
Découvrez la recherche vectorielle et comment l'implémenter à l'aide de la librairie JINA, y compris les documents array pour le vector-embedding, image-embedding, etc.
Récemment, nous avons assisté à un événement organisé par JINA et OpenSource Connection où nous avons pu en savoir plus sur l’ensemble des outils JINA et ses applications en recherche vectorielle. Au cours de l'événement, nous avons eu l’occasion d’entendre des experts dans le domaine et découvrir les derniers développements et les meilleures pratiques en matière d’utilisation de l’ensemble des outils JINA pour la recherche vectorielle. Nous avons également pu nouer des contacts avec d’autres professionnels du domaine et obtenir des informations précieuses sur la manière dont JINA est utilisé dans des applications réelles.
L'événement a été une excellente occasion d’approfondir notre compréhension de l’ensemble des outils JINA et de ses capacités, et nous sommes repartis avec une nouvelle appréciation de la puissance et de la polyvalence de ces outils.
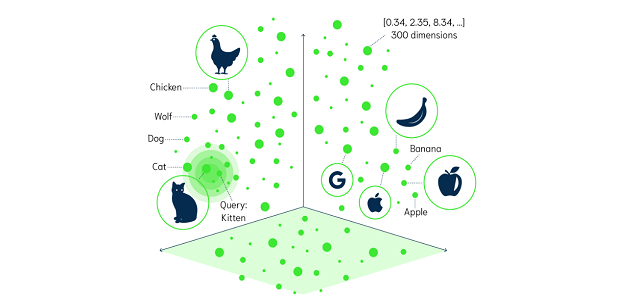
La recherche vectorielle est une approche moderne de la recherche d’informations qui utilise des vecteurs denses, pour représenter les données et effectuer une recherche basée sur la similarité sémantique. Dans la recherche vectorielle, les données sont transformées en vecteurs denses qui capturent l’essence des données dans un format compact et forme continue, et la recherche est effectuée sur la base de la similarité des vecteurs, plutôt que sur la simple correspondance des mots-clés.
JINA est une librairie open source à haute performance dans le domaine de la recherche vectorielle, qui fournit un cadre flexible et facile à utiliser pour créer des applications basées sur cette technologie. Avec JINA, vous pouvez facilement implémenter la recherche vectorielle en utilisant une combinaison entre “pre-trained embeddings” et des algorithmes de deep learning.
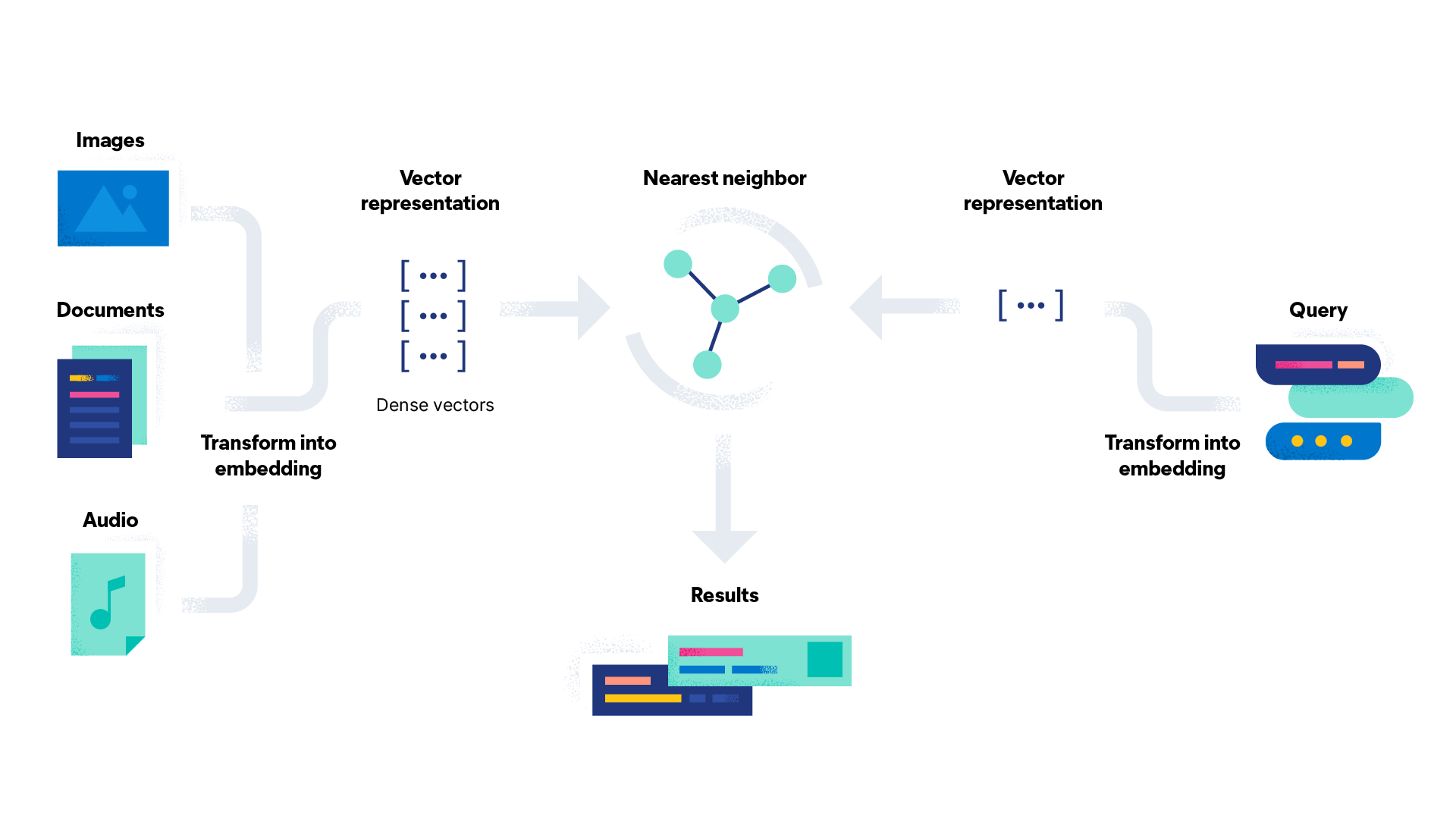
Avec les outils de la librairie JINA, vous pouvez utiliser des doc-array pour stocker et manipuler des vecteurs, ou embeddings, qui représentent vos données. Le doc-array est une structure de données qui permet de stocker plusieurs documents et leurs embedding de manière compacte et efficace. Pour l’utiliser dans le contexte du “vector-embedding”, vous pouvez vous servir des librairies de deep learning intégrées dans JINA, comme TensorFlow ou PyTorch, pour extraire les embeddings de vos données, et les stocker dans le doc-array.
Une autre façon d’utiliser doc-array pour l’intégration vectorielle consiste à utiliser la technique de l’ “embedding features hashing”: c’est une technique qui mappe des variables catégorielles (par exemple, des noms de produits, des catégories de produits, des adresses e-mail, etc.) à des vecteurs denses, appelés embeddings. Dans JINA, vous pouvez utiliser le “embedding feature hashing” pour convertir des variables catégorielles en vecteurs denses, en utilisant une fonction de hachage, et les stocker dans le doc-array. Cela peut être utile lorsque vous avez un grand nombre de variables catégorielles, car cela peut réduire la dimensionnalité de vos données et améliorer les performances de vos applications de recherche.
Voici un exemple de la façon dont vous pouvez utiliser JINA pour implémenter la recherche vectorielle:
from docarray import Document, DocumentArray
d = Document(uri='https://www.gutenberg.org/files/1342/1342-0.txt').load_uri_to_text()
da = DocumentArray(Document(text=s.strip()) for s in d.text.split('\n') if s.strip())
da.apply(Document.embed_feature_hashing, backend='process')
q = (
Document(text='she smiled too much')
.embed_feature_hashing()
.match(da, metric='jaccard', use_scipy=True)
)
print(q.matches[:5, ('text', 'scores__jaccard__value')])
Dans JINA, vous pouvez également utiliser l’embedding pour la recherche d’images, ce qui est le processus de conversion d’images en vecteurs denses, qui capturent l’essence de l’image dans un format compact et forme continue. En utilisant l’embedding des images, vous pouvez rechercher une image en vous appuyant sur la similarité sémantique, plutôt que de simplement sur la similarité des pixels.
L’importance de la sémantique dans la recherche d’images est qu’elle vous permet de rechercher les images en fonction de leur signification, plutôt que simplement leur apparence. Par exemple, si vous recherchez des images de chiens, vous pouvez récupérer des images de chiens de différentes races, couleurs et tailles, tant qu’ils sont sémantiquement similaires. Cela peut vous aider à récupérer des images plus pertinentes et à améliorer l’expérience utilisateur de vos applications de recherche.
Voici un exemple d’utilisation de Docarray pour comparer différentes images représentant différents sujets dans différentes positions.
import torchvision
from docarray import Document, DocumentArray
def preproc(d: Document):
return (
d.load_uri_to_image_tensor() # load
.set_image_tensor_normalization() # normalize color
.set_image_tensor_channel_axis(-1, 0)
) # switch color axis for the PyTorch model later
model = torchvision.models.resnet50(pretrained=True) # load ResNet50
left_da = (DocumentArray.pull('demo-leftda', show_progress=True)[0:1000].apply(preproc).embed(model, device='cuda'))
right_da = (DocumentArray.pull('demo-rightda', show_progress=True)[0:1000].apply(preproc).embed(model, device='cuda'))
left_da.match(right_da, limit=9)
for d in left_da:
for m in d.matches:
print(d.matches[0], d.matches[0].scores['cosine'].value)
#Plotting images-matches
(
DocumentArray(left_da[8].matches, copy=True)
.apply(
lambda d: d.set_image_tensor_channel_axis(
0, -1
).set_image_tensor_inv_normalization()
)
.plot_image_sprites()
)
(
DocumentArray(left_da[8], copy=True)
.apply(
lambda d: d.set_image_tensor_channel_axis(
0, -1
).set_image_tensor_inv_normalization()
)
.plot_image_sprites()
)
CLIP signifie Contrastive Language-Image Pre-Training. Il s’agit d’un modèle pre-entrainé sur un grand ensemble de données d’images et leurs légendes ou descriptions associées, lui permettant d’apprendre à identifier et à comprendre le contenu des images en fonction des mots utilisés pour les décrire.
CLIP-as-service est un service à faible latence et à haute évolutivité pour l’intégration d’images et de texte. Il peut être facilement intégré en tant que microservice dans des solutions de recherche neuronale.
Voici un exemple d’utilisation de clip-as-service. Le modèle recherchera sur l’ensemble de nos données, pour trouver les neuf meilleures images correspondant à la chaîne d’entrée.
pip install clip-client
pip install docarray
from docarray import DocumentArray
from clip_client import Client
c = Client('grpcs://demo-cas.jina.ai:2096')
c.profile
da = DocumentArray.from_files(['left/*.jpg', 'right/*.jpg'])
da.plot_image_sprites()
da = c.encode(da[0:5000],show_progress=True)
while True:
vec = c.encode([input('sentence> ')])
r = da.find(query=vec, limit=9)
r[0].plot_image_sprites()
Pour conclure, la recherche vectorielle est un outil puissant qui a le potentiel de révolutionner la façon dont nous recherchons et analysons des données complexes.
Elle gagne rapidement du terrain dans la communauté des sciences des données, et de nombreuses entreprises l’utilisent déjà pour améliorer leurs capacités de recherche. De plus en plus de recherches étant menées dans ce domaine, nous pouvons nous attendre à voir des utilisations encore plus innovantes de la recherche vectorielle, et elle deviendra probablement un outil indispensable pour l’analyse des données dans les années à venir.