planifier, d’exécuter et de réfléchir aux tâches, en itérant à travers différents tools tout en maintenant le contexte. Cette approche permet non seulement de pallier les limites des systèmes RAG classiques, mais elle ouvre également la voie à des cas d’usage plus sophistiqués : croiser plusieurs bases de connaissances, réaliser des analyses dynamiques ou encore s’intégrer de manière fluide avec des services externes.
Avec OpenSearch 3.x et MCP, les développeurs disposent désormais d’un cadre robuste pour construire ces systèmes avancés de prise de décision par l’IA. À mesure que nous explorons cet écosystème, les possibilités pour une recherche intelligente et l’automatisation deviennent pratiquement illimitées.