
Haystack est une conférence sur l'amélioration de la pertinence des moteurs de recherche.

La recherche par mots clés repose sur un index inversé contenant des mots ou groupes de mots employés pour caractériser un document. La recherche vectorielle est basée sur un modèle de réseau neuronal qui interprète des objets et les traduit en vecteurs. Cela permet de trouver des éléments avec des significations similaires. On peut décrire une recherche vectorielle à l’aide de 2 notions fondamentales : l’espace de recherche vectorielle et la pyramide de recherche vectorielle. L’espace fournit une base concrète à la recherche pendant que la pyramide apporte une grille de lecture. Elle applique à la recherche vectorielle une représentation en 6 étapes.
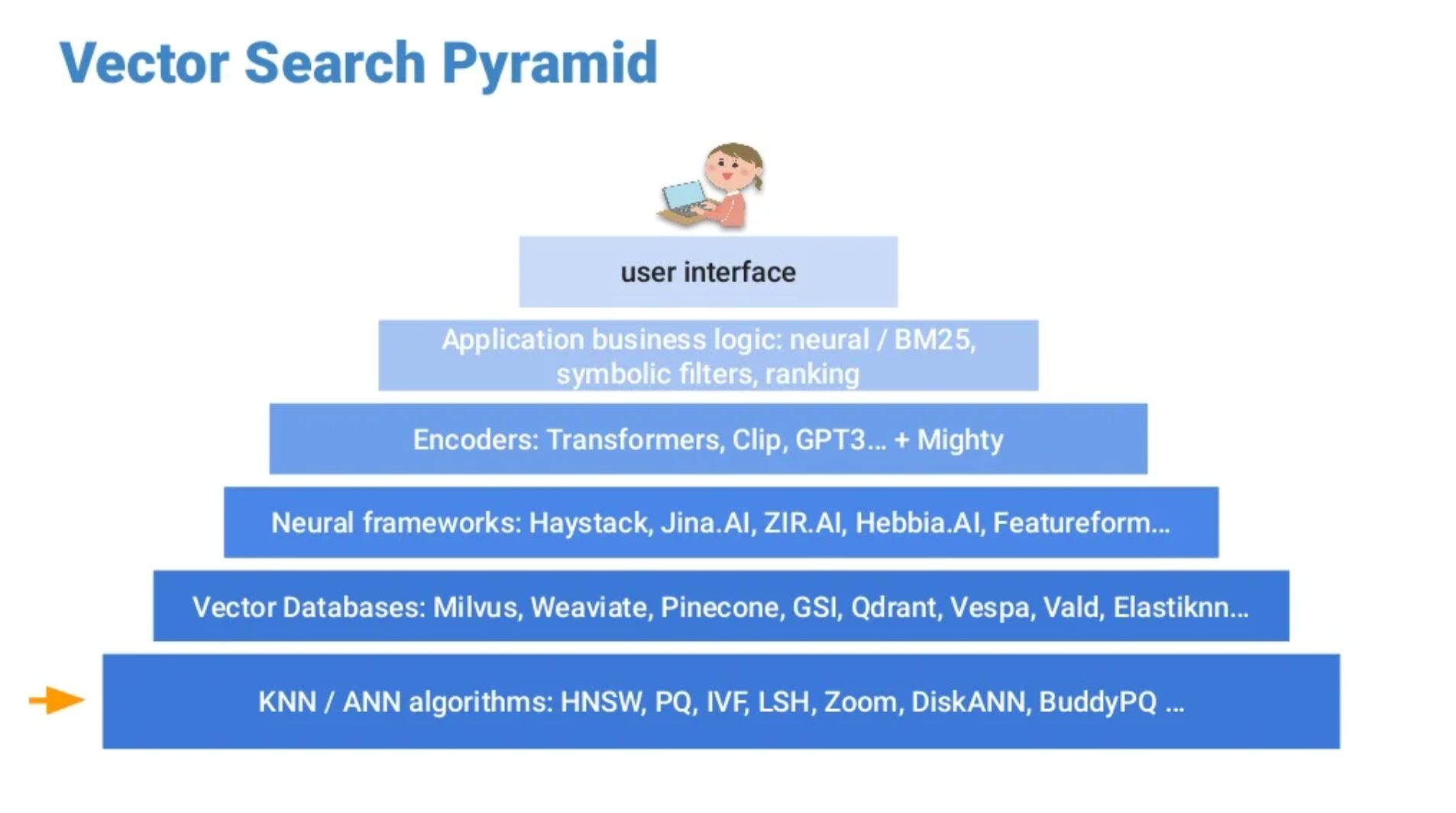
Depuis le bas vers le haut : algorithmes, bases de données vectorielles, structure neuronale, encodeurs, logique métier d’application, interface utilisateur.
Il est utile de rappeler que dans le cadre de la recherche vectorielle,
la correspondance repose principalement sur 2 paramètres :
la similarité et la proximité du vecteur d’interrogation avec les vecteurs déjà enregistrés.
Les algorithmes RNA (réseau neuronal artificiel) sont utilisés pour produire des systèmes.
La quantification de produit (QP), un processus d’approximation, permet de réduire l’usage en mémoire d’un vecteur.
La QP peut être améliorée en lui affectant différentes stratégies (combinaisons, structures en arborescence, pré-rotations ou encore généralisations).
Le système de recherche par index inversé peut lui aussi être amélioré et notamment la distance d’estimation.
La recherche par mots clés est basée sur un paradigme lexical. La recherche vectorielle introduit un nouveau paradigme : un paradigme contextuel de recherche. Il peut surmonter certaines lacunes lexicales (US vs USA vs United States) Il respecte l’ordre des mots. Il tient compte des relations entre les termes. Il offre un environnement favorable pour les recherches multimodales, multilingues, ou même pour des méthodes hybrides. À l’avenir, la recherche va probablement opérer un rapprochement vers les data sciences, mais cela ne saurait se faire sans explorations, sans tentatives, sans mettre les mains dans le cambouis.
La recherche vectorielle ne viendra vraisemblablement pas se substituer à tout ce qui existe. Nous pouvons déjà constater son implémentation au sein de solutions qui ont fait leurs preuves. La plupart du temps, la recherche vectorielle viendra probablement s’ajouter en complément. Plus ponctuellement elle pourrait occuper le devant de la scène dans des secteurs spécifiques.
La conférence commence par une image : “le temple de la recherche sémantique” et ses 2 piliers, ses 2 composants principaux : la base de données vectorielles et le modèle d’intégration. Actuellement les modèles pré-entraînés dominent le champ du Machine Learning. De gros modèles comme BERT ont besoin d’adaptations pour répondre aux besoins spécifiques d’un projet. La mise au point s’impose pour les classifications. On peut ajouter une simple couche linéaire à la suite d’un gros modèle et opérer une mise au point sur cette couche.
Pour modifier un modèle pré-entrainé : Premièrement, pour adapter le modèle à son nouveau domaine, on doit collecter des données.
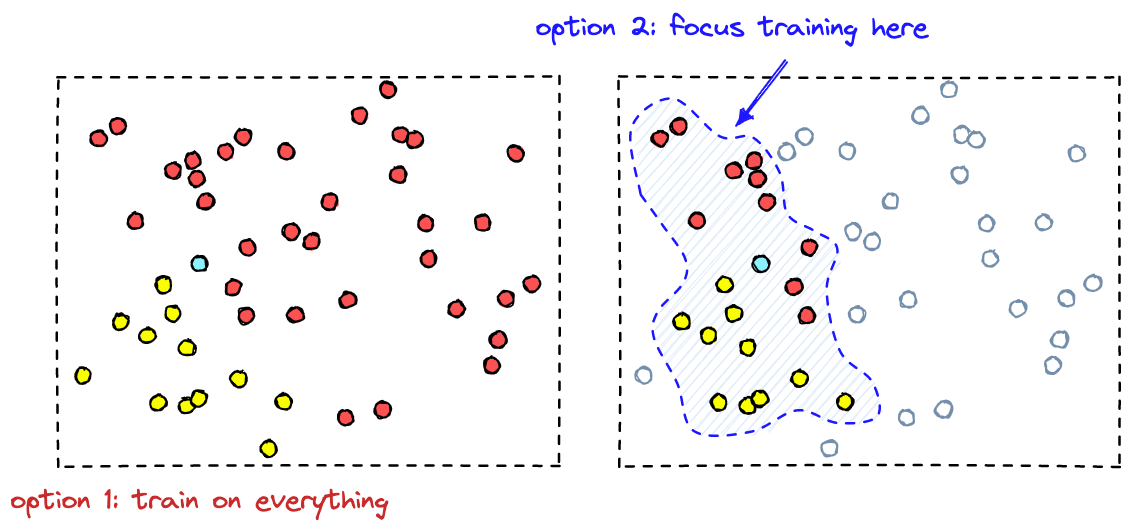
Le plus souvent, on recueille un très grand volume de données. En regroupant les vecteurs par proximité, on peut mettre l’accent sur des échantillons très représentatifs qui permettent d’optimiser les performances de classification.
On parcourt ensuite l’ensemble des données en les étiquetant. Enfin, il reste à faire la mise au point.
Une mise au point implique une classification linéaire avec des vecteurs. Le classifieur doit apprendre à s’aligner sur les vecteurs que nous avons étiquetés comme positifs, et à s'éloigner de ceux que nous avons étiquetés comme négatifs.
Les différentes techniques sont présentées en suivant le schéma ci-après : contexte - techniques disponibles - exceptions - traitement.
Techniques disponibles :
Techniques d’optimisation :
La dimension subjective fournit une clé importante dans le domaine de la recherche. “Le référencement n’est pas (que) de la recherche mais…” Le Machine Learning suppose un projet dans le long terme, de partir de zéro, des ressources, un risque élevé,… La recherche vectorielle se heurte plus ou moins aux mêmes contraintes en l’absence d’outils adéquats.
Tout ce dont on a besoin : un historique de navigation.
Ensuite, en s’appuyant sur les données, Metarank peut les mapper à une fonctionnalité de Machine Learning et entraîner le modèle de Machine Learning choisi. Ainsi Metarank fournit un service open-source hautement personnalisable. La solution fonctionne aussi pour ajouter une dimension dynamique au référencement.
Il utilise des métadonnées (comme le prix des éléments , les tags,…), les impressions et les interactions. Metarank emploie une simple API et une configuration en YAML. Le mécanisme se compose de 4 étapes : il compile, il rejoue l’historique en entier, il définit des jugements implicites, il produit un nouveau modèle de référencement.
Le défi consiste à produire un référencement pertinent qui ne soit pas une “boite noire”. Le client a besoin de pouvoir mesurer et comparer la pertinence à l’aide de scores.
Une liste de jugements définit la pertinence d’un document pour une requête donnée. La liste est composée par 2 types de jugements : explicites (comme dans le cas d’une recherche) et implicites (comme dans le cas d’un événement). Il devient possible d'évaluer la pertinence d’une liste de résultats à l’aide de différents indicateurs : précision moyenne, les avantages cumulés avec réduction (DCG), les avantages cumulés avec réduction normalisés (NDCG),…
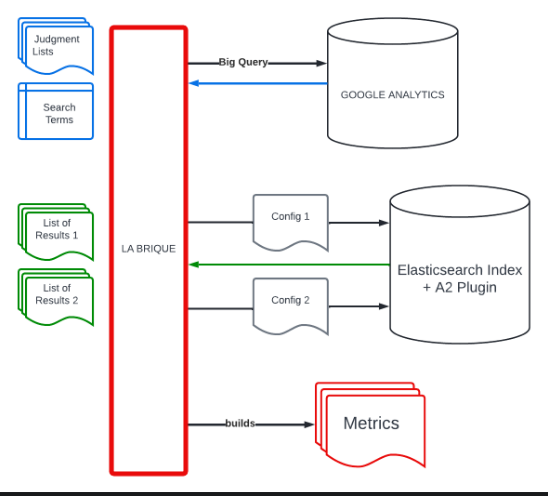
Une équipe non technique d’utilisateurs configure le moteur de recherche à l’aide d’une Business Console. Les utilisateurs ont besoin d’un outil pour tester les résultats et garantir la non-régression en cas de modification. Les données changent constamment, ce à quoi s’ajoute un besoin très spécifique d’interprétation (par exemple, dans un cadre alimentaire, la consultation des détails liés à un produit n’est pas considérée comme un marqueur positif contrairement à un cadre non alimentaire).
(Demo)

Lorsqu’on emploie l’intégration neuronale, on peut travailler avec des vecteurs de deux manières : par similarité et par proximité. En général, on a recours à l’apprentissage par similarité lorsque la recherche textuelle ne suffit pas, dans le cas ou la recherche porte sur des images par exemple. Plus spécifiquement, la recherche par similarité s’avère très utile dans le contexte du machine learning. En regardant de plus près la structure des réseaux, on rencontre des difficultés.
Les modèles pré-entraînés ne fournissent pas une intégration très satisfaisante alors même qu’un modèle original est le plus souvent très spécialisé. On a donc besoin de pouvoir modifier un modèle pré-entraîné pour pouvoir l’adapter à un contexte nouveau. C’est à ce moment qu’intervient la nécessité d’une mise au point. On emploie pour ce faire la classification et la régression. Classification ou régression s’appuient sur la similarité.
L’entraînement lié au Machine Learning requiert un très gros volume de données. Une fois remplie cette condition, une ancre, des exemples positifs et négatifs,… les outils sont assez basiques. On n’a pas besoin de beaucoup plus, mais de temps à autre, on rencontre un problème pour réduire certains vecteurs. On peut surmonter cette difficulté de deux manières en employant la similarité ou bien la proximité. On emploie pour ce faire une évaluation par groupe ou bien par paires. Les obstacles font partie du jeu, mais on cherche à éviter à tout prix les oublis catastrophiques, ceux qui nous feraient repartir de zéro.
Recherche sémantique :
Extrême classification - catégorisation de produits e-commerce L’extrême classification est un domaine en forte croissance. Le Machine Learning y est appliqué à des problèmes de classification et labels multiples concernant un très large volume de labels.
Women Of Search est un groupe Slack dont la vocation est d’offrir un lieu sûr et sans jugement, un lieu de partage. La création de ce groupe s’appuie sur une observation, laquelle révèle un problème de sous-représentation des femmes dans le domaine de la recherche(search).
Le manque de diversité est un problème connu dans l’ingénierie logicielle. On peut y remédier aisément en adoptant une démarche la plus inclusive possible.
Pour améliorer nos comportements, il est important d’informer et de rester conscients de nos modèles sociaux, souvent vecteurs de biais comme le sexisme, le syndrome de l’imposteur ou encore la “falaise de verre” (en anglais “glass cliff”).

En pratique, nous devrions veiller à éviter les inégalités qu’il s’agisse des salaires, des promotions, … Et il est très important de surveiller, de mesurer les résultats de nos efforts en ce sens.
Lorsque l'équipe s’est lancée dans l’e-commerce, son point de départ concernant les bases de données était loin d'être optimal. Elle a commencé par gérer les données “manuellement”, sans résultat très satisfaisant. Elle a fini par avoir une sorte d'épiphanie : “le client a toujours raison”.

L'équipe avait un atout de taille, ses clients sont très particuliers : fidèles, réguliers, dotés d’une forte intention d’acheter et maîtrisant la dimension technique des produits.
Moins évident, l’absence de code préexistant a joué un rôle important, cela supposait un effort pour bien cerner les besoins métier. Ce qui a permis à l'équipe d'élaborer la stratégie suivante. En premier lieu, observer le comportement des clients. Extraire ensuite des enseignements de ces observations. Incorporer enfin ces enseignements dans la recherche.
L'équipe a érigé un modèle basé sur la collecte d'événements rassemblés en sessions courtes et elle a appliqué des indicateurs comme le NDCG (Normalized Discounted Cumulative Gain) pour ajuster un score. Ces courtes sessions ont mis en évidence des modèles comportementaux. Pour traiter ces informations, l'équipe a utilisé des tuples pour associer recherches et événements afin de pouvoir produire un score d’interaction.
L'équipe a complété le processus pour obtenir la configuration suivante :
événements (récupérés par le frontend depuis le plus simple événement jusqu'à la requête la plus complexe)
-> sessionizer(pipeline)
-> evaluateur/indicateurs
-> platform de données.
Finalement, les données sont prêtes pour l’agrégation, les mesures ou le mapping.
OTTO est une immense marketplace. Ses ingénieurs ont commencé à tester le référencement neuronal, en d’autres termes, ils utilisent des réseaux.
Ils ont élaboré une méthode basée sur la concordance sémantique. Cet encodeur est essentiellement une combinaison de 4 fonctionnalités qui se traduisent dans un design en 4 étapes : un tokenizer, un modèle d’intégration, un flux de travail mutualisé et un réseau profond. Malheureusement, la concordance sémantique n’est pas un gage de pertinence. Pour surmonter cet obstacle, une solution répandue consiste à employer une fonctionnalité complexe appelée Learning To Rank (LTR)
Les techniques de Machine Learning sont utilisées pour apprendre des retours utilisateurs quels résultats de recherche sont pertinents ou non. Pour cette tâche, ils appliquent un modèle de référencement en 4 étapes : on génère un contexte, on entraine un réseau, on étiquette des données manuellement et on collecte des retours implicites. À ce moment intervient la partie problématique ; en les passant à la loupe, ces retours implicites s’avèrent biaisés. Le biais le plus flagrant est un biais de position. Les éléments positionnés le plus en haut sont plus visibles et reçoivent ainsi plus de click quelle que soit leur pertinence effective.
Le problème s’accentue encore un peu lorsqu’on ajoute un entrainement au click. Un meilleur référencement recevra implicitement plus d’attention et donc davantage de clicks. Il existe plusieurs moyens pour pallier à un biais de position. Dans ce cas précis, on doit minimiser l’impacte sur l’expérience utilisateur. La solution retenue a été l’apprentissage du référencement (LTR) non biaisé depuis les données de click. Cet apprentissage peut s’obtenir de différentes façons, ici ils ont opté pour l’Inverse Propensity Weighting (IPW).
Donc, d’un côté, on doit calculer la pertinence, et d’un autre côté, il faut encore produire un indicateur de performance qui mesure le rang du document pertinent. Pour que la méthode fonctionne, on a recours à 2 entrainements séparés. On termine en combinant les deux résultats obtenus pour obtenir ce fameux référencement neuronal non biaisé.
Position Bias Estimation for Unbiased Learning to Rank in Personal Search