
Dans cet article, nous explorons comment des méthodes de reranking telles que RRF, la normalisation min-max, L2 et atan améliorent les performances des systèmes de recherche hybrides en combinant les approches sémantiques et lexicales.

À l’ère de la surcharge d’information, la pertinence des résultats de recherche est plus cruciale que jamais. Les utilisateurs ne veulent pas seulement des réponses — ils veulent les bonnes réponses, et rapidement. Alors que les systèmes de recherche hybrides se généralisent, combinant modèles lexicaux et sémantiques, le reranking devient une étape essentielle pour offrir les résultats les plus pertinents.
Cet article explore des techniques de reranking telles que Reciprocal Rank Fusion (RRF) et des méthodes de normalisation des scores comme min-max, L2 et atan — des outils qui affinent et optimisent la qualité des résultats dans des systèmes de recherche multiples.
Vous découvrirez également des conseils pratiques pour implémenter vos propres méthodes de reranking dans Elasticsearch.
La recherche hybride combine la recherche lexicale (basée sur les mots-clés) et la recherche sémantique (basée sur le sens et l’intention). Chacune de ces approches a ses avantages :
-Recherche lexicale : correspondance exacte des mots-clés, indexation rapide, mais compréhension limitée du contexte.
-Recherche sémantique : utilise des modèles d’apprentissage pour comprendre le sens et l’intention, rendant les résultats plus pertinents et naturels.
Les systèmes hybrides exécutent les deux types de recherches, puis fusionnent leurs résultats. C’est là qu’intervient le reranking : il permet d’organiser les résultats fusionnés en une liste cohérente et pertinente.
Les résultats issus de sources différentes varient souvent en méthodes de scoring, en logiques de classement, et en précision. Une simple fusion ne suffit donc pas.
Le reranking permet de :
Cette technique est particulièrement efficace dans le cadre de la génération augmentée par récupération (RAG), où la précision des réponses du modèle de langage dépend fortement de la pertinence des documents récupérés. En assurant une meilleure correspondance entre la requête et le contenu de support, le reranking permet d’obtenir des réponses plus précises et contextuellement appropriées.
L’une des méthodes de reranking les plus efficaces est le Reciprocal Rank Fusion (RRF).
Elle ne dépend pas des scores bruts mais uniquement des positions dans le classement.

R : ensemble des listes de résultats classés (ex. : lexicales et sémantiques).r(d) : position du document d dans le classement r.k : constante de lissage (généralement 60).L’un des principaux atouts du RRF est sa simplicité et sa robustesse. Contrairement à d’autres techniques qui combinent directement les scores, RRF fonctionne uniquement sur les rangs des documents dans chaque liste, ce qui le rend facile à mettre en œuvre et redoutablement efficace.
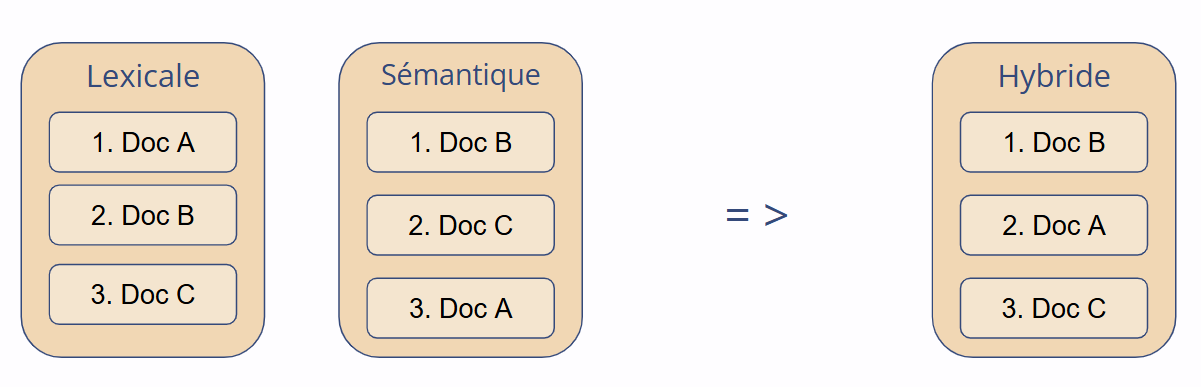
Puisque RRF ne dépend pas des scores bruts, il évite complètement le besoin de normalisation. C’est particulièrement utile dans les contextes hybrides, où les moteurs lexical et sémantique produisent des scores sur des échelles très différentes.
Enfin, RRF valorise la cohérence. Un document présent dans plusieurs résultats — même à des positions moyennes — sera remonté dans le classement final. Cela reflète une sorte de “pertinence consensuelle” : si plusieurs méthodes identifient indépendamment le même document comme pertinent, il y a de fortes chances qu’il le soit réellement. RRF combine ainsi diversité et cohérence dans un classement final harmonieux.
Si vous souhaitez combiner les scores bruts au lieu des rangs, un défi majeur apparaît : les systèmes utilisent des échelles de scoring différentes.
![Normalisation à l’intervalle [0,1].](../../img/posts/20250417_hybrid_reranking/normalization.png)
La normalisation des scores permet d’unifier ces échelles pour permettre une comparaison juste et un reranking efficace. Voici quelques techniques couramment utilisées, avec leurs avantages et limites.
La normalisation min-max est l’approche la plus simple. Elle ajuste linéairement les scores dans une plage [0,1], tout en conservant leur distribution relative.
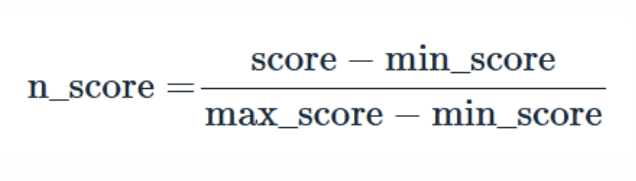
Un autre avantage est sa facilité d’implémentation dans Elasticsearch. Bien que non prise en charge nativement, elle peut être réalisée avec un script simple via une approche en deux étapes :
Voici un exemple de script (étape 2) :
{
"from": 0,
"size": 10,
"knn": {
"k": 1000,
"num_candidates": 1500.0,
"field": "vector",
"boost": 0.5,
"query_vector": [0.3, 0.6, 0.1]
},
"query": {
"script_score": {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "The sound of space",
"fields": "text.lang"
}
}
]
}
},
"script": {
"source": "((_score) / (params.max )) * params.boost;",
"params": {
"max": 10,
"boost": 0.5
}
}
}
}
}
Ici, nous supposons que le score minimum est égal à zéro et que le score maximum est égal à dix.
Cela permet d’harmoniser les scores et facilite la combinaison avec les résultats sémantiques.
La normalisation L2 offre une alternative plus mathématique à min-max.

Son implémentation est plus complexe et se fait aussi en deux étapes :
Cette méthode est plus coûteuse en calculs car elle nécessite l’accès à tous les scores. Elle ne sera donc pas développée ici davantage.
La normalisation Atan utilise une approche non linéaire, en passant les scores dans la fonction arctangente, ce qui atténue les valeurs extrêmes.
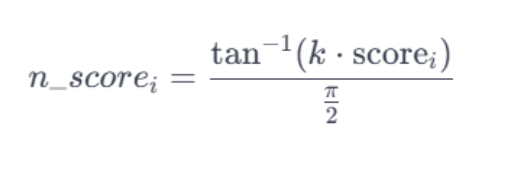
C’est la méthode la plus simple à implémenter, car elle ne nécessite pas plusieurs étapes. Voici un exemple de script :
{
"from": 0,
"size": 10,
"knn": {
"k": 1000,
"num_candidates": 1500.0,
"field": "vector",
"boost": 0.5,
"query_vector": [0.3, 0.6, 0.1]
},
"query": {
"script_score": {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "Un joueur de tennis gagne son match",
"fields": "text.lang"
}
}
]
}
},
"script": {
"source": "(Math.atan(_score) / ( Math.PI/2)) * params.boost;",
"params": {
"boost": 1
}
}
}
}
}
Cependant, elle a aussi ses inconvénients. La transformation des scores modifie leur distribution, ce qui peut fausser leur importance initiale.
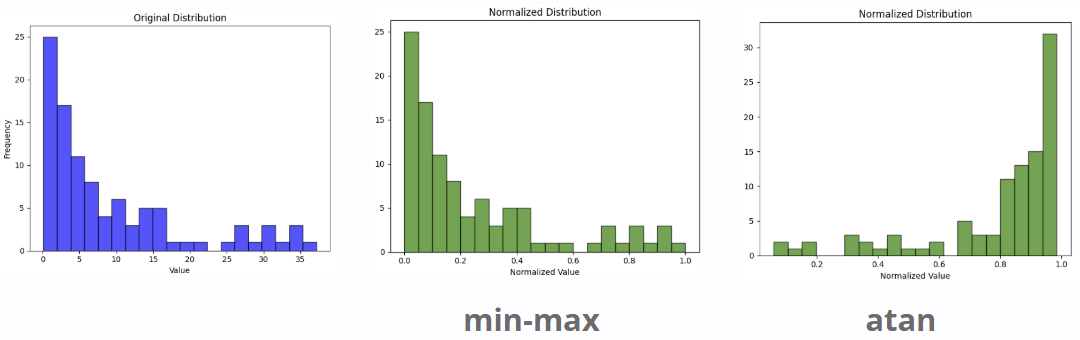
Comme on le voit, les scores faibles sont souvent surélevés, ce qui peut favoriser excessivement la partie lexicale et fausser le reranking global.
Alors que la recherche hybride devient la norme, le reranking est essentiel pour affiner, unifier et améliorer les résultats. Que ce soit via RRF pour fusionner les classements ou via la normalisation des scores pour combiner les sorties de manière cohérente, ces techniques garantissent que les résultats les plus pertinents apparaissent en tête—offrant une expérience de recherche plus intelligente, et des utilisateurs plus satisfaits.
Le choix de la bonne approche doit être adapté aux besoins spécifiques des utilisateurs et validé par une évaluation rigoureuse de la pertinence. En tant qu’experts du domaine, Adelean est là pour vous accompagner vers la solution la plus efficace.