
À l’occasion de l’édition de cette année de Voxxed Days CERN, l’emblématique Science Gateway de Meyrin s’est à nouveau transformé en lieu de rencontre pour développeurs, architectes et passionnés de technologie. Cet événement d’une journée, inscrit dans la série mondiale Voxxed Days, a mis l’accent sur le software craftsmanship, la sécurité et, bien sûr, l’IA.

Il n’y a pas si longtemps, une petite délégation d’Adelean s’est rendue en Suisse pour participer à l’édition 2026 de Voxxed Days CERN. L’événement s’est tenu à Meyrin, au cœur du centre scientifique du CERN, l’un des plus importants centres de recherche en physique des particules au monde.
Nous avons eu l’opportunité de visiter une partie du centre, et en particulier ELENA, le décélérateur d’antiprotons qui permet de capturer et de faire entrer en collision des antiprotons afin de mesurer les caractéristiques de l’antimatière. Mais nous sommes informaticiens, pas physiciens, et la raison principale de notre venue était d’échanger avec des spécialistes de notre domaine, d’écouter leurs retours, dans l’espoir de repartir avec de nouvelles idées à mettre en pratique.

La journée a commencé sur les chapeaux de roue, et nous avons été immédiatement confrontés aux menaces bien réelles qui se cachent dans les centaines de lignes de code que nous écrivons chaque jour. Soroosh Khodami nous a rappelé que nous ne sommes souvent qu’à une seule commande d’être piratés. Comment ? Nous ne sommes pas assez naïfs pour exécuter la première commande suspecte trouvée sur Internet. Certes, mais que se passe-t-il si cette commande s’exécute indirectement via une dependency que nous venons d’installer ?
La présentation de Soroosh, “Are We Ready For The Next Cyber Security Crisis Like Log4Shell?", portait sur les supply chain attacks et sur la facilité avec laquelle une minuscule faille peut être exploitée pour causer d’énormes dégâts à n’importe quelle organisation. Prenons cet exemple : vous créez un projet Spring Boot avec une dependency gson (une bibliothèque très courante). Vous lancez mvn install. Ailleurs, un acteur malveillant reçoit une connexion. Mais comment est-ce possible ? Eh bien, une fausse version de la dependency a été publiée avec un numéro de version supérieur, et votre outil de build l’a téléchargée sans broncher (vous vouliez la dernière version, non ?).

Nous venons d’assister à un cas de dependency confusion, l’un des nombreux types d’attaques qui peuvent toucher notre software supply chain.
Et avec l’IA qui écrit du code pour nous, la situation ne fait qu’empirer ! De faux repositories remplis de code malveillant fleurissent pour réaliser du LLM poisoning ; des centaines de milliers de modèles sur Hugging Face présentent des comportements suspects ; nous croisons de faux packages qui semblent fiables, avec des chiffres de téléchargements artificiellement gonflés ; et puis il y a le prompt injection, le typo squatting (avez-vous déjà remarqué qu’il n’y a qu’une lettre de différence entre “colorful” et “colourful” ?) … Bref, le danger est plus réel que jamais.
Alors, que pouvons-nous faire ? Soroosh propose trois niveaux de mesures, de la plus simple (mais urgente et critique) à la plus sophistiquée et complexe à mettre en œuvre.
Les mesures critiques (à mettre en place dès la fin de la présentation, pour bien comprendre l’urgence) incluent :
Viennent ensuite les mesures essentielles, qui demandent un peu plus de temps à mettre en place, comme :
Enfin, les précautions avancées à long terme impliquent :
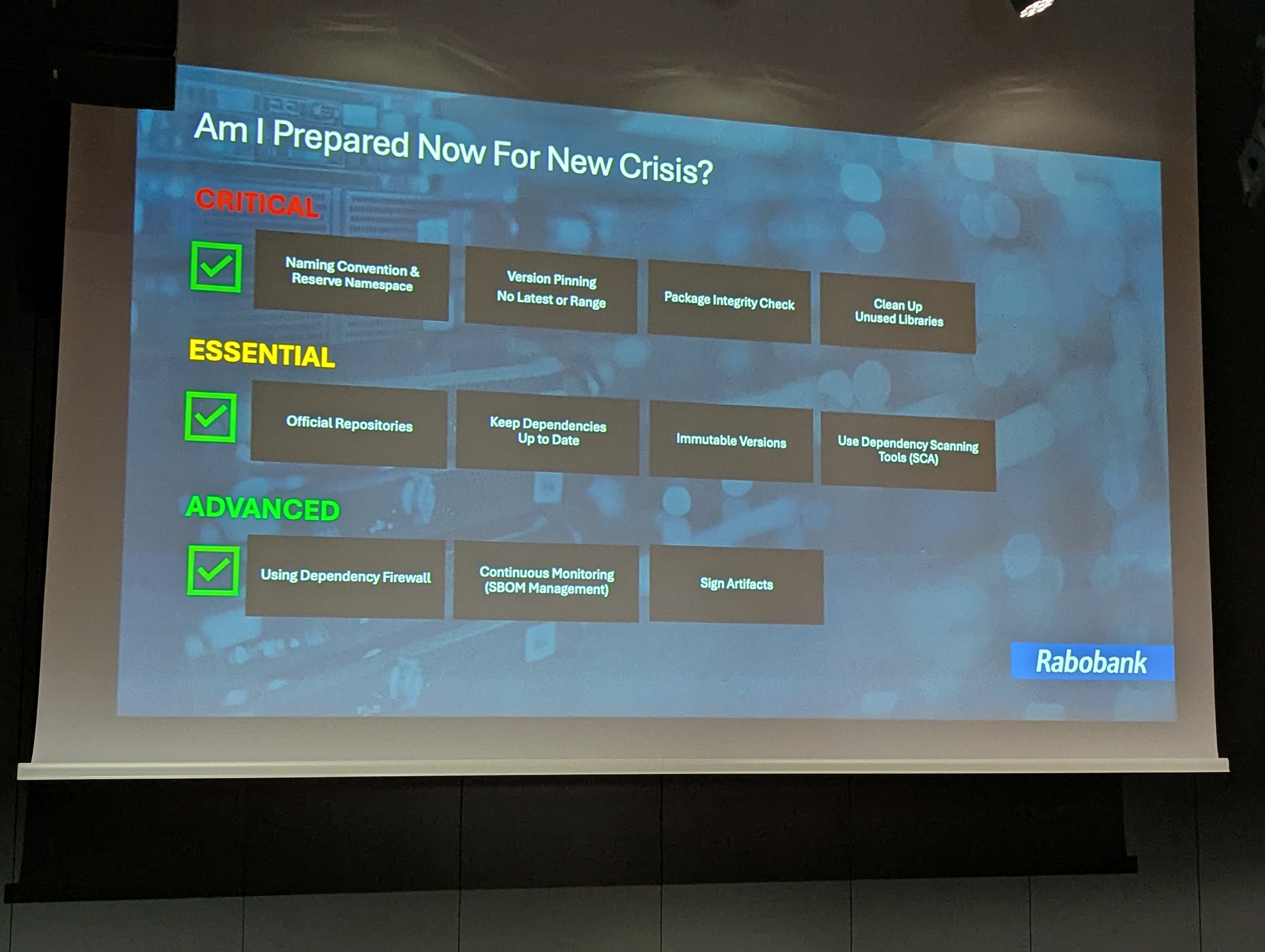
Au final, lorsqu’une crise éclate, la plupart des entreprises paniquent, cherchant à savoir quelles parties de leurs systèmes sont touchées, et qui appeler pour corriger. Les SBOMs sont très utiles dans ces situations : ils permettent de savoir immédiatement quelles applications sont concernées, de remonter au composant vulnérable, d’identifier qui l’a introduit, et de décider quoi corriger en priorité. Et ce dernier point est crucial : la sévérité n’est pas la même chose que la priorité, et une faille critique dans un outil interne isolé peut compter moins qu’une faille moyenne dans un service exposé au public.
Alors, sommes-nous prêts pour la prochaine grande attaque sur la supply chain ? Probablement pas, mais avec ces bonnes pratiques, nous avons peut-être une chance d’y survivre.
En début d’après-midi, la scène appartenait à notre collègue Pietro Mele, qui a réussi à donner deux talks différents pour deux publics différents, sans changer le sujet central : la recherche sémantique.
La première session s’adressait aux débutants, ceux qui ont entendu le mot “vecteur” suffisamment de fois pour hocher la tête, mais pas toujours assez pour l’expliquer. Pietro les a guidés à travers les bases : comment, en recherche sémantique, tout (des documents indexés dans le moteur de recherche à la requête utilisateur) est transformé en vecteur ; comment les vecteurs sont comparés dans un espace vectoriel ; pourquoi la recherche sémantique est fondamentalement différente de la recherche lexicale, et quelles limites de cette dernière elle permet de dépasser.
Si vous aussi découvrez le sujet et souhaitez en savoir plus, consultez cet article sur la différence entre vecteurs creux et vecteurs denses.

À peine le temps d’avaler une bouchée, Pietro était de retour sur scène. Cette fois, le sujet était plus avancé : il a exploré les défis du passage en production d’un système de recherche sémantique à grande échelle, gérant plus d’un milliard de vecteurs. Plus précisément, la présentation était un concentré des concepts fondamentaux pour gérer efficacement des moteurs de recherche sémantique à l’échelle, de la vectorization à l’indexation et la recherche.
Parmi les points clés, Pietro a expliqué comment la dernière intégration de CAGRA dans OpenSearch et Elasticsearch améliore les performances pour les workloads de recherche sémantique. En effet, avec le GPU qui prend en charge la vectorization et le traitement des vecteurs, le CPU est libéré de la plupart des calculs vectoriels et peut se concentrer sur d’autres tâches. En même temps, les traitements sur GPU sont bien plus rapides et efficaces que sur CPU pour la vectorization.
Autre nouveauté importante, qui illustre aussi l’intérêt des évolutions d’Elasticsearch et OpenSearch : la possibilité de ne plus stocker le champ _source par défaut lors du travail avec des vecteurs. Cela concerne Elasticsearch 9+ et OpenSearch 3+ et permet d’éviter de stocker plusieurs fois les mêmes vecteurs, libérant ainsi des ressources précieuses. Bien sûr, en cas de reindexing, de récupération ou de requête explicite sur _source, les vecteurs sont reconstitués à partir de leur format interne.
La plus grande nouveauté côté OpenSearch et Elasticsearch concerne l’optimisation de la recherche. On connaissait déjà diverses techniques de quantization : scalar, product, binary, toutes supportées par les deux moteurs, qui réduisent fortement les coûts de calcul. Désormais, la quantization s’applique aussi aux vecteurs stockés sur disque, permettant une recherche sémantique rapide et économique directement depuis le disque.
Un exemple marquant est le nouveau format disk_bbq, récemment présenté par Elastic et disponible à partir d’Elasticsearch 9.2 (avec licence entreprise). Il s’appuie sur IVF et une meilleure binary quantization, avec un processus de recherche en deux étapes et reranking sur un format vectoriel plus précis pour améliorer le recall. Côté OpenSearch, des techniques similaires existent, comme Disk Memory Search et Memory Optimized Search.
Nous parlerons de ces fonctionnalités et bien d’autres lors de la prochaine conférence OpenSearchCon EU à Prague, en avril prochain, alors ne la manquez pas !
L’après-midi s’est poursuivie avec un retour d’expérience où les défis techniques se sont mêlés à des contraintes extrêmes. La présentation de Mihaela Gheorghe-Roman visait à expliquer comment elle et son équipe ont réussi à construire un éditeur de texte collaboratif destiné au domaine de la défense militaire.
Ce contexte d’application unique implique plusieurs défis majeurs : lors d’une opération militaire, et surtout en phase de planification, de nombreuses unités doivent travailler ensemble sur le même document. Chaque utilisateur dispose d’un niveau d’accréditation spécifique : même au sein d’un seul document, différentes sections peuvent avoir des niveaux de classification différents. De plus, l’application est hébergée sur plusieurs serveurs sans accès Internet, qui n’exécutent pas forcément la même version du logiciel.

De nombreux éditeurs du marché ont été évalués, mais finalement écartés : certains modèles de licence imposaient de révéler des détails d’infrastructure, d’autres impliquaient un partage obligatoire du code, d’autres encore n’étaient pas compatibles avec la stack frontend existante ou les attentes de maintenance à long terme. L’équipe a donc choisi la voie la plus difficile : le construire elle-même.
Au fond, un éditeur de texte semble simple : une liste ordonnée de caractères, chacun avec une valeur et une position. Les insertions et suppressions manipulent cette liste. Mais les documents réels ne sont pas que des caractères : ils contiennent du formatage, des tableaux, des images, des objets structurés, et ici, des métadonnées de sécurité attachées non seulement aux documents, mais aussi à leurs sections.
Chaque utilisateur travaille sur une copie locale et les modifications doivent se propager instantanément à tous les autres. La résolution de conflits à la Git a été écartée d’emblée : personne ne doit résoudre des marqueurs de fusion en pleine opération. Le système doit donc résoudre les conflits automatiquement, quand c’est possible. C’est un jeu d’anticipation, avec beaucoup de maths : l’objectif n’est pas la perfection, mais la cohérence et la réactivité.
Si deux utilisateurs modifient la même position en même temps, le résultat doit rester déterministe. Pour cela, l’application s’appuie sur l’Operational Transformation : les principes mathématiques de commutativité et d’idempotence que nous avons tous vus à l’école s’avèrent ici très utiles. “Last man wins” sert de règle de base, mais le vrai travail se fait dans la logique de transformation, qui ajuste les opérations selon la position, le contexte et la structure avant de les appliquer.
De là, de nombreux autres défis sont apparus : synchronisation des curseurs pour voir où les autres tapent, undo et redo sur des modifications distribuées, mécanismes de persistance assez robustes pour survivre à des arrêts brutaux (comme des appareils détruits sur le terrain), et bien sûr la superposition des contraintes de sécurité au niveau du document et des sections, avec la possibilité de masquer sélectivement des documents ou même de certains paragraphes dans le même document.
Cette session a prouvé que comprendre le contexte reste essentiel pour choisir la bonne solution, qu’il faut parfois ignorer l’impression de “réinventer la roue” et se concentrer sur ce qui est vraiment nécessaire dans un scénario donné. Et, bien sûr, elle a montré que les maths et une bonne analyse stratégique sont de précieux alliés dans ces situations complexes.
La dernière présentation sur laquelle nous voulons nous attarder était celle de Jesse Kershaw, développeur senior au CERN, qui voulait convaincre son public que le Test-Driven Development peut vraiment les aider à devenir de meilleurs développeurs.

La présentation a commencé par une question simple : qu’est-ce qu’un bon code ? La réponse a mis en avant plusieurs caractéristiques : un bon code est correct, facile à comprendre, facile à modifier, facile à tester, et efficace dans l’utilisation des ressources. La question suivante s’est donc imposée : est-ce que le TDD permet réellement d’atteindre tout cela ?
Dans l’auditorium du CERN, où la recherche scientifique est reine, Jesse a formulé cela comme une hypothèse. Si l’on applique le Test-Driven Development, ces cinq caractéristiques vont-elles émerger ? La démo en direct a servi d’expérience.
En partant d’un test en échec, il a construit une petite fonctionnalité étape par étape, en se laissant guider par le cycle red-green-refactor. Le conférencier nous a montré à quel point le TDD reflète presque parfaitement la méthode scientifique : le test en échec est l’hypothèse, l’implémentation est l’expérience, et l’assertion qui passe est la conclusion.
La correction est imposée immédiatement, car aucun comportement n’existe sans test pour le valider, et la testabilité est intégrée par conception.
Mais qu’en est-il des trois autres caractéristiques ? Eh bien, les tests eux-mêmes, écrits clairement, servent de documentation exécutable, renforçant la compréhension. Ensuite, comme seul le code strictement nécessaire est écrit à chaque étape, la structure reste petite et adaptable, favorisant le changement plutôt que de le freiner. Et avec un filet de sécurité en place, le refactoring et même les optimisations de performance peuvent être réalisés en toute confiance, encourageant la recherche d’efficacité.
La présentation s’est terminée par quelques conseils pratiques pour écrire de bons tests : utiliser les assertions natives plutôt que des personnalisées trop astucieuses, écrire des messages d’échec explicites, privilégier les tests paramétrés et data-driven, et ne pas sur-abstraire trop tôt le code de test (le copier-coller est parfois votre ami !)
En résumé, nous avons appris qu’écrire du bon code est difficile, et écrire de bons tests l’est encore plus. Le TDD ne supprime pas cette difficulté, mais crée les conditions pour exercer de bonnes pratiques à répétition, de sorte que même sans le suivre à la lettre, on reconnaît instinctivement ce qu’est un bon code.
L’édition 2026 de Voxxed Days CERN a rappelé la richesse et la diversité qui caractérisent le paysage logiciel actuel. Des réalités urgentes de la cybersécurité aux profondeurs techniques de la recherche sémantique, en passant par les défis du développement logiciel en environnement critique et la rigueur scientifique du TDD, l’événement a offert un panorama de perspectives et d’expertises.
L’événement a réuni une communauté internationale d’experts désireux d’apprendre, de se challenger et de s’inspirer. Il nous a rappelé que les meilleures idées naissent souvent à l’intersection des disciplines, et que le progrès est autant porté par le dialogue et l’expérimentation que par la technologie elle-même.
Nous avons quitté Meyrin avec de nouvelles connaissances et une motivation renouvelée, et avons hâte d’être à la prochaine édition !