
Récemment, OpenSearch a mis en œuvre les connecteurs, une fonctionnalité qui permet de connecter un modèle d'apprentissage automatique sans avoir besoin de le déployer internement sur le cluster. Dans cet article de blog, nous découvrirons comment utiliser les connecteurs et mettre en œuvre un RAG grâce à l'utilisation de connecteurs et d'agents.
Dans le paysage en constante évolution des moteurs de recherche d’aujourd’hui, l’apprentissage automatique joue un rôle crucial dans la façon dont nous recherchons des informations. OpenSearch et Elasticsearch ont intégré de manière transparente des techniques d’apprentissage automatique modernes depuis plusieurs années maintenant, marquant une évolution significative dans la façon dont nous accomplissons différentes tâches, de la simple recherche à des tâches plus complexes en NLP, telles que la classification et la reconnaissance d’entités nommées.
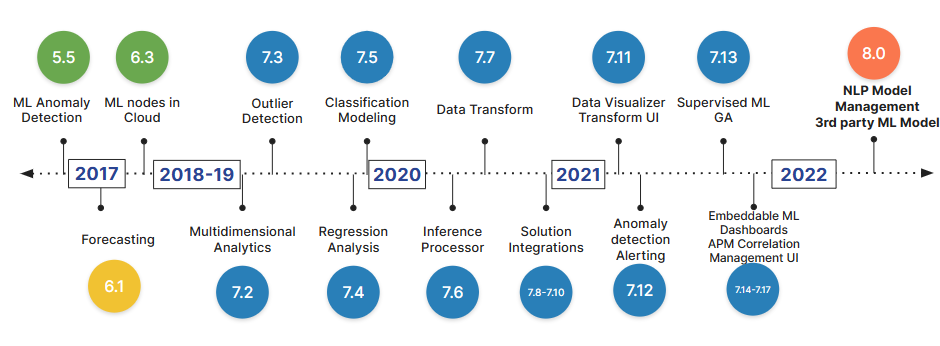
Comme Elasticsearch, OpenSearch offre également une fonctionnalité de gestion des modèles. Cela permet de charger et de déployer nos modèles internement sur notre cluster, comme discuté dans un article de blog précédent “NLP dans OpenSearch”.
Cette fonctionnalité est extrêmement puissante mais limitée, car nous ne pouvons pas déployer n’importe quel modèle que nous désirons; au lieu de cela, nous sommes tenus de respecter des exigences de compatibilité strictes.
De plus, avec la sortie de la version 2.9, OpenSearch a dévoilé des connecteurs, ouvrant ainsi des possibilités excitantes. Explorons-les ensemble.
Les connecteurs nous permettent de connecter n’importe quel modèle déployé sur une plateforme d’apprentissage automatique tierce au cluster sans avoir besoin de déploiement interne. Par défaut, OpenSearch fournit des connecteurs pour plusieurs plateformes, telles que Amazon SageMaker, OpenAI, Cohere et Amazon Bedrock, mais nous pouvons également créer les nôtres, comme nous le verrons dans le prochain chapitre.
Pour l’instant, concentrons-nous sur les connecteurs par défaut. Dans cet exemple, nous verrons comment connecter et utiliser le modèle d’intégration ADA d’OpenAI.
Tout d’abord, il est nécessaire d’activer les connecteurs en mettant à jour les paramètres du cluster :
PUT /_cluster/settings
{
"persistent": {
"plugins.ml_commons.connector_access_control_enabled": true
}
}
Une fois cela fait, nous pouvons utiliser un modèle standard pour créer notre connecteur. Dans cet exemple, nous allons utiliser le modèle de base ADA d’OpenAI :
POST /_plugins/_ml/connectors/_create
{
"name": "embedding_ada",
"description": "Mon connecteur pour créer une intégration à l'aide du modèle ada",
"version": "1.0",
"protocol": "http",
"parameters": {
"model": "text-embedding-ada-002"
},
"credential": {
"openAI_key": "<VEUILLEZ AJOUTER VOTRE CLÉ API OPENAI ICI>"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://api.openai.com/v1/embeddings",
"headers": {
"Authorization": "Bearer ${credential.openAI_key}"
},
"request_body": "{ \"input\": ${parameters.input}, \"model\": \"${parameters.model}\" }",
"pre_process_function": "connector.pre_process.openai.embedding",
"post_process_function": "connector.post_process.openai.embedding"
}
]
}
Remarquez que nous associons l’action ‘predict’ à une endpoint, qui correspond à l’endpoint d’intégration OpenAI. Les paramètres spécifiés dans les objets request_body sont soit spécifiés au niveau du connecteur, comme parameters.model, soit lors de l’appel à la prédiction, comme dans le cas de parameters.input.
Une fois cela fait, le tableau de bord OpenSearch renverra l’identifiant du connecteur :
{
"connector_id": "OyB0josB2yd36FqHy3lO"
}
Utilisez l’identifiant du connecteur pour enregistrer le modèle, tout simplement comme ceci :
POST /_plugins/_ml/models/_register
{
"name": "Modèle d'intégration OpenAI",
"function_name": "remote",
"description": "modèle de test",
"connector_id": "OyB0josB2yd36FqHy3lO"
}
Le tableau de bord OpenSearch renverra ensuite le task_id, son état et l’ID du modèle.
{
"task_id": "E-6oOI8BPOcrd1NgZ5nk",
"status": "CREATED",
"model_id": "FO6oOI8BPOcrd1NgaJkd"
}
Enfin, nous pouvons tester le modèle en utilisant l’API de prédiction et l’ID du modèle, tel que spécifié à l’intérieur du connecteur :
POST /_plugins/_ml/models/FO6oOI8BPOcrd1NgaJkd/_predict
{
"parameters": {
"input": [ "Quelle est la signification de la vie?" ]
}
}
Un autre cas d’utilisation courant des connecteurs est d’utiliser notre propre modèle. Dans ce scénario, il n’y a pas de modèle de base, et c’est à nous de créer un.
Pour cet exemple, nous utiliserons un modèle Hugging Face déployé à distance tout en mettant en œuvre un RAG open-source complet (Retrieval-Augmented Generation). Cela nous permettra d’utiliser des connecteurs personnalisés, de comprendre RAG et d’apprendre à le mettre en œuvre à l’aide d’agents. De plus, nous revisiterons la génération d’intégrations à l’aide d’un modèle déployé localement (bien que nous ne soyons pas obligés d’utiliser la recherche vectorielle pour RAG, puisque nous pouvons nous appuyer sur une recherche lexicale classique).
L’architecture de notre RAG va ressembler à ceci :
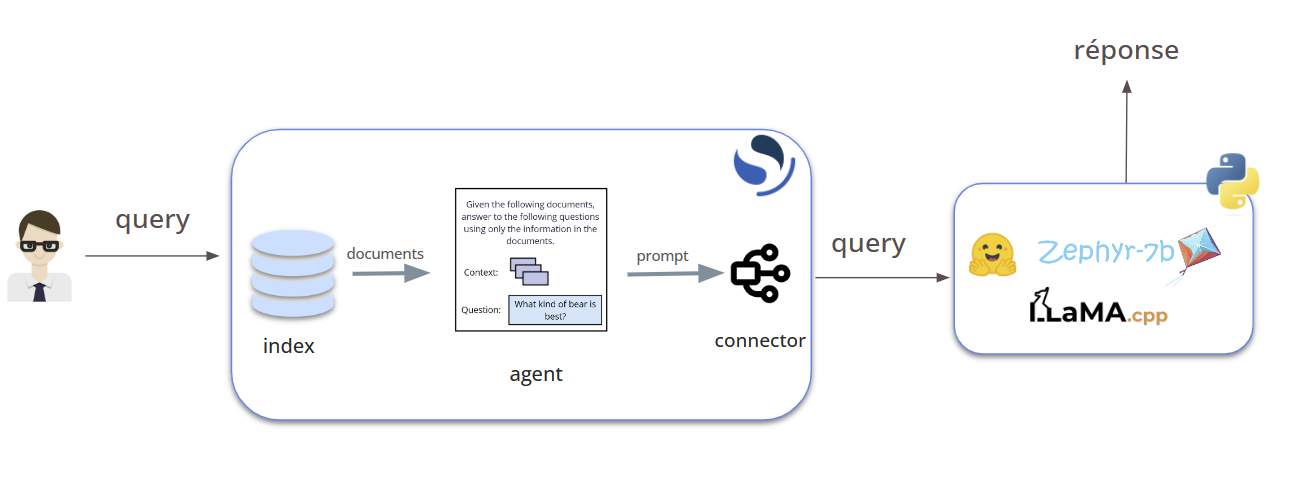
Si vous voulez en savoir plus sur RAG, vous pouvez suivre notre article : Un guide complet sur RAG Open Source.
Assez de bavardages, plongeons dans le processus :
Tout d’abord, il sera nécessaire de préparer notre cluster :
PUT /_cluster/settings
{
"persistent": {
"plugins.ml_commons.memory_feature_enabled": true,
"plugins.ml_commons.rag_pipeline_feature_enabled": true,
"plugins.ml_commons.agent_framework_enabled": true,
"plugins.ml_commons.only_run_on_ml_node": false,
"plugins.ml_commons.connector_access_control_enabled": true
}
}
Dans ce cas, certaines options ne sont pas obligatoires. Par exemple, memory_feature active la fonction de conversation de rag : le grand modèle de langue se souviendra de l’historique de la conversation afin de donner des réponses plus précises et pertinentes. Une autre option qui n’est pas obligatoire, mais nécessaire dans le cas où vous avez un cluster sans nœud d’apprentissage automatique, est only_run_on_ml_node.
Ensuite, nous devons mettre à jour la liste des endpoints de confiance. Dans ce cas, j’ajoute un regex qui permet tous les types d’endpoints. Cependant, il est bon de pratiquer l’utilisation d’un regex plus restrictif pour autoriser uniquement les endpoints spécifiques à votre cas d’utilisation.
PUT /_cluster/settings
{
"persistent": {
"plugins.ml_commons.trusted_connector_endpoints_regex": [
"^https://runtime\\.sagemaker\\..*[a-z0-9-]\\.amazonaws\\.com/.*$",
"^https://api\\.openai\\.com/.*$",
"^https://api\\.cohere\\.ai/.*$",
"^https://bedrock-runtime\\..*[a-z0-9-]\\.amazonaws\\.com/.*$",
".*"
]
}
}
Enregistrons et déployons notre modèle d’intégration, que nous utiliserons pour créer des vecteurs à partir de nos données afin de réaliser une recherche vectorielle.
POST /_plugins/_ml/models/_register?deploy=true
{
"name": "huggingface/sentence-transformers/all-MiniLM-L12-v2",
"version": "1.0.1",
"model_format": "TORCH_SCRIPT"
}
Une fois que nous avons préparé le pipeline d’intégration et notre index (vous pouvez trouver plus d’informations sur la façon de le faire : NLP dans OpenSearch), il est temps de préparer notre connecteur :
POST /_plugins/_ml/connectors/_create
{
"name": "Llama_CPP Chat Connector",
"description": "Le connecteur vers mes propres modèles Llama_CPP",
"version": 5,
"protocol": "http",
"parameters": {
"endpoint": "Votre adresse"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "${parameters.endpoint}/chat",
"request_body": "{ \"message\": \"${parameters.message}\" }"
}]
}
Une fois que nous avons notre connecteur_id, il est temps d’enregistrer notre modèle :
POST /_plugins/_ml/models/_register
{
"name": "zephyr-7b",
"function_name": "remote",
"description": "modèle de test",
"connector_id": "XhoFSY8BAdMqvSY3Teue"
}
Nous pouvons maintenant utiliser l’ID du modèle pour déployer le modèle :
POST /_plugins/_ml/models/YxoFSY8BAdMqvSY3butu/_deploy
Enfin, nous pouvons utiliser un agent d’apprentissage automatique (disponible à partir de la version 2.13) pour coupler la phase de récupération, en utilisant la recherche vectorielle, et le grand modèle de langue. Nous allons utiliser cette dernière partie pour définir l’invite.
POST /_plugins/_ml/agents/_register
{
"name": "Test_Agent_For_RAG",
"type": "flow",
"description": "this is a test agent",
"tools": [
{
"type": "VectorDBTool",
"parameters": {
"model_id": "s7Ay4Y4BFgAnzku3kwJC",
"index": "my_test_data",
"embedding_field": "embedding",
"source_field": ["text"],
"k":1,
"input": "${parameters.question}"
}
},
{
"type": "MLModelTool",
"description": "A general tool to answer any question",
"parameters": {
"memory_id": "kF72SI8BwKcdGeEaycUI",
"model_id": "YxoFSY8BAdMqvSY3butu",
"message": "This is your context:\n${parameters.VectorDBTool.output}\n This is your question:${parameters.question}\n Give an answer based on the context.",
"response_field": "result"
}
}
]
}
Pour tester le système RAG,
exécutez simplement l’agent rag, en utilisant l’agent_id. Par exemple :
POST /_plugins/_ml/agents/ahoHSY8BAdMqvSY3ouuD/_execute
{
"parameters": {
"question": "quelle est l'augmentation de la population de Seattle de 2021 à 2023"
}
}
En conclusion, l’avènement des connecteurs dans OpenSearch marque une étape significative dans la simplification de l’intégration des modèles d’apprentissage automatique avec la plateforme. Grâce aux connecteurs, les utilisateurs peuvent connecter de manière transparente des modèles d’apprentissage automatique tiers sans avoir besoin de déploiement interne, élargissant ainsi l’horizon des possibilités pour exploiter l’apprentissage automatique dans les applications de recherche.