
Elastic{ON}, la conférence annuelle de l'éditeur Elastic, est arrivé cette année avec la promesse ambitieuse de façonner l’avenir de la recherche. Depuis la scène de la Maison de la Mutualité, un message s’est imposé clairement. L’avenir d’Elasticsearch est agentique. Au-delà de cette vision, l’événement a présenté des mises à jour concrètes des produits, des évolutions architecturales et des cas d’usage réels illustrant l’évolution d’Elastic dans les domaines de la recherche documentaire et de l'accès à l'information, de l’observabilité et de la sécurité.

Cette année, Adelean a une nouvelle fois participé à la conférence emblématique ElasticON Paris (certains d’entre nous y participent depuis l'édition 2015 !) Pour la deuxième année consécutive, nous avons joué un rôle de premier plan, en contribuant à la Community Track et en interagissant directement avec la communauté Elastic.
La conférence a mis en lumière les avancées d’Elastic dans les domaines de la recherche, de la sécurité et de l’observabilité. Plus particulièrement, l’évolution vers l’IA agentique se distingue par une expérience utilisateur raffinée, conçue pour réduire la barrière à l’entrée tant pour les novices que pour les utilisateurs avancés.
La veille de la conférence principale, l’équipe Adelean a participé à une série d’ateliers Elastic, centrés sur la Sécurité, l’Observabilité et la Recherche.
Ces sessions ont offert un aperçu des capacités d’IA qui définissent les dernières versions d’Elastic, .
La keynote d’ouverture a renforcé cette direction, en présentant une feuille de route axée sur la précision et l’innovation.

Elastic continue de réduire la barrière à l’entrée pour la recherche avancée pilotée par l’IA. Un exemple clair est semantic_text, désormais en version stable, qui simplifie l’ensemble du workflow de recherche sémantique – de l’indexation à l’exécution des requêtes – en masquant une grande partie de la complexité sous-jacente.
Cette attention à la simplicité s’étend également à l’intégration des modèles. Suite à l’acquisition de Jina AI, ses modèles d’embeddings optimisés pour le search sont désormais directement accessibles via l’Inference API d’Elastic, permettant un téléchargement et une utilisation immédiate sans configuration supplémentaire.
La performance constitue la couche suivante de l’amélioration. L’intégration avec NVIDIA cuVS apporte l’accélération GPU à la recherche vectorielle, accélérant significativement les calculs de similarité à grande échelle tout en conservant précision et flexibilité.
Mais l’innovation ne se limite pas à la facilité d’utilisation et à la vitesse : elle concerne aussi l’échelle. Avec DiskBBQ, Elastic introduit une architecture IVF + BBQ sur disque conçue pour réduire la charge computationnelle sur des ensembles massifs de vecteurs. Cette approche rend la recherche sémantique viable et efficace même pour des déploiements dépassant un milliard de vecteurs.
Peut-être l’annonce la plus transformative fut l’introduction de Elastic Agent Builder Cet outil visuel intégré à Kibana permet aux utilisateurs de définir des outils personnalisés, d’orchestrer des workflows et de créer des agents adaptés à des tâches spécifiques, démocratisant ainsi l’accès aux interactions complexes avec l’IA.
Cette approche agentique s’étend également à l’Observabilité, où Elastic a démontré des agents capables d’analyser les logs, de partitionner les données et de filtrer les événements pour automatiser des workflows auparavant fastidieux.
Au-delà de l’IA, Elastic a présenté CLP (Compressed Log Processing). Cette nouvelle fonctionnalité complète LogsDB et TSDB pour offrir une compression et une gestion du stockage des logs supérieures sur des ensembles de données à grande échelle.
Suite à la keynote, le consensus est clair : l’avenir de l’IA est indéniablement agentique. Alors que nous naviguons dans cette transition, des protocoles comme MCP (Model Context Protocol) et A2A (Agent-to-Agent) constituent l’infrastructure essentielle qui guidera notre chemin.
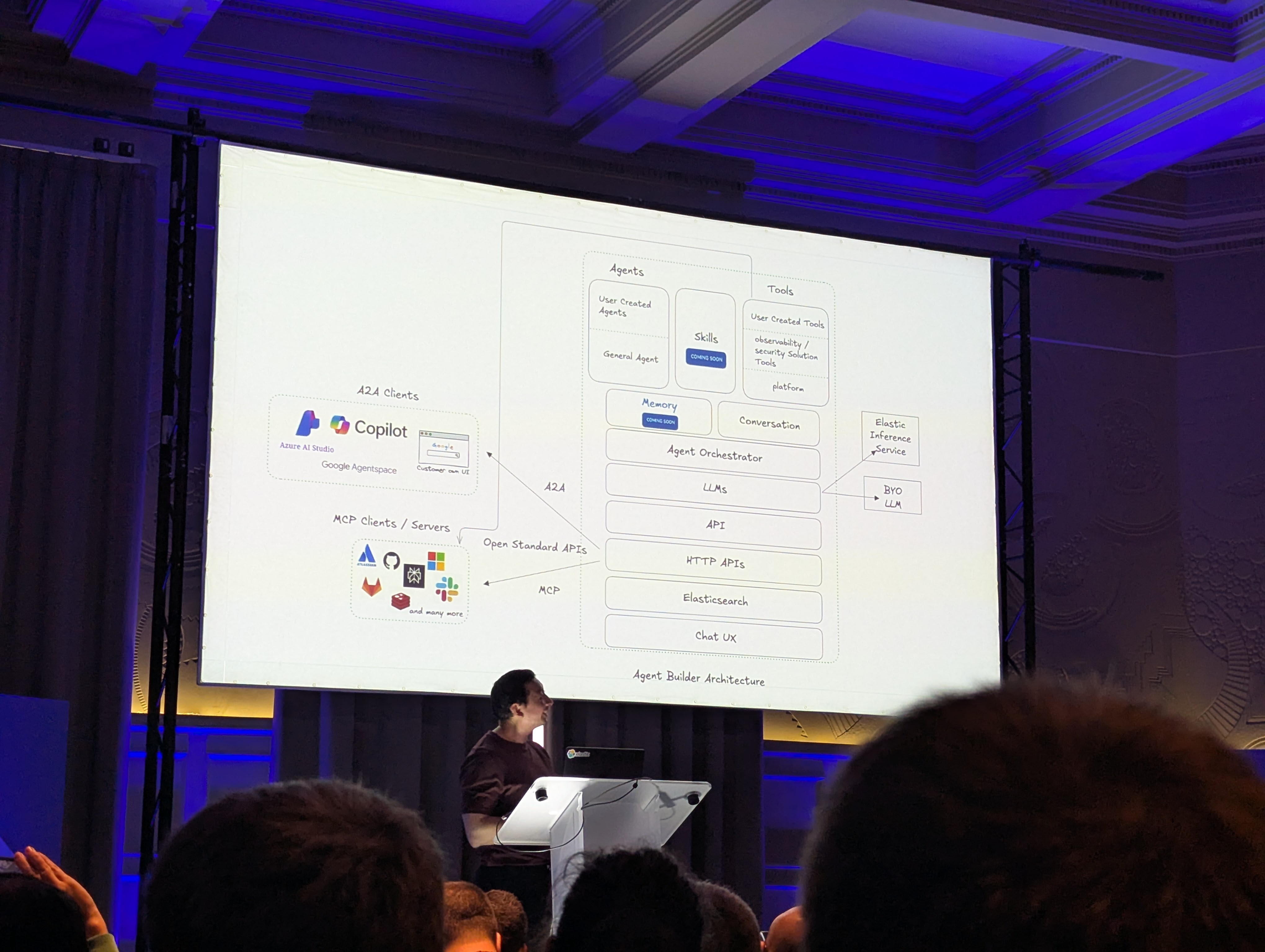
Un point clé concernant A2A a été mis en avant lors de la présentation “The Future of Building AI Agents in Elasticsearch” par Joe McElroy.
Elastic y a introduit le concept de Skills, essentiellement un langage de collaboration. Les Skills permettent aux agents de communiquer leurs capacités spécifiques et de partager des outils, leur permettant ainsi de travailler ensemble de manière fluide pour atteindre les objectifs des utilisateurs.
Cependant, des agents efficaces nécessitent plus que des compétences en communication : ils ont besoin de contexte.
Comme montré dans la présentation “Managing the Memory of a Conversational Agent with Elasticsearch”, la gestion de la mémoire reste un goulot d’étranglement critique à mesure que les systèmes gagnent en complexité.
Les bibliothèques traditionnelles comme LangChain limitent souvent la mémoire à un nombre fixe de tokens (ex. 34k), entraînant la perte du contexte initial. La synthèse (summarization) offre une solution, mais elle sacrifie souvent la granularité nécessaire pour des tâches complexes.
Pour résoudre ce problème, on peut se référer à l’étude CoALA, qui aborde la mémoire des agents à travers le prisme de la cognition humaine. En pratique, cela signifie s’éloigner des simples tampons de tokens et indexer l’historique complet des conversations pour permettre une récupération sémantique et une meilleure qualité de réponses par la qualité du contexte fourni, au dela des simples prompts et “chunks” de documents.
Le cadre distingue trois types de mémoire :

Mettre en œuvre cette « mémoire infinie » nécessite des stratégies intelligentes, comme le découpage des conversations en chunks enrichis de métadonnées (ID utilisateurs, appels d’outils) et l’utilisation de la recherche vectorielle pour l’accès aux fichiers externes.
Bien sûr, avec l’augmentation de la complexité vient le besoin d’une meilleure visibilité. La conférence a mis en avant une stratégie à double index pour l’observabilité : stocker les exécutions de workflow dans un index et les détails granulaires au niveau des nœuds dans un autre. Cette séparation permet aux développeurs d’analyser le comportement des agents sans compromettre les performances, garantissant que nos agents restent non seulement intelligents, mais aussi prévisibles et transparents.
Comme mentionné précédemment, la révolution agentique ne se limite pas à la création d’applications de recherche, elle s’étend également à l’observabilité et à la sécurité.
Prenons le classique « cauchemar de 2 h du matin » : un pic de latence apparaît sur votre tableau de bord suite à une mise à jour de routine. Dans ce genre de situation, le goulot d’étranglement n’est pas la surveillance elle-même, mais le temps nécessaire pour enquêter et coordonner les actions correctives.
Pour relever ce défi, Elastic renforce ses capacités existantes (catégorisation des logs, détection d’anomalies, analyse de traces) avec une nouvelle couche d’intelligence.
Lors de la présentation “From SLO breach to root cause: AI for modern observability” par Drew Post, nous avons découvert comment l’IA peut être utilisée pour couper le bruit et faire émerger instantanément des hypothèses plausibles.
En donnant à un assistant IA l’accès à des informations spécifiques au domaine, celui-ci peut raisonner sur les données pour identifier les causes profondes. Un élément clé est la transparence : chaque action proposée par l’agent est exprimée en ES|QL. Cela permet aux opérateurs humains de vérifier facilement le travail de l’agent avant de l’approuver.

Les principales capacités abordées comprennent :
L’évolution future de ces capacités correspond à ce qu’Elastic appelle AI Investigations. Cette approche permettra de dissocier la détection de la remédiation : les alertes signalent qu’un problème existe, tandis que les décisions de correction (manuelles ou automatisées) sont prises indépendamment et ne doivent pas nécessairement refléter les conditions d’alerte.
À 14h35, c’était le moment Adelean! Benjamin Dauvissat et Pietro Mele sont montés sur scène pour présenter “Fleet Invaders”.
L’objectif de la session était simple : montrer que gérer une infrastructure à grande échelle ne doit pas être un combat. Le duo a démontré à quel point Elastic Fleet est facile à installer et à maintenir, le positionnant comme la solution idéale pour les équipes chargées de superviser des écosystèmes diversifiés — couvrant plusieurs machines et services — sans compromettre la sécurité.

Le public a montré un fort enthousiasme pour ce sujet, même s’il n’était pas directement lié à l’IA.
Au travers des différentes présentations, nous avons pu constater l’affirmation de la tendance depuis environ 2 ans: ES|QL devient le langage de référence, le plus complet que ce soit pour l’analyse de données, l’observabilité, la sécurité mais aussi la recherche documentaire. De nombreux nouveaux opérateurs ont été présentés:
Pour conclure, voici nos principaux enseignements :
L’avenir est agentique : nous passons de simples chatbots à des agents autonomes capables de planifier, collaborer (via des protocoles comme A2A et MCP) et exécuter des workflows. Elastic démocratise cet accès grâce à des outils comme l’Agent Builder, rendant l’IA avancée accessible sans complexité excessive.
La mémoire est la nouvelle frontière : pour construire des agents véritablement utiles, il faut dépasser les limites fixes de tokens. En adoptant le cadre COALA (Épisodique, Procédurale, Sémantique) et en utilisant Elasticsearch pour indexer l’intégralité des historiques de conversation, nous pouvons offrir aux agents une « mémoire infinie », les rendant plus intelligents et plus conscients du contexte au fil du temps.
Les opérations, de la détection à l’action : dans le domaine de l’observabilité, l’IA devient un coéquipier proactif. Avec AI Investigations et le stockage natif OpenTelemetry, l’accent passe de la simple détection d’alertes à l’analyse automatisée des causes profondes et à la remédiation — toujours avec ES|QL assurant une traçabilité transparente.
La simplicité à grande échelle : qu’il s’agisse de gérer des agents ou de superviser l’infrastructure, les outils deviennent plus efficaces. Comme démontré lors de notre session “Fleet Invaders”, gérer des écosystèmes diversifiés avec Elastic Fleet devient plus simple et plus sûr, prouvant que l’échelle ne doit pas rimer avec complexité.
Cette année encore, l’organisation a été à la hauteur et nous remercions Elastic pour la qualité de cet évenement qui a su évoluer pour introduire de vrais retours d’expérience, des sessions techniques instructives, et de la place pour des discussions passionnantes, tout cela dans l’esprit meetup qu’on adore ! Trop souvent ce genre d'évenement se borne à une promotion commerciale, cela montre ainsi la singularité d’Elastic qui a su conserver une vraie place pour la communauté dans son écosystème.
Prêts à rendre votre infrastructure agentique ? L’équipe Adelean est là pour vous aider à naviguer dans cette transition.