
Berlin Buzzwords 2025 rassemble les voix de référence en matière d’IA, de Big Data, de Search et d’infrastructures de données scalables, le tout ancré dans l’innovation open source. Des GPU pour les LLMs à la souveraineté des données, des plateformes de recherche aux pipelines temps réel, c’est ici que les idées rencontrent l’ingénierie et que se dessine le paysage des données de demain.

Cette année encore, nous avons eu l’opportunité de participer à Berlin Buzzwords, une conférence devenue une référence dans la communauté du search. Comme à chaque édition, c’était l’occasion de découvrir de nouvelles technologies, échanger avec ses pairs, apprendre de cas concrets… et repartir vraiment inspirés.
Mais aussi de partager notre propre expérience et de contribuer à cette communauté que nous sommes fiers de représenter. Adelean était présente avec deux interventions.
Le premier jour, Lucian Precup et Giovanna Monti ont abordé le sujet des fake news et de l’aide que l’IA peut apporter pour détecter et contrer la désinformation dans un monde où l’information circule vite (trop vite).
Le deuxième jour, Pietro Mele et Radu Pop ont présenté une session sur la recherche hybride, mettant en lumière les défis liés à la mise en œuvre de la recherche sémantique à grande échelle.
Toutes les interventions sont désormais disponibles sur la chaîne YouTube de Plain Schwarz.
Un thème majeur de cette édition était la recherche sémantique. Cette technologie gagne en maturité et s’intègre de plus en plus dans les moteurs de recherche. De nombreuses conférences ont présenté des cas d’usage concrets, des retours d’expérience et des approches innovantes : RAG, recherche vectorielle, architectures hybrides…
Lors de la présentation « Performance Tuning Apache Solr for Dense Vectors », Kevin Liang a partagé un cas d’usage éclairant issu de Bloomberg, illustrant comment leur moteur de recherche aide les investisseurs à prendre des décisions éclairées.
Avec l’introduction de la recherche sémantique, Liang et son équipe ont rencontré plusieurs défis liés à la montée en charge de cette technologie. Ces défis allaient de l’augmentation de la latence et la saturation du CPU, à des obstacles techniques plus larges nécessitant des stratégies de scalabilité tant verticales qu’horizontales. Cependant, le simple passage à l’échelle ne suffisait pas. Pour améliorer significativement les performances, l’équipe a mis en place plusieurs optimisations clés :
Un autre axe critique était la réduction de l’empreinte mémoire, que l’équipe a atteinte en quantifiant les vecteurs et en évitant de stocker les données vectorielles originales.
Dans sa présentation, Dhrubo Saha a démontré les véritables capacités d’apprentissage automatique d’OpenSearch, tout en offrant un aperçu de sa feuille de route pour l’avenir.
Le point fort de son intervention était la recherche multimodale, une approche qui exploite plusieurs types de vecteurs d’entrée, comme ceux issus à la fois de textes et d’images, pour effectuer une recherche sémantique et hybride. Cette capacité est particulièrement utile dans les scénarios où les métadonnées traditionnelles sont insuffisantes ou absentes, permettant ainsi des résultats de recherche plus riches et plus précis.
Saha a également abordé les composants essentiels qui soutiennent cette fonctionnalité : la gestion des modèles, l’orchestration d’agents, et l’inférence en temps réel. Ces éléments fondamentaux garantissent que la recherche multimodale peut être déployée efficacement, à grande échelle, ouvrant la voie à des expériences de recherche plus intelligentes et plus flexibles.
Un axe central de sa présentation portait sur le processeur d’inférence d’OpenSearch, qui se distingue par sa flexibilité. Il peut être appliqué à plusieurs étapes du pipeline de recherche, lors de l’indexation, au moment de la requête, et même après l’exécution de la recherche. Cette polyvalence permet de multiples applications puissantes.
Par exemple, des modèles de Reconnaissance d’Entités Nommées (NER) peuvent être appliqués lors de l’indexation pour enrichir les documents avec des métadonnées structurées. Au moment de la recherche, la recherche hybride peut être optimisée grâce à des modèles de re-ranking qui affinent la pertinence des résultats. Enfin, après l’exécution, le processeur d’inférence peut être utilisé pour implémenter des solutions de RAG, éventuellement en combinaison avec des connecteurs et des LLMs, afin de générer des réponses plus informées et sensibles au contexte.
Ce design flexible fait d’OpenSearch une base solide pour construire des expériences de recherche avancées et propulsées par l’IA.
Un autre sujet particulièrement intéressant fut le défi de faire évoluer le RAG (Retrieval-Augmented Generation) vers quelque chose de plus dynamique. Dans sa présentation, Bilge Yücel a montré comment combiner RAG avec un comportement agentique permet de créer des systèmes d’IA capables non seulement de récupérer et répondre à des informations, mais aussi de planifier, raisonner et agir.
Alors que les pipelines RAG classiques sont très efficaces pour les requêtes factuelles, ils atteignent leurs limites avec des demandes complexes. Ces dernières exigent souvent une décomposition de la requête, des stratégies de recherche itératives et une récupération dynamique à partir de multiples sources pour en améliorer la précision.
C’est là que les agents entrent en jeu : un agent d’IA est un système qui poursuit de manière autonome un objectif, en interagissant avec son environnement, en utilisant des outils, et en adaptant ses actions selon les retours pour atteindre sa cible. Le comportement agentique en IA consiste à donner à un modèle la capacité de choisir sa prochaine action, grâce à l’intégration de composants tels que la planification, la prise de décision et le raisonnement.
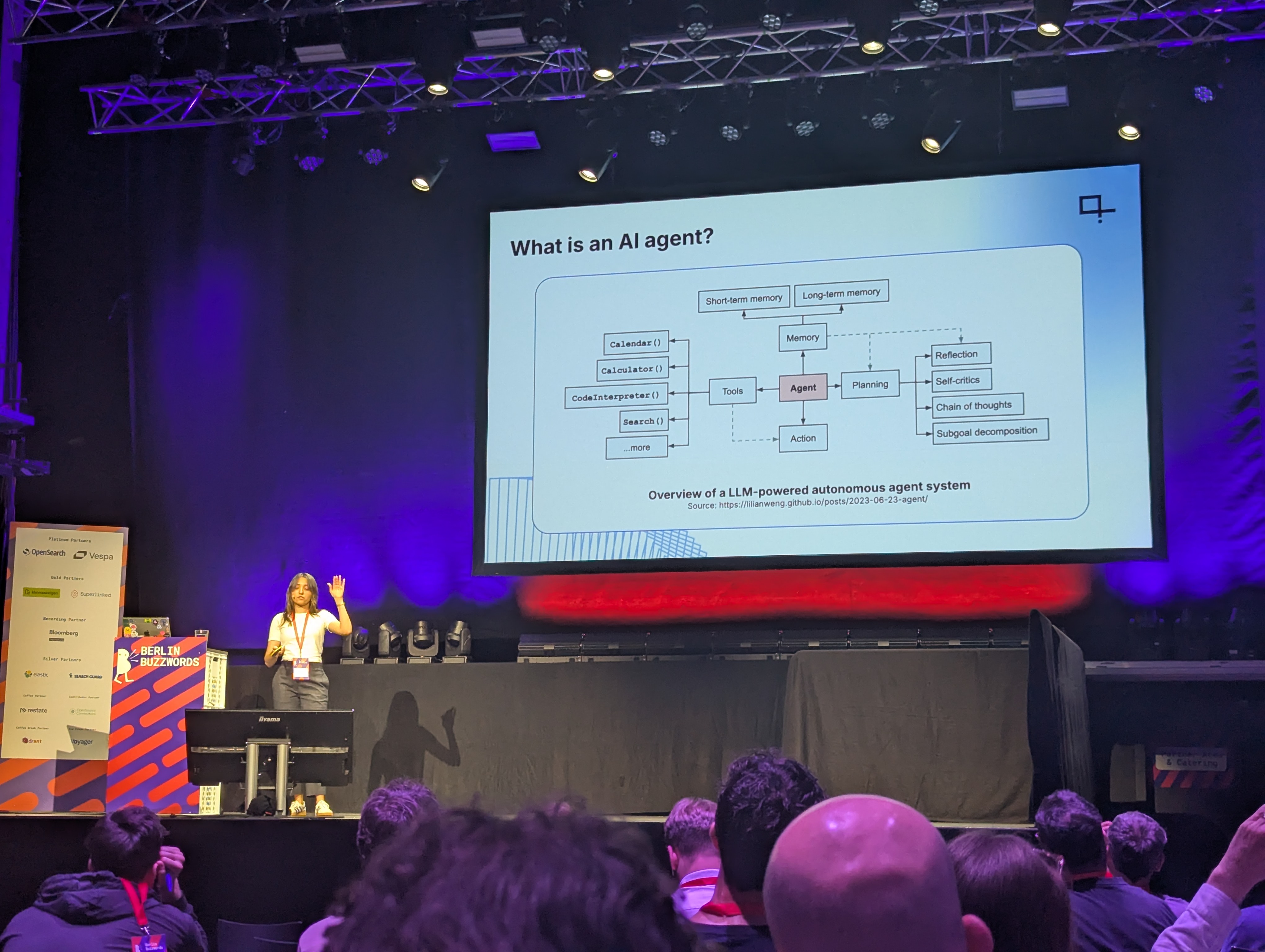
La conférencière a illustré ce concept avec le framework Haystack, un système d’orchestration pour la création de pipelines modulaires d’agents. Sa démonstration mettait en scène un agent basé sur le GPT-4 mini d’OpenAI, équipé d’outils comme la recherche web, l’analyse de documents et des API météo. L’agent recevait une requête, décidait dynamiquement quels outils appeler, et passait par plusieurs étapes de raisonnement pour produire une réponse structurée.
En résumé, elle a démontré qu’en utilisant des techniques de prompt comme « Pensons étape par étape » et le schéma ReAct (Reason + Act), on peut enseigner aux modèles de langage à affiner leurs réponses au fil de plusieurs itérations. Le résultat ? Des systèmes plus intelligents, plus adaptables, parfaitement adaptés aux cas d’usage complexes en entreprise.
En tant qu’experts dans le domaine de la recherche en e-commerce, nous ne pouvions pas manquer la présentation « What You See Is What You Mean: Intent-Based E-Commerce Search » de Dennis Berger, Marco Petris et Volker Carlguth. Leur intervention abordait un défi récurrent dans le e-commerce : comment rendre les résultats de recherche à la fois précis et diversifiés, en particulier lorsque les utilisateurs saisissent des requêtes larges ou ambiguës.
Leur solution ? Une approche innovante de clustering basé sur l’intention, alimentée par des LLMs. Au lieu de s’appuyer uniquement sur des systèmes de recherche hybrides traditionnels, souvent inefficaces pour traiter des requêtes vagues ou d’inspiration, leur méthode introduit une compréhension approfondie de la requête dès le début du pipeline de recherche. En utilisant les LLMs pour interpréter l’intention de l’utilisateur en amont, le système peut guider plus efficacement les étapes de récupération, de regroupement, de validation et de présentation.
Cette technique n’est pas seulement théorique, elle a été testée à grande échelle. L’équipe a montré comment les LLMs permettent de découvrir des significations cachées dans les requêtes, augmentant ainsi le rappel tout en maintenant une haute précision. L’ambiguïté est résolue tôt, et les résultats sont organisés visuellement selon des significations désambiguïsées, réduisant la surcharge cognitive liée au « paradoxe du choix » et offrant aux utilisateurs des parcours plus clairs à travers de vastes catalogues de produits.
Bien sûr, s’appuyer entièrement sur des LLMs serait coûteux. C’est pourquoi l’équipe a également entraîné un modèle basé sur BERT pour gérer la classification binaire de la pertinence des produits. Leur modèle a été entraîné sur plus d’un million de paires intention-produit pour le marché allemand du e-commerce et a atteint un score F de 0,779. Une conception modulaire permet de comparer facilement les modèles, qu’ils soient fine-tunés ou issus de LLMs commerciaux comme GPT ou Gemini.
La performance n’était pas le seul objectif. L’équipe a également étudié des stratégies d’optimisation de la recherche : la mise en cache fonctionne bien pour les requêtes exploratoires populaires comme « machines à laver », tandis que le traitement dynamique reste essentiel pour les requêtes saisonnières ou plus rares comme « décorations de Noël ».
Un autre constat : réduire les requêtes utilisateurs de plusieurs dizaines à seulement quelques-unes, plus courtes et axées sur l’intention, rend l’expérience plus rapide et mieux alignée sémantiquement, au prix d’une légère baisse de diversité dans les résultats.
La présentation s’est conclue par des retours issus de tests UX, montrant que les utilisateurs bénéficient du clustering basé sur l’intention comme aide visuelle et cognitive. Une piste prometteuse pour rendre la recherche e-commerce plus intuitive, plus intelligente et mieux alignée avec ce que les utilisateurs veulent vraiment dire en tapant leur requête.
Cette année, Berlin Buzzwords ne s’est pas seulement concentré sur les approches innovantes de la recherche ou les modèles d’IA agentiques, mais a aussi mis en lumière les dynamiques humaines qui rendent les équipes techniques performantes. Les présentations de Fatima Taj ainsi que du duo Marion Nehring & Jessie de Groot nous ont rappelé l’importance de construire des cultures d’entreprise résilientes et de tracer des parcours professionnels avec intention.
Nehring and de Groot delivered a powerful message: great products and thriving open-source communities are not just built on tech. They’re built on people, culture, and values.
They emphasized that “people buy from people": we’re more likely to try a product recommended by a trusted peer than one advertised by a company. A premium product like Nike Airs isn’t just about materials and design; it’s about the emotional story and trust built around it. That same principle applies in open source: value is created not just in features, but in the relationships and experiences surrounding a project.
That’s why strong company values like openness, kindness, and transparency aren’t just important to internal teams; they must extend outward, shaping how users and contributors interact with your community. Some standout practices include:

Nehring and de Groot also stress that leadership must model the values they want to see. In large companies, values can easily become hollow slogans unless leaders actively live them through small, everyday actions. Whether it’s giving kind, actionable feedback or making time to truly listen to a colleague, these moments matter.
Dans sa présentation, Fatima Taj a partagé des conseils sur la manière dont elle a évité de se retrouver cantonnée au rôle de “colle” : cette personne qui fait tourner l’équipe grâce à un travail de soutien souvent invisible et non technique, comme la rédaction de documentation ou la gestion des communications inter-équipes.
Le parcours de Fatima a commencé lorsqu’elle est devenue, par défaut, la référente d’un processus de déploiement critique chez Yelp. En tant que personne la plus familière avec le projet, on comptait naturellement sur elle pour les mises à jour, la coordination et la communication. Cette visibilité faisait du bien… jusqu’à ce que ce ne soit plus le cas. Son temps et son énergie étaient absorbés par des tableurs et des appels avec les parties prenantes, au détriment des tâches techniques. Bien qu’au cœur du projet, son rôle d’ingénieure logicielle était passé au second plan.
La lecture de l’article de Tanya Reilly “Being Glue” a provoqué un déclic. Elle a compris que sans action de sa part, elle risquait de freiner sa progression, étant perçue comme une cheffe de projet officieuse plutôt qu’une ingénieure compétente.
Elle a donc entamé un changement stratégique : elle a commencé par dire non de manière réfléchie. Elle a ensuite formé ses collègues à prendre en charge certaines tâches récurrentes et a documenté ses processus, permettant ainsi une répartition plus saine des responsabilités. Elle a aussi mis en place un “brag document” : un document vivant, mis à jour toutes les quelques semaines, dans lequel elle consignait ses réalisations. Cela lui a permis de mieux défendre sa valeur lors des entretiens d’évaluation, et de rester concentrée sur des contributions techniques visibles.

Son enseignement clé : faire du bon travail ne suffit pas ; il faut que les bonnes personnes en aient connaissance. Le message de Fatima pour les managers : clarifiez la manière dont les différentes contributions sont valorisées, reconnaissez à la fois le travail technique et non technique, et répartissez les responsabilités de façon intentionnelle. Son message pour les collègues : apprenez à déléguer, à lâcher prise, et à ne pas avoir peur de mettre en valeur votre travail.
Berlin Buzzwords 2025 a réaffirmé pourquoi cet événement reste une référence majeure pour la communauté du search et des données. L’édition de cette année a mis en lumière non seulement la maturité croissante des technologies de recherche sémantique et hybride, mais aussi les frontières passionnantes explorées, des pipelines multi-modaux et de l’agentic AI à la recherche e-commerce basée sur l’intention et à l’infrastructure optimisée pour la performance.
Mais au-delà du code et des modèles, ce qui a profondément résonné, c’est la dimension humaine de la tech : comment nous construisons des équipes, soutenons des carrières, et créons des cultures inclusives et porteuses de valeurs qui stimulent l’innovation.
Nous avons quitté Berlin inspirés, non seulement par les outils et tendances qui façonnent l’avenir de la recherche, mais aussi par la communauté dynamique de penseurs, bâtisseurs et leaders qui la fait avancer. À l’année prochaine !