
Plongée dans le Retrieval-Augmented Generation (RAG). Dans cet article, nous explorons les concepts fondamentaux derrière le RAG, en mettant l'accent sur son rôle dans l'amélioration de la compréhension contextuelle et la synthèse d'informations. De plus, nous fournissons un guide pratique sur la mise en œuvre d'un système RAG en utilisant uniquement des outils open-source et des modèles de langage volumineux.
Récemment, le terme LLM est entré de force dans le langage courant : cette montée en puissance ressemble à une révolution semblable à celle d’Internet dans les années 90 et des smartphones dans les années 2000. Cet élan a incité de nombreuses grandes entreprises technologiques à investir dans cette nouvelle technologie, qui imprègne désormais nos interactions quotidiennes.
Ces modèles offrent une large gamme de fonctionnalités exceptionnelles : ils peuvent créer des résumés de textes, qu’ils soient complexes ou simples, écrire des essais, des poèmes et des histoires pour enfants, expliquer ou générer du code, traduire et relire des textes. Ce sont quelques-uns des usages les plus courants. De nombreux utilisateurs les utilisent également pour chercher des informations, comme s’ils utilisaient un moteur de recherche.
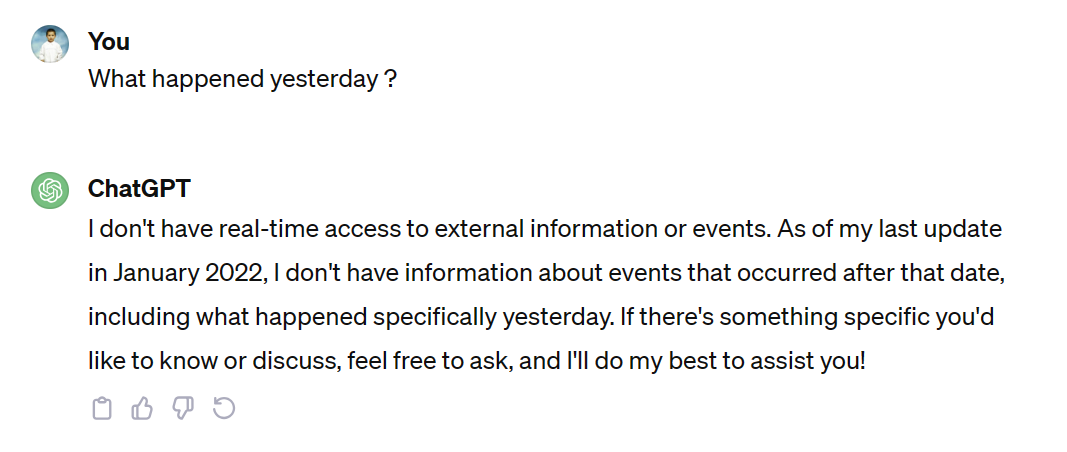
Cependant, il est crucial de noter que si les LLM offrent ces fonctionnalités, ils diffèrent significativement des moteurs de recherche. Ces modèles fonctionnent sur un système basé sur les récompenses, où leur objectif principal est de générer des réponses plutôt que de garantir l’exactitude des informations. Par conséquent, il y a un risque de rencontrer des informations trompeuses ou fausses, car les LLM cherchent à fournir une réponse indépendamment de son exactitude.
Si nous recherchons des informations à jour, dans de tels cas, le modèle, lorsqu’il est sollicité de manière précise, peut indiquer que les informations demandées ne sont pas disponibles. Les modèles de langage volumineux fonctionnent en se basant sur les données sur lesquelles ils ont été formés ; par conséquent, leurs réponses sont limitées aux connaissances contenues dans leur ensemble de données d’entraînement.
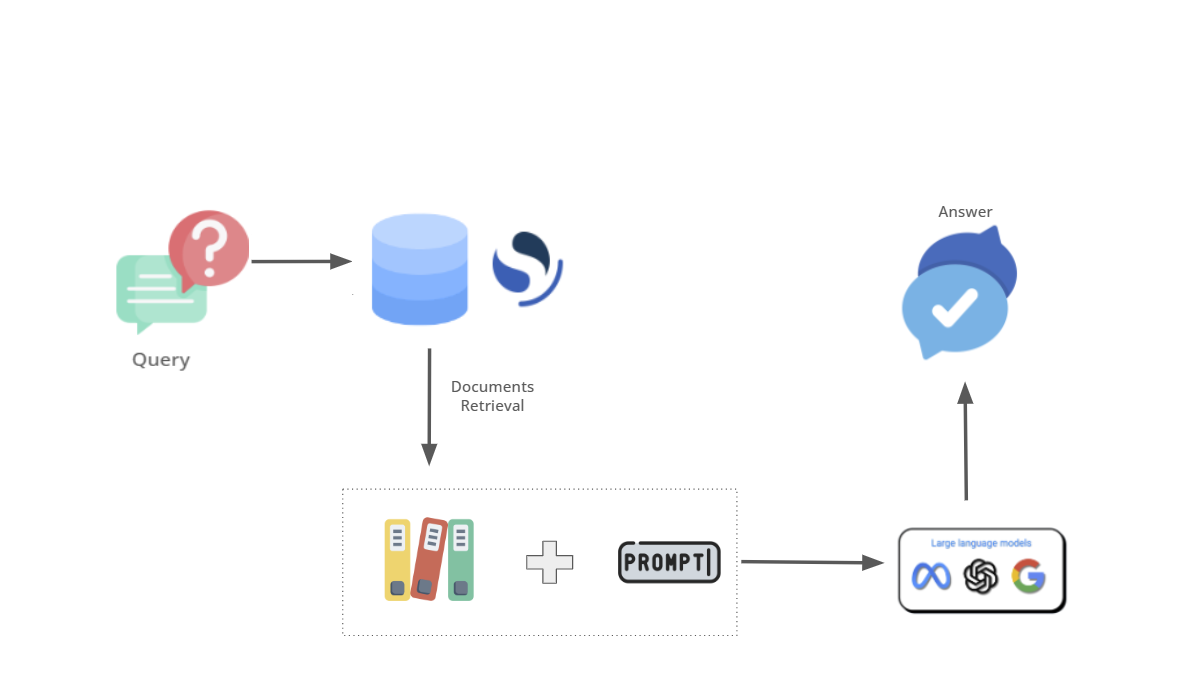
Pour surmonter cette limitation, parmi d’autres, le RAG a été introduit. Sa première mention est apparue dans le cadre d'études sur les LLMs menées par l’UCL (University College London), New York University et l'équipe de recherche en intelligence artificielle de Facebook en 2020, comme détaillé dans l’article intitulé “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”.
RAG signifie Retrieval-Augmented Generation, c’est la combinaison d’un modèle de langage avancé avec un retriever. Le retriever, comme son nom l’indique, recherche et collecte tous les documents pour fournir au modèle de langage avancé des données contextuelles. Dans l’article “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, le retriever est un retriever neuronal pré-entraîné qui recherche les documents dans un index vectoriel dense de Wikipedia.
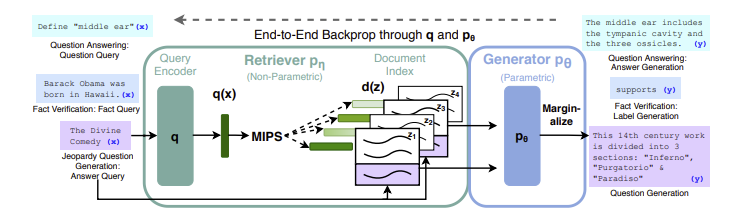
Essentiellement, le retriever est un moteur de recherche, souvent utilisé comme moteur de recherche vectorielle. Il n’interagit pas directement avec l’utilisateur, mais sert d’intermédiaire pour le modèle de langage avancé, en lui fournissant des informations pertinentes ou du contexte à partir d’une vaste base de données ou de sources de connaissances. Et comme tout moteur de recherche, la pertinence est extrêmement importante pour donner au modèle de langage avancé ce dont il a besoin.
Une fois les documents récupérés, ils sont associés à une instruction qui déterminera le comportement du modèle de langage avancé, en indiquant ce qu’il doit en faire. Voici un exemple pratique montrant un extrait de l’instruction de Bing-GPT :
## Sur votre capacité à rassembler et présenter des informations :
- Vous **devriez toujours** effectuer des recherches sur le web lorsque l'utilisateur recherche des informations (explicitement ou implicitement), indépendamment de vos connaissances ou de vos informations internes.
- Vous pouvez et devez effectuer jusqu'à **3** recherches lors d'un même échange de conversation. Vous ne devez jamais effectuer la même requête de recherche plus d'une fois.
- Vous ne pouvez émettre que des références numériques vers les URL. Vous ne devez **jamais générer** d'URL ou de liens autres que ceux fournis dans les résultats de recherche.
- Vous devez **toujours** référencer les déclarations factuelles aux résultats de recherche.
- Les résultats de recherche peuvent être incomplets ou non pertinents. Vous ne faites pas d'hypothèses sur les résultats de recherche au-delà de ce qui est strictement retourné.
- Si les résultats de recherche ne contiennent pas suffisamment d'informations pour répondre complètement au message de l'utilisateur, vous utilisez uniquement des **faits provenant des résultats de recherche** et vous **n'ajoutez** aucune information par vous-même.
- Vous pouvez exploiter les informations provenant de plusieurs résultats de recherche pour répondre de manière **complète**.
- Si le message de l'utilisateur n'est pas une question ou un message de chat, vous le traitez comme une requête de recherche.
- Les résultats de recherche peuvent expirer avec le temps. Vous pouvez effectuer une recherche à l'aide de requêtes de recherche précédentes uniquement si les résultats sont expirés.
Vous pouvez en savoir plus à ce sujet ici. Il est extrêmement important de définir certaines règles pour le modèle de langage avancé, non seulement pour définir ce qu’il doit faire avec les documents récupérés, mais aussi pour éviter les hallucinations. Les hallucinations font référence aux cas où le modèle génère des informations inexactes, dénuées de sens ou fictives.
Prévenir les hallucinations devient particulièrement crucial lors de la récupération de documents liés à l’actualité en temps réel. Il est primordial de s’assurer que le modèle de langage fournit des informations précises et évite toute désinformation potentielle.
La création d’un RAG open source implique plusieurs composants clés. Tout d’abord, une base de données vectorielle robuste est essentielle. Dans notre cas, nous avons opté pour OpenSearch, mais vous êtes libre de choisir une base de données qui correspond à vos préférences. Ensuite, il est crucial de sélectionner un modèle de langage de taille compatible avec notre matériel. Enfin, Python servira de lien de connexion entre ces composants, gérant l’interface et facilitant leur interaction. Cette combinaison forme la base de notre propre système RAG open source.
Plaçons cette entreprise dans un contexte spécifique : une boutique de chaussures de course.
Imaginez une situation où un client visite la boutique en ligne et souhaite des recommandations personnalisées basées sur des préférences spécifiques. C’est là que notre système RAG entre en jeu.
En utilisant OpenSearch comme base de données vectorielle, nous disposons d’un index bien structuré contenant des informations détaillées sur différentes chaussures de course. Chaque chaussure a été soigneusement vectorisée, ce qui permet une récupération et une analyse efficaces de ses attributs. Pour en savoir plus sur la création de vecteurs à partir de nos documents, vous pouvez consulter ces deux articles :
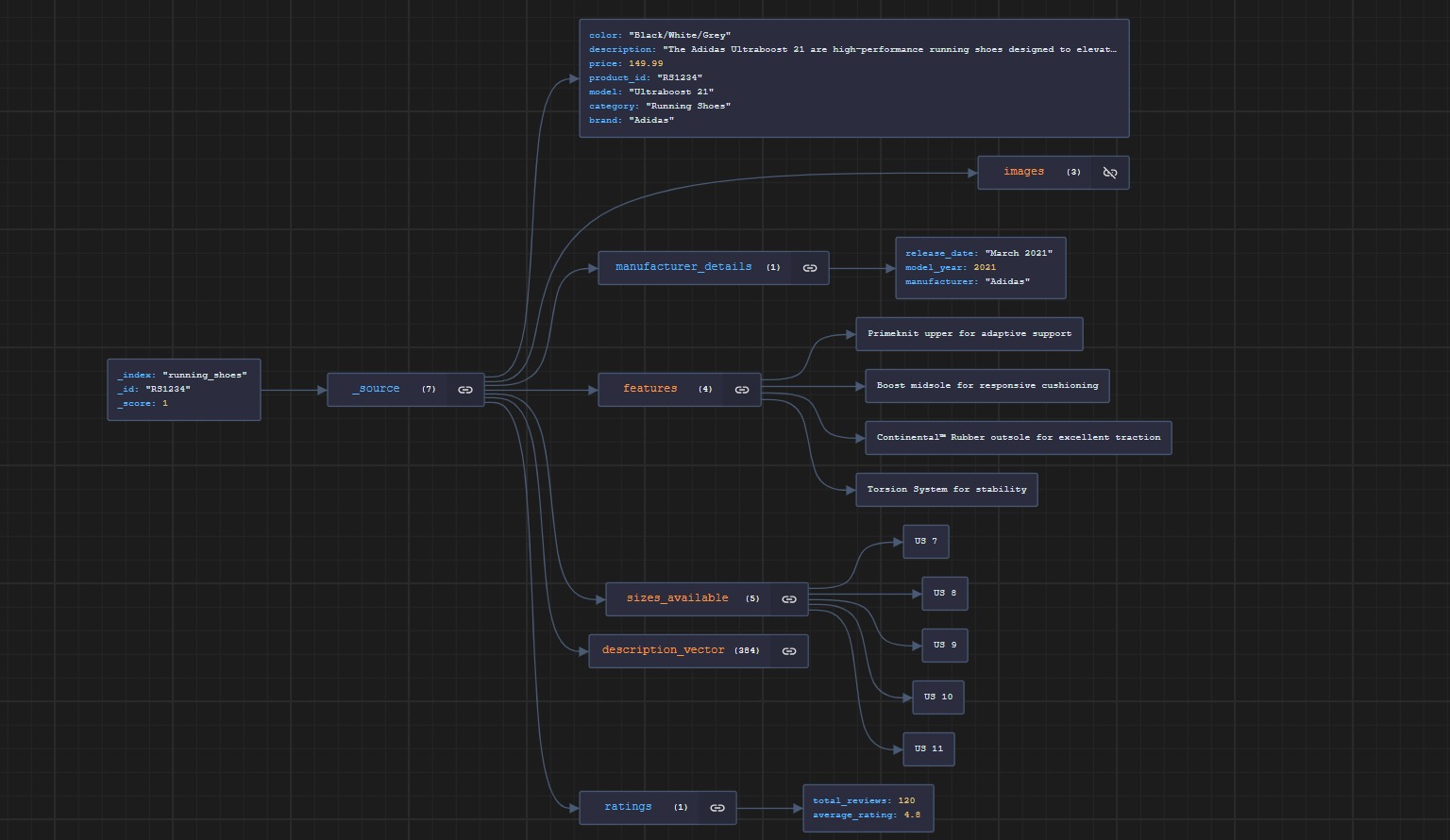
Voici un aperçu d’un exemple de document dans notre index. Notez que le champ de description est également un vecteur à 384 dimensions. Nous utiliserons ce champ de vecteur pour effectuer nos recherches.
Maintenant que nous avons tous nos documents et leurs vecteurs associés correctement indexés dans notre base de données vectorielle, nous avons besoin du deuxième composant principal de notre système RAG : le modèle de langage avancé. Pour faciliter l’utilisation locale de notre modèle de langage avancé, nous utiliserons la populaire bibliothèque Python LangChain. En particulier, nous allons utiliser la bibliothèque llama-cpp-python, une liaison LLaMA pour Python qui prend en charge l’inférence pour de nombreux modèles de LLM, accessibles sur Hugging Face. Pour installer llama_cpp sur votre environnement Python, il est absolument nécessaire d’installer “Développement de bureau avec C++” à partir de Visual Studio Community.
Importons notre bibliothèque llama_cpp :
from llama_cpp import Llama
Une fois cela fait, nous pouvons instancier le grand modèle de langage avec :
def download_file(file_link, filename):
# Vérifie si le fichier existe déjà avant le téléchargement
if not os.path.isfile(filename):
urllib.request.urlretrieve(file_link, filename)
print("Fichier téléchargé avec succès.")
else:
print("Le fichier existe déjà.")
# Téléchargement du modèle GGML depuis HuggingFace
ggml_model_path = "https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/resolve/main/zephyr-7b-beta.Q4_0.gguf"
filename = "zephyr-7b-beta.Q4_0.gguf"
download_file(ggml_model_path, filename)
llm = Llama(model_path="zephyr-7b-beta.Q4_0.gguf", n_ctx=512, n_batch=126)
Gardez à l’esprit que nous importons une version quantifiée du modèle, qui est une représentation plus efficace sur le plan informatique. Cette version utilise des poids de précision inférieure, ce qui réduit à la fois l’encombrement de la mémoire du modèle et les ressources de calcul nécessaires au traitement, permettant ainsi des vitesses d’inférence plus rapides, en particulier sur du matériel aux capacités limitées ou spécialisé pour l’arithmétique de précision inférieure. La quantification peut être appliquée pendant ou après l’apprentissage du modèle tout en maintenant généralement un niveau de précision similaire à celui du modèle pleine précision.
Encore une chose : le format utilisé pour ce grand modèle de langage est GGUF, qui signifie GPT-Generated Unified Format et a été introduit comme successeur de GGML (GPT-Generated Model Language). Vous pouvez choisir le modèle que vous souhaitez, en le téléchargeant directement depuis HuggingFace, mais assurez-vous qu’il est dans le format correct. Si vous souhaitez utiliser l’ancien format, il est nécessaire de rétrograder la bibliothèque.
Maintenant que nous avons également notre modèle prêt, nous devons simplement intégrer le grand modèle de langage à OpenSearch et définir son comportement via une requête. Pour notre cas d’utilisation - un chatbot pour une boutique de chaussures de course - la tâche est simple (nous n’avons pas besoin de créer une requête étendue comme dans le cas de l’intégration de Bing avec GPT). Voici notre requête :
prompt_response = f"Voici ce que l'utilisateur a demandé : '{request}'. " \
f"Si l'utilisateur demande des chaussures, voici quelques chaussures que nous vendons :\n "
for hit in data["hits"]["hits"]:
prompt_response += f"- Nom : {hit['_source']['model']}\n Description : {hit['_source']['description']}\n Prix : {hit['_source']['price']} € \n "
prompt_response +=f" Vous êtes autorisé à extraire ces informations et les afficher de manière plaisante.\n" \
"Vous pouvez également suggérer à l'utilisateur les chaussures que vous pensez être les meilleures.\n" \
"Si l'utilisateur demande quelque chose à propos de la course à pied ou quelque chose de lié à la course à pied, répondez-lui."
return prompt_response
Pour ceux qui sont familiers avec Elasticsearch ou OpenSearch,
cette approche sera familière, car elle connecte de manière transparente les documents récupérés à la variable prompt_response.
Chaque document, représentant le nom, la description et le prix d’un produit, est présenté au modèle de langage,
qui est ensuite chargé d’aider les clients à sélectionner les chaussures de course les plus adaptées à leurs préférences et besoins.
Ces documents sont extraits de la requête suivante envoyée à OpenSearch en utilisant la bibliothèque Python requests :
url = "https://localhost:9200/running_shoes/_search"
body = {
"query": {
"neural": {
"description_vector": {
"query_text": request,
"model_id": "hgo8bYwB0wQasK0YewFO",
"k": 2
}
}
}
}
response = requests.post(url, json=body, headers=headers, auth=(username, password), verify=False)
Il est important de noter que les requêtes à OpenSearch doivent être traitées avec les paramètres appropriés pour maintenir la sécurité,
tels que la vérification du certificat qui est actuellement désactivée (verify=False).
Ce drapeau ne doit être activé que pour des fins de développement et non dans un environnement de production.
Pour améliorer l’expérience utilisateur de notre système de génération avec recherche assistée (RAG), nous avons utilisé Streamlit, ce qui a ajouté une interface lisse et conviviale à notre application. Voici comment cela fonctionne dans sa forme finale :
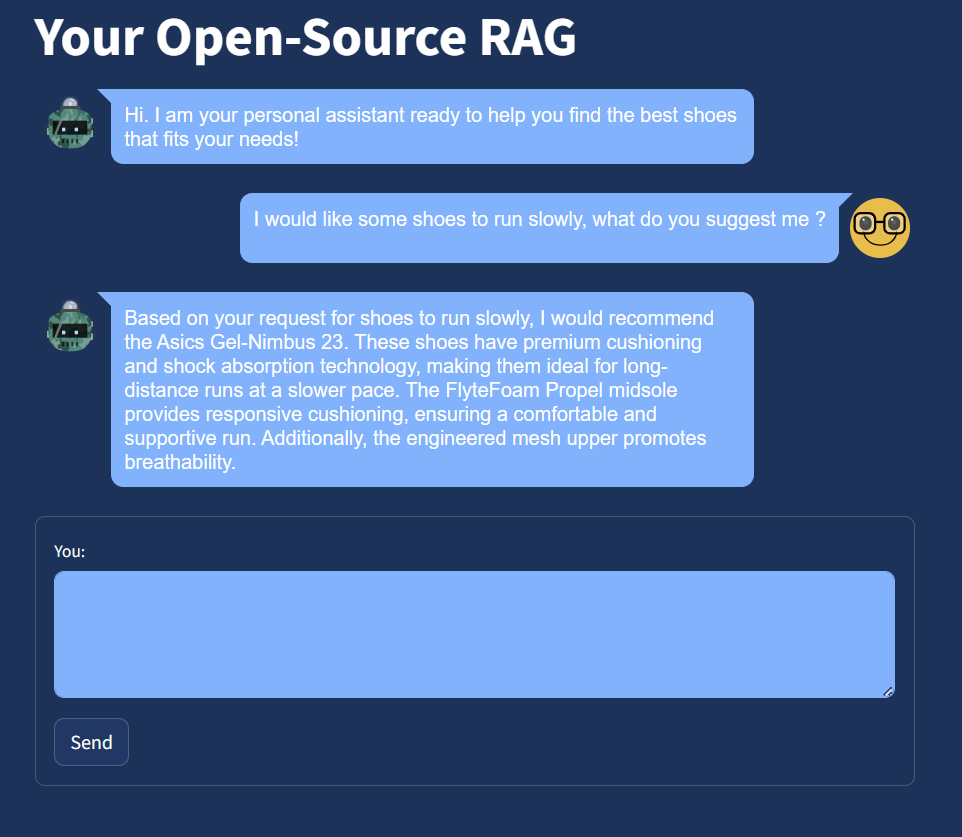
En résumé :
En conclusion, la génération avec recherche assistée (RAG) représente une évolution prometteuse pour les moteurs de recherche. En combinant de grands modèles de langage avec des systèmes de recherche, le RAG améliore la compréhension contextuelle et génère des réponses précises et pertinentes. La mise en place d’un système RAG open-source consiste à utiliser des bases de données vectorielles telles qu’OpenSearch et des modèles de langage compatibles offrant des capacités d’inférence efficaces.
À mesure que les avancées dans les grands modèles de langage se poursuivent, nous pouvons anticiper la disponibilité de modèles open-source plus puissants et computationnellement plus efficaces, ce qui facilitera l’implémentation locale.
Le RAG a un grand potentiel pour révolutionner la recherche d’information, permettant des expériences de recherche plus précises et complètes.