
Search is evolving faster than ever, and technologies like OpenSearch are leading the way. In this blog, we’ll explore the latest OpenSearch features such as agents and the Model Context Protocol, that unlock new superpowers for building next-generation rag applications.
Over the last decade, the world of search engines has been shaken by a technological earthquake. We’ve moved from search engines based solely on keywords to true virtual assistants, capable of answering almost any question, retrieving information directly from the web (see Perplexity) or from a personal knowledge base (like All.site).
OpenSearch has kept pace with this entire evolution. Today, its latest release—version 3.2, offers dozens of new features that enable us to build more powerful and intelligent search engines.
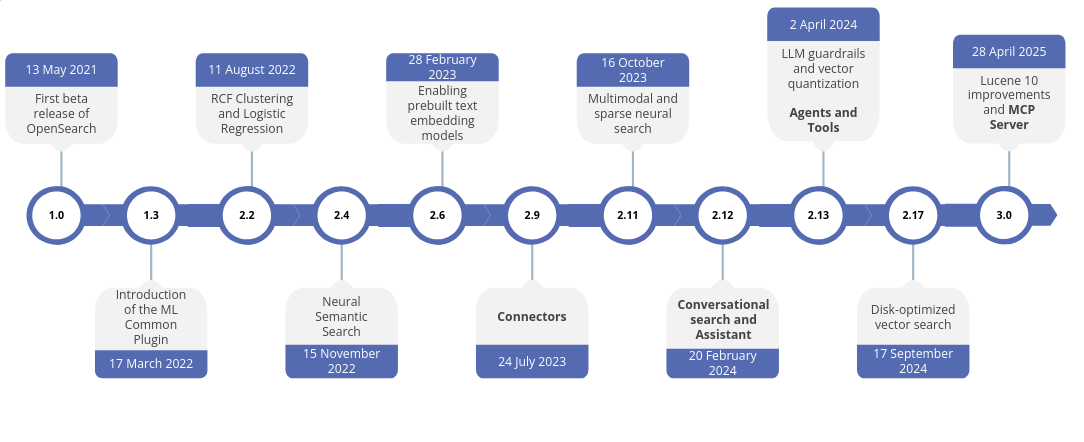
Among the latest innovations introduced in OpenSearch is the integration with an MCP server. Before diving into a practical, implementation-focused approach, let’s first take a closer look at what it is.
When large language models first appeared, many hastily predicted the extinction of search engines, assuming they could be replaced outright. Yet, limitations soon emerged: hallucinations, lack of verifiable sources, and the need for continuously updated information made it clear that search still plays a crucial role.
It was precisely in this context that RAG (Retrieval-Augmented Generation) was born.
RAG systems effectively combine the best of both worlds: on one hand, they leverage the remarkable generative capabilities of models trained to produce text, and on the other, they harness the power of search engines to retrieve relevant information, allowing responses to be grounded in a precise and reliable knowledge base.
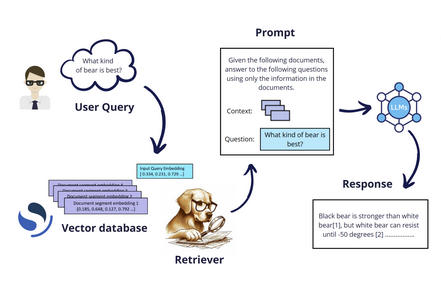
However, over time, needs emerged that went beyond the capabilities of a standard RAG system, revealing its inherent limitations. For instance, consider the need to perform cross-referencing across multiple knowledge bases to enable comparisons. With a traditional RAG system, this type of search is impossible, as it is constrained to a single retrieval phase.
What we need for this kind of query is a system that can make decisions, refine them iteratively, and perform comparisons. We need an agent, or perhaps a fusion between an agent and a RAG: an agentic RAG.
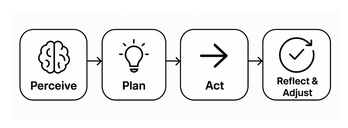
To act as an agent, the LLM has to:
make decisions, choose whether additional actions are necessary before answering the user
use tools, interact with the environment
iterate, evaluate progress and make adjustments
maintain context, recall past steps
To develop Agentic RAG, one of the most popular approaches is “tool calling." The idea is to provide the LLM with a set of tools it can invoke when needed to answer a user’s query. Each tool is typically defined by a name, a description, and a set of parameters. This technique is similar to the ReAct framework, but can be seen as a more structured and evolved version of it.
This approach enabled LLM providers to develop a wide range of specific connectors that linked their models to various services—for example, a connector for Gmail, one for Slack, another for Notion, and so on.
However, it quickly became clear that something was wrong. Since each provider had to build a dedicated connector for every single service, the number of connectors (or APIs) multiplied exponentially, 10, 100, even 1,000 different connectors for each LLM. And all this, despite the fact that LLMs essentially spoke the same language.
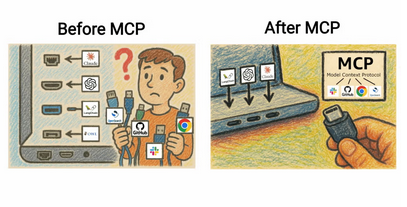
At the end of 2024, Anthropic introduced a solution: a protocol for implementing APIs, a standardized way to describe, build and use each tool. MCP was born.
Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
MCP follows a client–server architecture, where an LLM (or any AI application using one) establishes connections to one or more MCP servers through the instantiation of multiple MCP clients. On the server side, functionalities are exposed and their implemenation follow the standardized protocol. Here an example:
{
"name": "searchFlights",
"description": "Search for available flights",
"inputSchema": {
"type": "object",
"properties": {
"origin": { "type": "string", "description": "Departure city" },
"destination": { "type": "string", "description": "Arrival city" },
"date": { "type": "string", "format": "date", "description": "Travel date" }
},
"required": ["origin", "destination", "date"]
}
}
For example, in a travel-planning application, a large language model can use this tool to search for flights and assist the user in booking a vacation at the best available price. This functionality is available to any AI application that implements an MCP client, independent of the underlying LLM.
Since its introduction, MCP has been adopted by many organizations across different fields, including WhatsApp, Notion, GitLab, Spotify, Amazon, and many more.
You can find the full list here: MCP Servers on GitHub.
Of course, OpenSearch is among them.
OpenSearch introduced agents and tools with the 2.13 release on April 2, 2024, a few months before MCP was introduced.
To use OpenSearch standard tools, we only need to define an agent. Many generic tools are already implemented and ready to use. Among them are tools for performing searches (lexical or semantic), tools for operating within the cluster (such as the List Index Tool, which performs a _cat/indices), and even tools for searching the internet.
We can use these tools within a flow or conversational flow agent, in cases where we want the tools to run in a specific order. In this short demo, I will be using a plan–execute–reflect agent, which is another type of agent that allows the LLM to make decisions and choose which tool to call.
You can see it like an intelligent orchestrator.
To start with tools, first thing we need to do is to register our large language model.
Therefore, we need to:
POST /_plugins/_ml/model_groups/_register
{
"name": "remote_model_group",
"description": "A model group for external models"
}
POST /_plugins/_ml/connectors/_create
{
"name": "My openai connector: gpt-4",
"description": "This allow us to connect an external llm to the cluster",
"version": 1,
"protocol": "http",
"parameters": {
"model": "gpt-4o"
},
"credential": {
"openAI_key": "sk-proj-****"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://api.openai.com/v1/chat/completions",
"headers": {
"Authorization": "Bearer ${credential.openAI_key}"
},
"request_body": "{ \"model\": \"${parameters.model}\", \"messages\": [{\"role\":\"developer\",\"content\":\"${parameters.system_prompt}\"},${parameters._chat_history:-}{\"role\":\"user\",\"content\":\"${parameters.prompt}\"}${parameters._interactions:-}]${parameters.tool_configs:-} }"
}
]
}
{
"name": "gpt-4o",
"function_name": "remote",
"model_group_id": "FrX4w5gB0MsRGuywoXJN",
"description": "Remote models for demo",
"connector_id": "IbX6w5gB0MsRGuyw3XKD"
}
Once you have done this, you can use your model through the model_id. You can retrieve it just after the registration or from kibana dedicated overview on deployed or connected models.
Finally, we can define the agent:
POST /_plugins/_ml/agents/_register
{
"name": "My Plan Execute Reflect Agent",
"type": "plan_execute_and_reflect",
"description": "Agent for dynamic task planning and reasoning",
"llm": {
"model_id": "LbX7w5gB0MsRGuywtHKV",
"parameters": {
"prompt": "${parameters.question}"
}
},
"memory": {
"type": "conversation_index"
},
"parameters": {
"_llm_interface": "openai/v1/chat/completions"
},
"tools": [
{ "type": "ListIndexTool" },
{ "type": "SearchIndexTool" },
{ "type": "IndexMappingTool" }
],
"app_type": "os_chat"
}
The agent allows the large language model to decide whether it needs to retrieve information from the available tools to answer the user’s query. In this case, it is important to provide a limited set of tools to ensure the LLM only performs the actions we intend; too many tools can lead to incorrect behavior.
In this case, the available tools are:
Note that we are using a conversation_index memory, which means that each iteration will be stocked into a dedicated index.
To test our agentic rag, we only need to use the following command:
POST _plugins/_ml/agents/ZbUExJgB0MsRGuywRXLY/_execute?async=true
{
"parameters": {
"question": "How many indices in my cluster and what do they contain?"
}
}
I prefer to run it asynchronously since we don’t know how much time the LLM will take to iterate through the tools to provide an answer.
Starting from version 3.0, MCP has been available in two flavors:
About MCP internal server, since it is integrated into OpenSearch, we need to activate it before using it:
PUT /_cluster/settings/
{
"persistent": {
"plugins.ml_commons.mcp_server_enabled": "true"
}
}
Note that this command is slightly different in version 3.0.
Once MCP internal server is actived, it will be necessary to register tools, which can be done directly through the endpoint:
POST /_plugins/_ml/mcp/tools/_register
Indeed, as the server is started, no tool will be registered. You can verify this through the _list endpoint:
GET /_plugins/_ml/mcp/tools/_list
This is not the case for the MCP external server, which comes with tools we can directly use, such as ListIndexTool, IndexMappingTools and SearchIndexTool. You can see the list of available tool inside the logs of your mcp server.
INFO - GET https://opensearch-node01:9200/ [status:200 request:0.018s]
Connected OpenSearch version: 3.0.1
Applied tool filter from environment variables
Available tools after filtering: ['ListIndexTool', 'IndexMappingTool', 'SearchIndexTool', 'GetShardsTool', 'ClusterHealthTool', 'CountTool', 'MsearchTool', 'ExplainTool']
We’ll save this topic for the next blog, where I’ll demonstrate how to implement a custom function in the OpenSearch MCP server and how to use connectors to link the OpenSearch cluster with the MCP server.
The evolution from traditional search to RAG and now to Agentic RAG demonstrates how far we’ve come in combining large language models with reliable, structured information retrieval. By integrating OpenSearch with MCP, we gain a standardized, scalable, and flexible way to connect LLMs with multiple tools and data sources, enabling more intelligent and autonomous behavior.
Agentic RAG empowers LLMs to plan, execute, and reflect on tasks, iterating across tools while maintaining context. This approach not only mitigates the limitations of standard RAG systems but also opens the door to more sophisticated use cases, whether it’s cross-referencing multiple knowledge bases, performing dynamic analyses, or integrating seamlessly with external services.
With OpenSearch 3.x and MCP, developers now have a robust framework for building these advanced, decision-making AI systems. As we continue exploring this ecosystem, the possibilities for intelligent search and automation are virtually limitless.