
À Haystack US, la communauté de la recherche et de la pertinence s'est réunie pour explorer comment l'IA et les LLMs redéfinissent notre façon de chercher. Découvrons les sujets brûlants de cette année !

Chaque année depuis 2018, Haystack US rassemble chercheurs, ingénieurs et experts en produits travaillant à la pointe de ce que la technologie de recherche peut accomplir.
Organisée par OpenSource Connections et tenue dans la charmante ville de Charlottesville, en Virginie, cette conférence de deux jours a offert un espace unique pour la communauté de la recherche et de la pertinence pour se connecter. De l'évaluation de la pertinence des recherches utilisant des évaluateurs synthétiques, à l’essor de LLMs toujours plus rapides, efficaces et moins coûteux, jusqu'à l’importance de comprendre le comportement des utilisateurs, les sujets de conversation étaient actuels, concrets, et surtout façonnés par des personnes réalisant le travail sur le terrain.
Cette année, l'équipe Adelean a participé avec une présentation d’Amine Gani et Roudy Khoury intitulée Behind the hype: managing billion-scale embeddings in Elasticsearch and OpenSearch. Leur session portait sur la recherche sémantique et comment la gérer efficacement dans un scénario réel avec des milliards d’embeddings. L’accent était mis sur les outils et techniques pour optimiser les coûts sans compromettre les performances et la précision.

Si vous l’avez manquée, vous pourrez regarder cette présentation et toutes les autres conférences sur la chaîne YouTube d’OpenSource Connections dans quelques semaines ! En attendant, découvrons en profondeur les thèmes de l'édition de cette année.
L’une des conversations les plus récurrentes à Haystack cette année tournait autour d’une question apparemment simple : qui décide ce qu’est un “bon” résultat de recherche ? Avec des systèmes de plus en plus complexes et des données qui augmentent de téraoctet en téraoctet, les méthodes d'évaluation traditionnelles, fortement dépendantes d’experts du domaine, atteignent leurs limites en termes de coût et de vitesse. C’est là que les évaluateurs synthétiques entrent en jeu.
Deux présentations ont abordé ce défi sous des angles complémentaires. La présentation de Gurion Marks, Judge Moody’s, proposait d’utiliser des LLMs comme juges de pertinence. Donnez à l’un de ces juges un rôle spécifique (comme un expert en finance examinant le travail d’un stagiaire junior), des critères clairs et quelques exemples, et il peut évaluer la pertinence sémantique avec une vitesse impressionnante, à une fraction du coût des évaluateurs humains. Une direction prometteuse est de combiner plusieurs juges, chacun optimisé pour un angle d'évaluation différent, bien que cette pratique pose le défi de l’augmentation des coûts et de la complexité.
La présentation de Doug Rosenoff a aidé à élargir la perspective, en réfléchissant à l’application des évaluateurs synthétiques dans le domaine éditorial. Elle présentait un framework de test conçu pour effectuer des évaluations reproductibles et ajustables. Le système prend en charge l'évaluation humaine pré et post, facilite la comparaison des configurations et calcule des métriques détaillées comme la fiabilité inter-évaluateur, la précision et les coefficients de corrélation entre les robots et les humains.
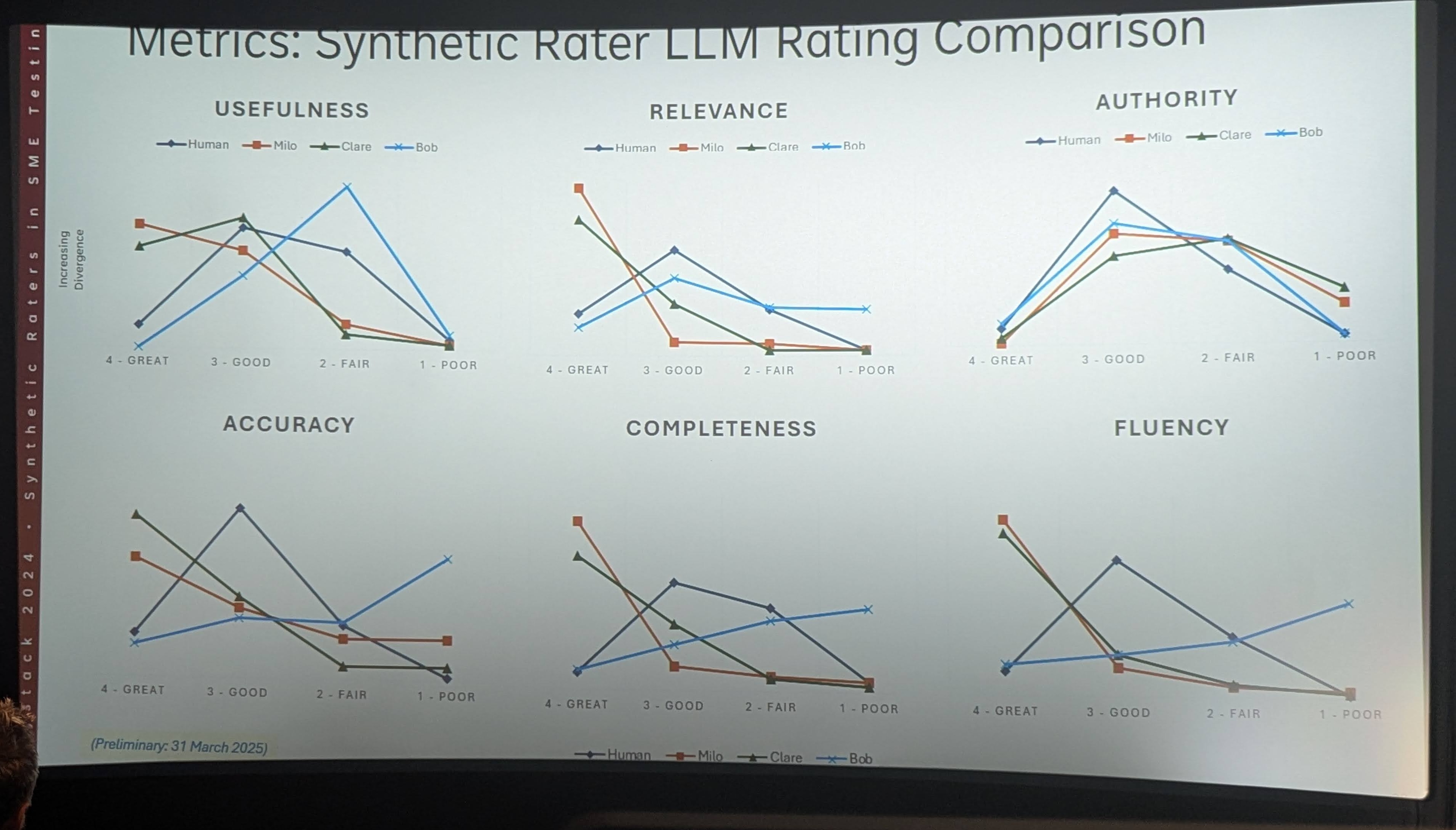
Les chiffres parlent d’eux-mêmes : une expérience a comparé 175 heures d'évaluation humaine avec seulement 40 minutes d'évaluation synthétique. Les performances étaient solides dès le départ, surtout sur des tâches simples. D’autre part, il est également devenu clair que les évaluateurs synthétiques nécessitaient des données d’entraînement mieux organisées par rapport aux évaluateurs humains, et que leurs performances pouvaient diminuer significativement lors de demandes d’analyses plus complexes.
En résumé, les deux présentations ont souligné que pour être fiables, les évaluateurs synthétiques nécessitent un réglage minutieux : ils doivent éviter l’hallucination, être instruits de ne pas deviner et fournir un raisonnement pour chaque décision. Des experts réels sont toujours nécessaires pour vérifier la logique de notation du modèle, mais seulement périodiquement, pour valider le travail du juge plutôt que d’effectuer tout le travail pénible.
Un autre sujet brûlant tout au long de la conférence était le rôle des LLMs dans le changement de la façon dont les gens trouvent et interagissent avec l’information.
J’ai été particulièrement impressionnée par la présentation de Vespa, tenue par Kristian Aune, qui a exploré comment les large language models peuvent permettre aux utilisateurs d’exprimer naturellement leurs préférences de recherche, sans avoir besoin de s’appuyer sur des filtres ou des interfaces rigides.
Une démonstration en direct a montré comment une interface de chatbot pourrait être utilisée pour rechercher des voitures sur un site e-commerce populaire, avec des requêtes comme “Je veux une voiture bon marché mais j’aime me sentir en sécurité sur la route”. Cela suggère une nouvelle expérience d’achat basée sur la conversation, où les résultats sont directement affinés en fonction des requêtes en langage naturel.
Sous le capot, le système fonctionne en traduisant les requêtes des utilisateurs en tenseurs mappés au format JSON, que Vespa utilise ensuite pour classer les documents via une fonction de notation personnalisable. Ces tenseurs représentent des paires clé-valeur liées à des signaux de classement, permettant une évaluation structurée de la pertinence.

Bien que techniquement prometteur, cette approche est rarement utilisée en production, non pas en raison des limitations techniques, mais plutôt parce que les utilisateurs ne sont pas encore familiers avec cette façon de rechercher. Le principal défi, alors, n’est pas le modèle : c’est le modèle mental ! Une bonne conception UX et l'éducation des utilisateurs seront cruciales pour le succès de cette approche.
Quelques sessions ont laissé entrevoir où les choses pourraient aller ensuite. Des entreprises comme Aryn réimaginent la recherche non structurée comme quelque chose de plus proche de l’analytique.
Reconnaissant qu’environ 90% des données d’entreprise sont non structurées, comprenant des documents comme de longs rapports et des entretiens, la plateforme d’Aryn vise à extraire des insights de ce vaste réservoir d’informations.
Les systèmes RAG traditionnels sont limités par la fenêtre de contexte du LLM, et ils ne donnent pas leur meilleur lorsqu’il s’agit de compter et de filtrer. Vous pouvez poser à un RAG des questions assez simples, mais parfois les experts ont besoin d’effectuer des tâches de recherche, avec un schéma sémantique commun.
La réponse d’Aryn à ce problème est un système qui effectue une “deep analytics”, composé de trois éléments clés :

La conclusion de la présentation de Mehul Shah est que ce type d’outil renforce les humains, il ne les remplace pas. Les IA sont d’excellentes machines à deviner, qui peuvent traiter et analyser de vastes quantités de données non structurées, mais le véritable défi est de vérifier indépendamment leur sortie, donc la supervision humaine reste fondamentale.
Parmi les idées les plus concrètes et largement applicables de la conférence, il y avait un rappel que les systèmes de recherche efficaces ne sont pas seulement construits en code, mais sont également façonnés par la compréhension des besoins des utilisateurs. La présentation sur la gestion de produits de recherche présentée par Women of Search, et la présentation d’Aruna Govindaraju sur les insights du comportement utilisateur ont exploré ce thème sous des angles différents mais complémentaires.
Dans la présentation How Great Product Managers Build for Impact, par Audrey Lorberfeld et Samdisha Kapoor, le message central était que la recherche nécessite son propre playbook de gestion de produit. Contrairement aux fonctionnalités plus déterministes, le succès de la recherche est intrinsèquement probabiliste : il est lié à la perception de l’utilisateur, qui est subjective, donc les product managers travaillant dans ce domaine feraient mieux de s’habituer à gérer l’incertitude. Cela signifie commencer par des définitions claires de ce à quoi ressemble le succès, convertir des objectifs flous en métriques, et se concentrer non seulement sur ce qui est livré, mais sur la façon dont cela change le comportement des utilisateurs.

Les meilleures équipes, selon les présentatrices, examinent les schémas dans les logs de recherche plutôt que de réagir à des plaintes ponctuelles. Elles mènent des expériences basées sur des hypothèses, documentent leur prise de décision et impliquent des partenaires pluridisciplinaires dans des conversations continues. Un conseil pratique : inclure les ingénieurs dans les appels utilisateurs, afin que le comportement du système soit placé dans le contexte de la frustration ou de l’amusement réel de l’utilisateur.
Des frameworks comme RICE peuvent aider à prioriser les améliorations, mais ils doivent être adaptés au contexte et toujours réalisés avec un objectif, basés sur des facteurs pratiques comme le type d’entreprise ou la taille de l'équipe. Il est également important d'évaluer les tailles d’opportunité : quel impact pourrait avoir un changement, en termes de revenus ?
La deuxième présentation, Supercharging Search in OpenSearch, a mis en évidence le côté opérationnel de cette philosophie. La présentatrice a montré à quel point les organisations tombent facilement dans le piège de construire sans comprendre. Trop souvent, les logs de recherche sont collectés mais non analysés. Les métriques sont disponibles mais non connectées à la stratégie. Le résultat ? Un chaos créatif.
UBI change cela en donnant aux équipes une boîte à outils pour analyser l’utilisation de la recherche à grande échelle. Un exemple a montré comment les utilisateurs recherchaient constamment par marque, mais ne cliquaient jamais sur le filtre de marque, car il était placé trop bas sur la page. Sans analyse comportementale, la sortie de la fonctionnalité aurait été considérée comme un succès, mais avec elle, le problème devient évident. Les données UBI collectées peuvent également être utilisées pour produire une évaluation de la qualité de pertinence, puis pour améliorer le boosting et le classement de tous types de résultats de recherche, créant essentiellement une boucle de rétroaction qui va de la collecte, à la mesure, au réglage, et retour.
Ce que les deux présentations ont mis en évidence, c’est que comprendre le comportement des utilisateurs n’est pas optionnel si vous voulez construire une recherche impactante. Que vous conceviez une nouvelle fonctionnalité ou que vous essayiez d’améliorer la pertinence, la première étape est toujours la même : déterminer ce que les gens essaient réellement de faire. La bonne nouvelle ? Nous avons de plus en plus d’outils pour faire ce travail.
Parmi les nombreux outils, idées et cas d’utilisation présentés à Haystack cette année, c’est le discours d’ouverture de Rick Hamilton qui a peut-être offert l’enseignement le plus durable. Il a donné le ton pour toute la conférence, rappelant à tous que si l’IA peut améliorer nos capacités, ce sont notre curiosité, notre pensée critique et notre créativité qui tiennent toujours le volant.

L’IA peut devenir un allié puissant dans le travail créatif : en prenant en charge des tâches répétitives ou à faible valeur, elle permet à notre imagination de se concentrer sur des questions de plus haut niveau. Avec l’IA, nous pouvons réaliser une analyse rapide des données et une reconnaissance des schémas, simuler des scénarios réels avec moins de prototypes et d’itérations, explorer des idées, et même obtenir des plans d’apprentissage personnalisés.
Mais à côté de ce potentiel vient un avertissement. À mesure que l’IA devient meilleure pour fournir des réponses, la facilité de l’auto-complétion et des suggestions instantanées peut émousser la pensée critique et mener à l’atrophie des compétences. Le flot de recommandations et de contenu sans fin peut nous distraire d’un travail concentré. Le biais de confirmation constant provenant de la tendance de l’IA à créer des chambres d'écho peut entraîner une homogénéisation des perspectives.
La leçon n'était pas de résister à l’IA, mais de l’utiliser délibérément, de rester créateurs plutôt que simples curateurs. L’innovation, nous a rappelé l’orateur, est un processus de ré-élaboration, d'établissement de connexions entre domaines, de remise en question de ce qui existe déjà. Par conséquent, pour y parvenir, nous devons construire une large base de connaissances pour nous-mêmes, regarder de manière critique les solutions existantes, refuser de se contenter du “assez bon”.
S’il y a un fil conducteur qui a lié tout Haystack 2025, c’est celui-ci : les outils et les technologies sont importants, mais l'état d’esprit l’est davantage. L’IA peut élever notre travail, mais seulement si nous restons intentionnels sur ce que nous construisons, pour qui nous le construisons, et pourquoi c’est important. Et cela, plus que n’importe quelle architecture ou technique unique, est ce qui façonnera l’avenir de la recherche.