
Retour sur la présentation "De la voix au texte, la puissance de l'écosystème Open Source", donnée à la conférence OSXP (Open Source Experience) par Lucian Precup et Aline Paponaud: lien de l'enregistrement vidéo et résumé des idées présentées.
En novembre dernier nous étions à la conférence Open Source Experience qui ouvrait ses portes pour sa première édition. A cette occasion, nous avons présenté l'écosystème Open Source autour des technologies Speech-To-Text. Plus tôt cette année, lors de la conférence Berlin Buzzwords, nous présentions notre approche pour améliorer les technologies Speech-To-Text avec la technologie Elasticsearch : Speech to text with Elasticsearch. OSXP était pour nous une occasion pour généraliser la présentation, et aussi partager notre expérience en français :-).
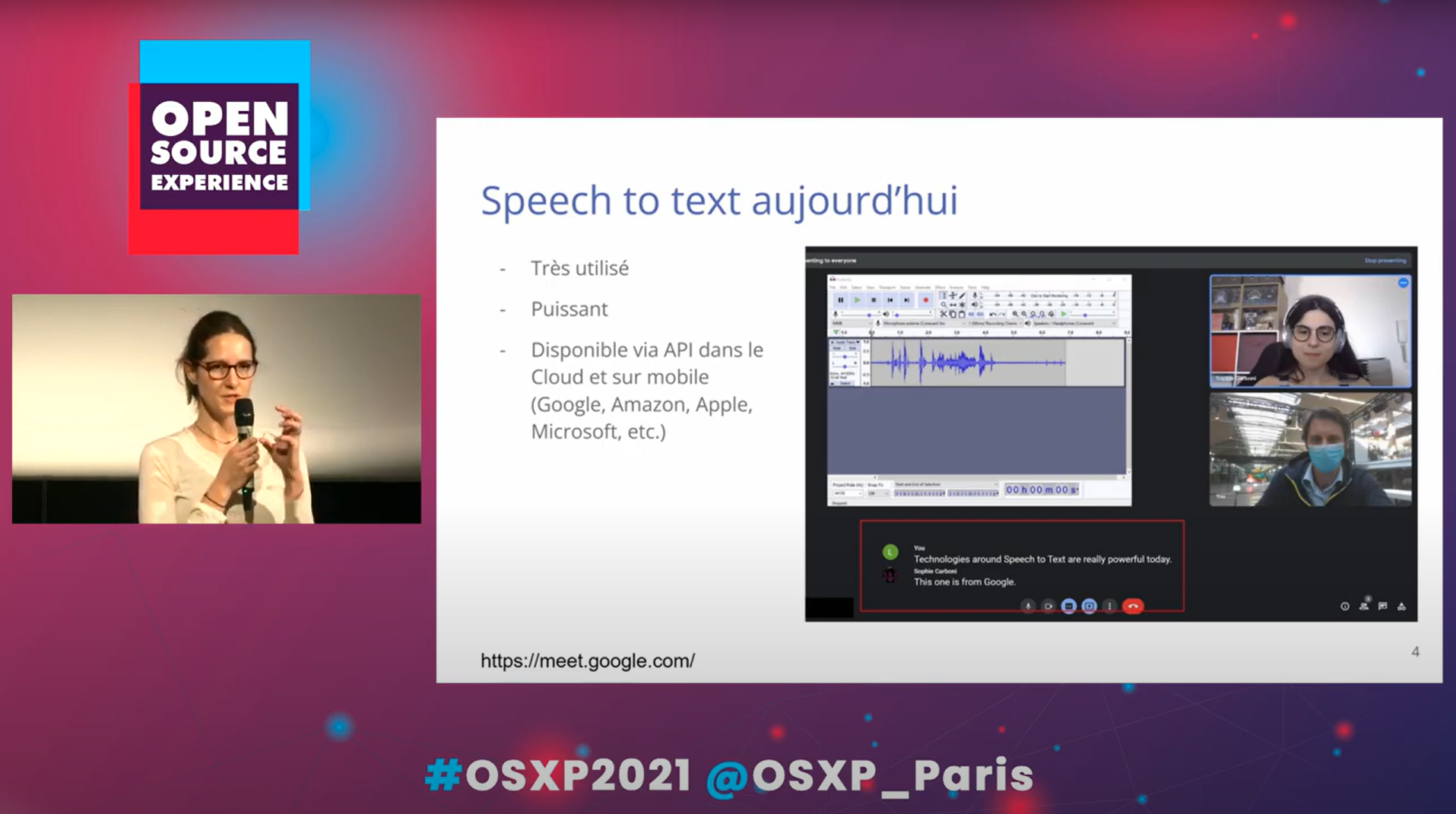
Le Speech-To-Text (STT) a beaucoup évolué notamment grâce au Machine Learning et au Deep Learning. Cette technologie est disponible partout via des APIs dans le Cloud et chez les opérateurs tels que Google, Apple, Facebook, Amazon, Microsoft, etc. Souvent, tout se passe côté serveur : la voix enregistrée ou les contenus média sont téléchargés vers les nuages des opérateurs en question et interprétés à distance.
Une certaine dépendance à la plateforme est également introduite car souvent ces fonctionnalités sont disponibles uniquement pour leur écosystème respectif.
L’Open Source a enregistré beaucoup d’avancées ces trois dernières années. Il y a de plus en plus de bibliothèques Open Source tel que Kaldi (sous licence Apache) qui fournit des modèles, des algorithmes et des recettes qui peuvent être utilisées dans les applications, même offline. Vosk une bibliothèque sous licence Apache fournit également un support supplémentaire pour des langues et langages de programmation. La référence historique dans l’Open Source, CMU Sphinx, a laissé la place aux nouvelles technologies, motorisées par des techniques Machine Learning.

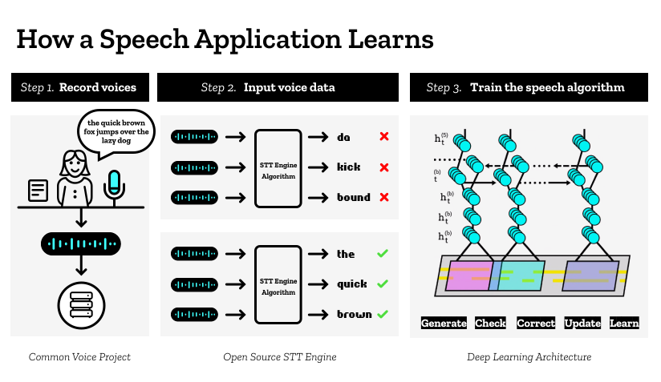
Mozilla est à l’initiative de Common Voice un projet intégrant des technologies Deep Learning (Deep Speech). A la différence d’autres technologies collectant les données de ses utilisateurs, le projet Common Voice fonctionne sur un modèle opt-in : c’est vous qui décidez de donner votre voix ou votre temps à la communauté afin de faire avancer la technologie. Concrètement, vous pouvez aller sur le site de Common Voice, lire un texte ou écouter et valider sa transcription.
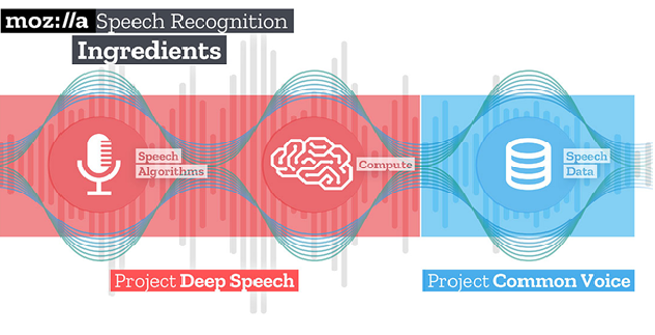
Le principe des approches Deep Learning est l’apprentissage successif : la technologie Speech-To-Text génère des propositions, les vérifie, les corrige, met à jour les paramètres et apprend. Une large quantité de données est nécessaire pour assurer l’apprentissage et la qualité du modèle d’où l’appel à la communauté.
La technologie Vosk Api, qui est la plus avancée parmi les technologies Open Source à l’heure actuelle, peut transcrire les phrases qu’on lui dicte en temps réel. Et ceci offline à l’aide des modèles entrainés ne nécessitant pas beaucoup de ressources. Notre démonstration utilise des modèles ne dépassant pas 50 Mo pour le français ou pour l’anglais. Les extensions sont possibles et nous montrions une approche pour transcrire des textes parlés en plusieurs langues.
Nous avons identifié plusieurs cas d’usages des technologies Speech-To-Text : la transcription de texte, l’indexation de contenu audio et vidéo dans un moteur de recherche, la documentation de podcasts, l’accessibilité des conférences et la reconnaissance de requêtes dans le contexte d’un assistant vocal.
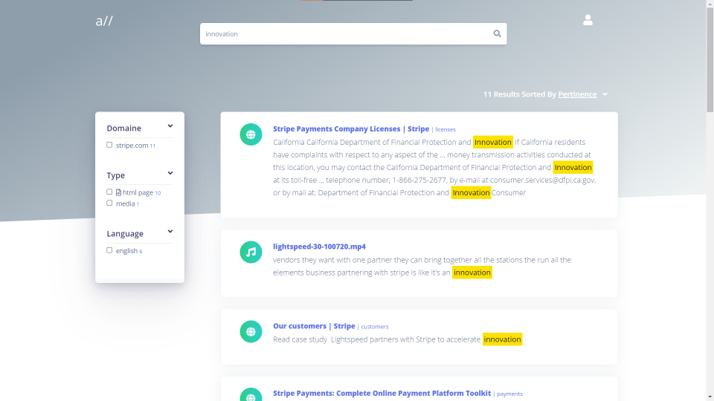
Nous finissions notre présentation avec une démonstration des technologies Speech-To-Text Open Source dans le contexte du moteur de recherche collaboratif all.site. Le contenu disponible sur Internet mais aussi dans les Intranet des entreprises est de plus en plus parsemé de contenu multimédia. Dans le cadre des formations en ligne particulièrement, le contenu média peut dépasser la moitié des ressources disponibles. Les technologies comme Vosk Api, permettent aux explorateurs (crawlers) de all.site d’aller au-delà du contenu des fichiers texte et des métadonnées des fichiers média en explorant et indexant le contenu des vidéos et pistes audio référencés.
Nous tenons à remercier les organisateurs, qui ont transmis la présentation en direct et le public qui nous a chaleureusement accueillis.

Vous trouverez ci-dessous l’enregistrement de la conférence disponible dans la vidéothèque d’OSXP 2021.
La vidéo : De la voix au texte, la puissance de l'écosystème Open Source