
Learn about vector search and how to implement it using JINA library, including document arrays for vector embedding, image embedding, and more.
Recently, we attended an event organized by JINA and OpenSource Connection where we learned more about the JINA stack and its applications in vector search. During the event, we had the opportunity to hear from experts in the field and learn about the latest developments and best practices in using JINA for vector search. We were also able to network with other professionals in the field and gain valuable insights into how JINA is being used in real-world applications.
The event was a great opportunity to deepen our understanding of JINA and its capabilities, and we left with a newfound appreciation for the power and versatility of the JINA stack. Whether you are a seasoned professional or just starting out in the field, the JINA and OpenSource Connection event is a must-attend for anyone interested in vector search and its applications.
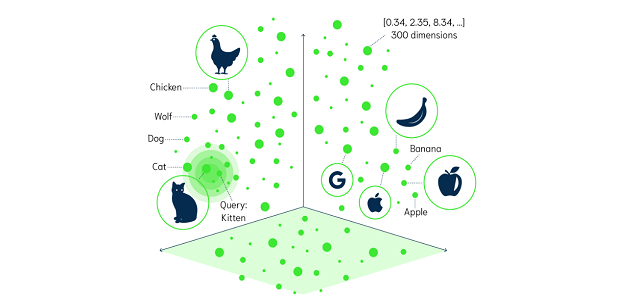
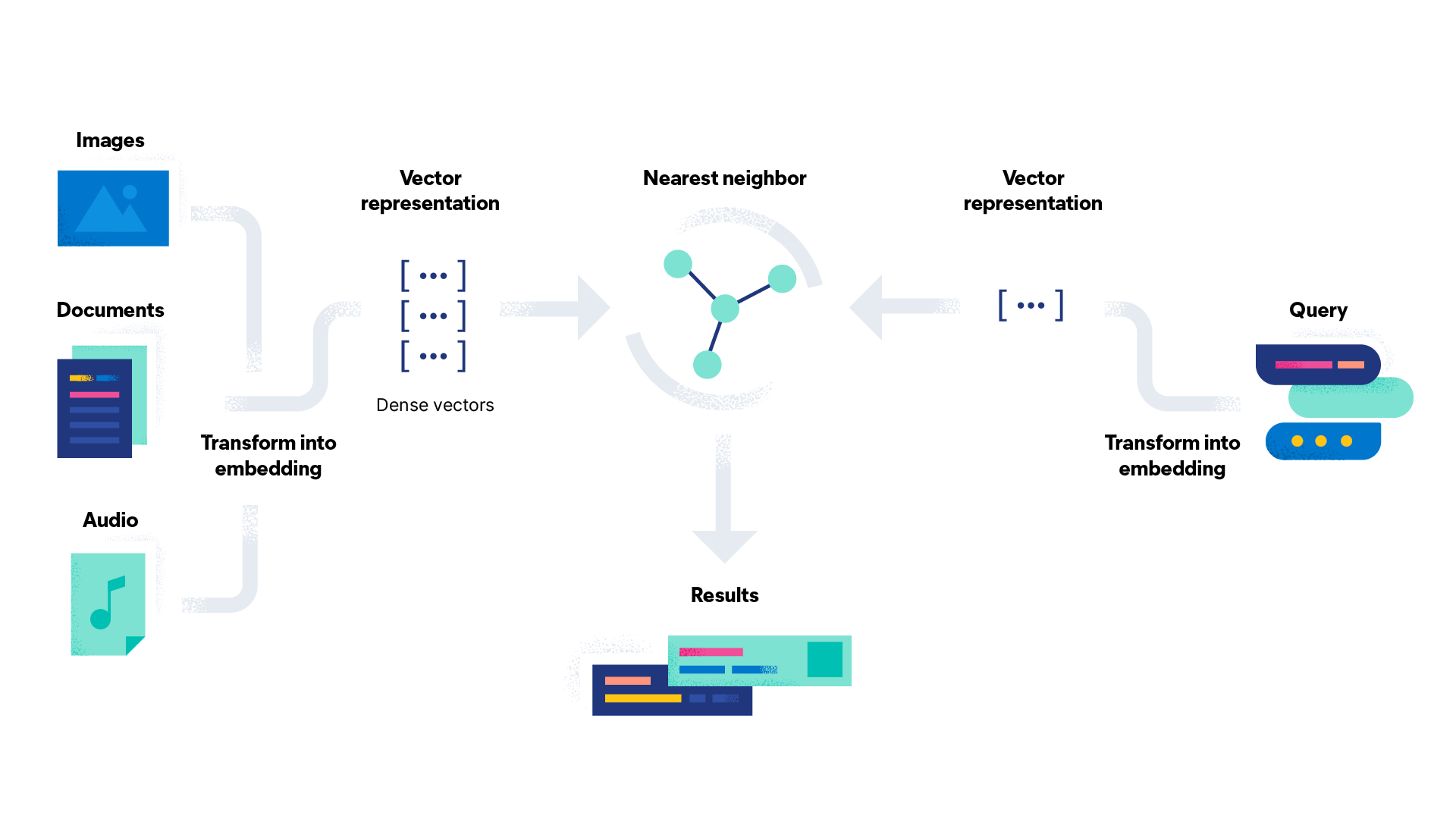
Vector search is a modern approach to information retrieval that uses dense vectors, or embeddings, to represent data and perform search based on semantic similarity. In vector search, data is transformed into dense vectors that capture the essence of the data in a compact and continuous form, and search is performed based on the similarity of the vectors, rather than just matching keywords.
JINA is a high-performance, open-source library for neural information retrieval, that provides an easy-to-use and flexible framework for building vector search applications. With JINA, you can easily implement vector search using a combination of pre-trained embeddings and deep learning algorithms.
In JINA, you can use document arrays (doc-array) to store and manipulate dense vectors, or embeddings, that represent your data. The doc-array is a data structure that allows you to store multiple documents and their embeddings in a compact and efficient way. To use doc-array for vector embedding, you can use JINA’s built-in deep learning libraries, such as TensorFlow or PyTorch, to extract embeddings from your data, and store them in the doc-array.
Another way to use doc-array for vector embedding is to use embedding feature hashing, which is a technique that maps categorical variables to dense vectors, or embeddings. In JINA, you can use feature hashing to convert categorical variables to dense vectors and store them in the doc-array. This can be useful when you have a large number of categorical variables, as it can reduce the dimensionality of your data and improve the performance of your search applications.
Here’s an example of how you can use JINA to implement vector search:
from docarray import Document, DocumentArray
d = Document(uri='https://www.gutenberg.org/files/1342/1342-0.txt').load_uri_to_text()
da = DocumentArray(Document(text=s.strip()) for s in d.text.split('\n') if s.strip())
da.apply(Document.embed_feature_hashing, backend='process')
q = (
Document(text='she smiled too much')
.embed_feature_hashing()
.match(da, metric='jaccard', use_scipy=True)
)
print(q.matches[:5, ('text', 'scores__jaccard__value')])
In JINA, you can also use embedding for image search. Image embedding is the process of converting images into dense vectors, or embeddings, that capture the essence of the image in a compact and continuous form. By using image embedding, you can perform image search and retrieval based on semantic similarity, rather than just matching pixels.
The importance of semantic in image search is that it allows you to search for images based on their meaning, rather than just their appearance. For example, if you search for images of dogs, you can retrieve images of dogs of different breeds, colors, and sizes, as long as they are semantically similar. This can help you to retrieve more relevant images and improve the user experience of your search applications.
Here’s an example of how to use Docarray to compare different picture portraying different subjects in different position.
import torchvision
from docarray import Document, DocumentArray
def preproc(d: Document):
return (
d.load_uri_to_image_tensor() # load
.set_image_tensor_normalization() # normalize color
.set_image_tensor_channel_axis(-1, 0)
) # switch color axis for the PyTorch model later
model = torchvision.models.resnet50(pretrained=True) # load ResNet50
left_da = (DocumentArray.pull('demo-leftda', show_progress=True)[0:1000].apply(preproc).embed(model, device='cuda'))
right_da = (DocumentArray.pull('demo-rightda', show_progress=True)[0:1000].apply(preproc).embed(model, device='cuda'))
left_da.match(right_da, limit=9)
for d in left_da:
for m in d.matches:
print(d.matches[0], d.matches[0].scores['cosine'].value)
#Plotting images-matches
(
DocumentArray(left_da[8].matches, copy=True)
.apply(
lambda d: d.set_image_tensor_channel_axis(
0, -1
).set_image_tensor_inv_normalization()
)
.plot_image_sprites()
)
(
DocumentArray(left_da[8], copy=True)
.apply(
lambda d: d.set_image_tensor_channel_axis(
0, -1
).set_image_tensor_inv_normalization()
)
.plot_image_sprites()
)
CLIP stands for Contrastive Language-Image Pre-Training. It is a model pre-trained on a large dataset of images and their associated captions or descriptions, allowing it to learn how to identify and understand the contents of images based on the words used to describe them.
CLIP-as-service is a low-latency high-scalability service for embedding images and text. It can be easily integrated as a microservice into neural search solutions.
Here an example of how to use clip-as-service. The model will look up over our data set, to find the best nine pictures matching the input string.
pip install clip-client
pip install docarray
from docarray import DocumentArray
from clip_client import Client
c = Client('grpcs://demo-cas.jina.ai:2096')
c.profile
da = DocumentArray.from_files(['left/*.jpg', 'right/*.jpg'])
da.plot_image_sprites()
da = c.encode(da[0:5000],show_progress=True)
while True:
vec = c.encode([input('sentence> ')])
r = da.find(query=vec, limit=9)
r[0].plot_image_sprites()
In conclusion, vector search is a powerful tool that has the potential to revolutionize how we search and analyze complex data.
It is rapidly gaining traction in the data science community, and many companies are already using it to improve their search capabilities. As more research is conducted in this field, we can expect to see even more innovative uses of vector search, and it will likely become an indispensable tool for data analysis in the years to come.