
Mutualiser le code créé précédemment puis chercher des données sur des critères précis. Utiliser la notation lambda pour l'utilisation de la boîte à outils. Stocker les résutats dans des objets spécifiques.

Dans ce deuxième article de la série, nous allons voir comment mutualiser le code, utiliser les lambdas et faire des requêtes avec des critères précis.
Le code présenté est disponible sur Gitlab. La branche correspondante à cet article est la branche 02-enhancing-requesting.
Dans l’article précédent, le client Elastic était défini dans la classe Indices.
Nous allons déporter cette création dans une classe de configuration, via bean dédié.
@Configuration
public class ElasticClientBean {
@Value("${elastic.host}")
private String elasticHost;
@Value("${elastic.port}")
private int elasticPort;
@Value("${elastic.ca.fingerprint}")
private String fingerPrint;
@Value("${elastic.apikey}")
private String apiKey;
@Value("${elastic.scheme}")
private String elasticScheme;
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_SINGLETON)
public ElasticsearchClient elasticClient() {
RestClient restClient = RestClient
.builder(new HttpHost(elasticHost, elasticPort, elasticScheme))
.setHttpClientConfigCallback(hccc -> hccc.setSSLContext(sslContext))
.setDefaultHeaders(new Header[] {
new BasicHeader("Authorization", "ApiKey " + apiKey),
})
.build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}
Au passage, le mode d’authentification a été modifié.
Au lieu d’utiliser les identifiants classiques pour la connexion, nous allons créer une clé d’API.
Le menu est accessible dans Kibana via Stack Management -> Security -> API keys.
Il faut commencer par créer la clé d’API en définissant les droits associés et la durée de validité si besoin.
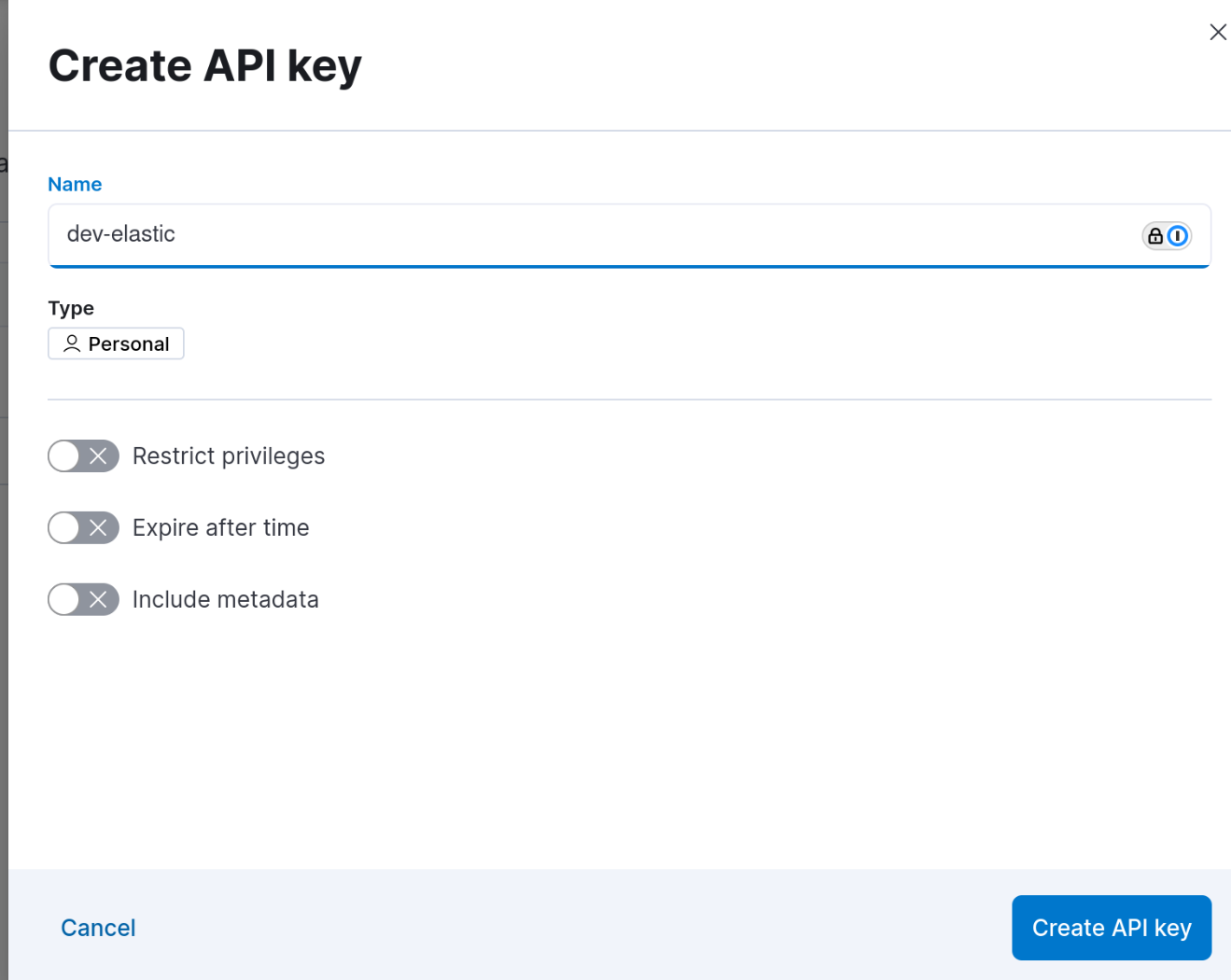
La valeur de la clé n’est affichée qu’une seule fois au moment de sa création. **Attention : La valeur affichée ne correspond pas à la valeur copiée en cliquant sur l’icône de copie. **

La première chose à faire dans ce service est d’initialiser le client Elasticsearch.
@Service
public class OrderService {
private ElasticsearchClient elasticClient;
@Autowired
public void setElasticClient(ElasticsearchClient elasticClient) {
this.elasticClient = elasticClient;
}
Dans ce service, nous allons définir deux méthodes :
Une méthode permettant de récupérer le nombre de commandes pour une adresse mail donnée.
Une méthode permettant d’obtenir le détail des commandes pour une adresse mail donnée.
On va donc commencer par définir une constante qui va contenir le nom du champ qui permettre de filtrer les résultats de recherche :
public static final String EMAIL_FIELD = "email";
public static final String INDEX_NAME = "kibana_sample_data_ecommerce";
Ensuite, la première méthode qui permet de compter les résultats.
public long findNumberOfOrdersForMail(String email) {
try {
CountResponse response = elasticClient.count(c -> c
.index(INDEX_NAME)
.query(q -> q
.match(m -> m
.field(EMAIL_FIELD)
.query(email))));
return response.count();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
On peut voir que pour chaque d’opération, il existe un type de réponse dédié.
La CountResponse indique donc clairement que nous n’allons pas ramener d’autres données qu’un nombre de document.
La requête est faite en utilisant une notation lambda.
La méthode de recherche utilisée est une des plus simples : un match, qui va aller chercher une valeur précise (que ce soit en terme de casse ou de contenu) dans un champ précis de l’index.
On peut alors créer notre classe de test pour vérifier que les résultat renvoyé correspond aux attentes.
@SpringBootTest
class OrderTest {
@Autowired
OrderService orderService;
@Test
void countOrdersByEmail() {
long count = orderService.findNumberOfOrdersForMail("mary@bailey-family.zzz");
assertNotEquals(0, count);
assertEquals(3, count);
}
}
Dans le Dev Tools, la requête correspondante est la suivante :
GET kibana_sample_data_ecommerce/_count
{
"query": {
"match": {
"email": "mary@bailey-family.zzz"
}
}
}
La réponse doit alors être :
{
"count": 3,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
}
}
Maintenant que nous savons compter des documents, nous allons pouvoir en récupérer pour les exploiter.
public List<Object> listOrdersByEmail(String email) {
try {
SearchResponse<Object> response = elasticClient.search(s -> s
.index(INDEX_NAME)
.query(q -> q
.match(m -> m
.field(EMAIL_FIELD)
.query(email)))
, Object.class);
if (response.hits().total() == null || response.hits().total().value() == 0) {
return new ArrayList<>();
}
return new ArrayList<>(response.hits().hits());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
Le type de la réponse passe donc à SearchResponse.
Avec ce code, on récupère un liste d’objets, mais il est possible de spécialiser le code pour récupérer un type d’objet précis qui sera désérialisé grâce à Jackson.
Il faut commencer par définir l’objet :
public class Order {
@JsonProperty("currency")
private String currency;
@JsonProperty("customer_first_name")
private String customerFirstName;
@JsonProperty("customer_last_name")
private String customerLastName;
@JsonProperty("customer_full_name")
private String customerFullName;
@JsonProperty("email")
private String email;
@JsonProperty("order_date")
private ZonedDateTime orderDate;
@JsonProperty("taxful_total_price")
private double taxfulTotalPrice;
@JsonProperty("taxless_total_price")
private double taxlessTotalPrice;
public Order(String currency, String customerFirstName, String customerLastName, String customerFullName,
String email, ZonedDateTime orderDate, double taxfulTotalPrice, double taxlessTotalPrice) {
this.currency = currency;
this.customerFirstName = customerFirstName;
this.customerLastName = customerLastName;
this.customerFullName = customerFullName;
this.email = email;
this.orderDate = orderDate;
this.taxfulTotalPrice = taxfulTotalPrice;
this.taxlessTotalPrice = taxlessTotalPrice;
}
public Order() {
}
@Override
public String toString() {
return "Order{" +
"currency='" + currency + '\'' +
", customerFirstName='" + customerFirstName + '\'' +
", customerLastName='" + customerLastName + '\'' +
", customerFullName='" + customerFullName + '\'' +
", email='" + email + '\'' +
", orderDate=" + orderDate +
", taxfulTotalPrice=" + taxfulTotalPrice +
", taxlessTotalPrice=" + taxlessTotalPrice +
'}';
}
/* Getters and setters */
J’attire l’attention sur la définition de orderDate.
Si on regarde le champ dans le Dev Tools, on peut voir que la date est à un format particulier :
2024-03-03T21:59:02+00:00
Il s’agit d’un format zoné, le type de la date doit donc intégrer cette particularité et être ZonedDateTime.
Pour que la désérialisation se passe bien, il faut modifier la création du client Elasticsearch et paramétrer le JsonpMapper. La ligne
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
Devient alors
ObjectMapper mapper = new ObjectMapper();
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
mapper.setSerializationInclusion(JsonInclude.Include.NON_EMPTY);
mapper.registerModule(new JavaTimeModule());
JacksonJsonpMapper jacksonJsonpMapper = new JacksonJsonpMapper(mapper);
ElasticsearchTransport transport = new RestClientTransport(restClient, jacksonJsonpMapper);
Il faut alors modifier la requête pour la spécialiser :
public List<Hit<Order>> listOrdersByEmail(String email) {
try {
SearchResponse<Order> response = elasticClient.search(s -> s
.index(INDEX_NAME)
.query(q -> q
.match(m -> m
.field(EMAIL_FIELD)
.query(email)))
, Order.class);
if (response.hits().total() == null || response.hits().total().value() == 0) {
return new ArrayList<>();
}
return response.hits().hits();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
Il reste donc à écrire la méthode de test correspondante :
@Test
void listOrdersByEmail() {
List<Hit<Order>> orders = orderService.listOrdersByEmail("mary@bailey-family.zzz");
assertNotNull(orders);
assertEquals(3, orders.size());
for (Hit<Order> hit : orders) {
System.out.println(hit.source());
}
}
On peut voir que pour accéder à l’objet “Order”, il faut utiliser la méthode “source()” de l’objet Hit.